XGBoost Overview
XGBoost는 gradient boosting 방식을 기반으로 decision tree들을 모아서 형성된 algorithm이다.
Decision tree의 node는 feature를 기반으로 test를 수행해서 test의 outcome을 branch로 나누고, leaves형태로 model의 output을 확보한다. model이 classifier이라면 leaf는 label을 가질것이고, regressor이라면 real number를 가질것이다.
Decision tree는 다음과 같이 function으로 표현될 수 있다.
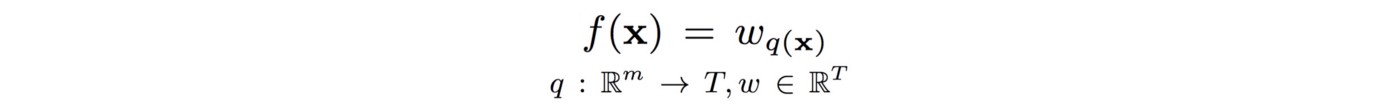
Function f는 tree의 root로부터 leaf까지의 path를 기반으로 weight w를 assign한다. 이런 decision tree가 K개가 있다면, final output은 하나의 leaf에 associate된 weight가 아닌, 여러 leave에 associate된 sum of weights가 될것이다.
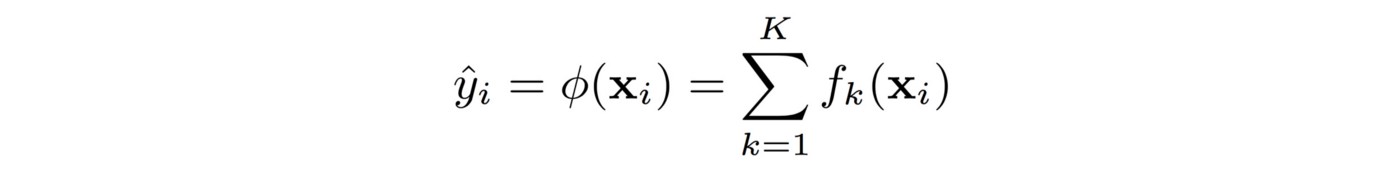
여러개의 tree로 형성된 ensemble model을 구현할때에는 algorithm이 data를 학습하면서 a new function (a new tree)가 더해진다. 여기에서 over-fitting 또는 very complex structure를 방지하기위해 다음과 같이 두개의 term으로 error로 define한다.
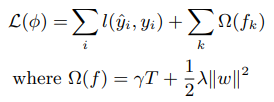
first one: that scores the goodness of the model obtained at the k-th iteration
second one: that penalises complexity both in the magnitude of the weights associated to the leaves and in the depth and structure of the developed tree.
위와 같은 공식을 regularized learning objective function이라고 한다. Traditional gradient tree boosting에 over-fitting방지를 위해 regularization term이 더해진 형태이다.
Shrinkage and column subsampling
regularized objective 외에 두개의 additional techniques가 더 확실하게 over-fitting을 방지하기 위해 사용된다.
- shrinkage
After each step of tree boosting, shrinkage는 newly added weights를 factor of η(eta)로 scale한다. Stochastic optimization에서 learning rate의 역할과 비슷하게, shrinkage는 individual tree가 전체 model에 주는 영향을 reduce해주고 앞으로 model을 개선해갈 future trees를 위한 공간을 확보해준다.
more details on this technique introduced in Friedman’s paper (Stochastic gradient boosting (J. Friedman, 2002))
column(feature) subsampling
commercial software TreeNet에 구현되어있는데, user feedback을 보면 column sub-sampling이 traditional row sub-sampling보다 더 over-fitting을 잘 방지한다고 한다. 또한, computation of parallel algorithm을 더 빠르게 수행할 수 있도록 돕는다.
Split finding algorithms
tree learning에서의 중요 문제 중 하나는 best split을 구하는 것이다. (다음과 같은 objective loss function을 minimize하는 split을 찾아야함.)
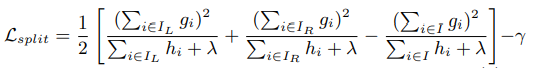
Basic exact greedy algorithm
최적의 split을 찾기위해, a split finding algorithm enumerates over all possible splits on all the features, so its computationally demanding. 이런 방식을 “exact greedy algorithm”이라고 하며, most existing single machine tree boosting implementation(scikit-learn, R’s gbm, single machine version of XGBoost)들이 exact greedy algorithm을 지원한다. 더 효율적인 computation을 위해 feature values를 기반으로 data를 sort해서 sorted된 data를 visit하여 위 objective loss function을 기반으로 structure score를 위한 gradient statistics를 accumulate해 나아간다.

Approximate Algorithm
dataset이 너무 커서 memory에 entirely fit하지 못하는 경우, (또는 distributed setting에서 computation이 진행되어야하는 경우), exact greedy algorithm을 efficient하게 수행할 수 없다. 이런 경우 approximate algorithm이 필요하다.

1) algorithm first proposes candidate splitting points according to percentiles of feature distribution 2) algorithm maps the continuous features into buckets split by these candidate points, then aggregates the statistics and finds the best solution among the proposals based on the aggregated statistics
이 algorithm에는 두가지 variants가 있다 - global and local (depending on when the proposal is given) Global variant proposes all the candidate splits during the initial phase of tree construction and uses the same proposals for split finding at all levels. 반면, local variant re-proposes after each split. local proposal이 split이후 candidates를 더 refine해준다. (potentially more appropriate for deeper trees) Local proposal require fewer candidates and global proposals can be as accurate as the local one given enough candidates
XGBoost를 훈련하는 과정은 매번의 step마다 best possible split을 찾고 이를 반복한다. It finds the best possible split for the k-th tree enuemrating all the possible structures still available at that point in the path. 가능한 모든 split의 enumeration은 매우 exhaustive하기 때문에, approximate 방식으로 진행이 되는 것이다. The approximate version doesn’t try all the possible splits, but enumerates just the relevant ones according to the percentiles of each feature distribution.
XGBoost algorithm은 single machine setting을 위한 exact greedy algorithm외에도 local/global proposals method와 함께 approximate algorithm도 지원한다. Users can choose between the method according to their needs.
Weighted Quantile Sketch
Approximate algorithm에선 candidate split points를 propose하는 것이 중요하다. Candidate split points를 propose하기위해서는 feature의 percentile을 사용해서 candidate들이 data에 even하게 distribute되도록 한다.
다음 criteria를 기반으로 split point를 찾는다.
An approximation factor ε를 설정해서 (such that there is roughly 1/ε candidate points), 이를 기준으로 rank function r을 define한다. rank function은 각 training instance들의 feature value들과 second order gradient statistics로 define된다. rank function이 다음과 같은 조건을 만족하도록 candidate split points {s_k,1, s_k,2, … s_k,l}를 찾는 것이 목적이다.
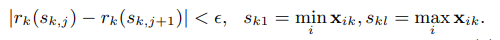
![]()
Large dataset에서 candidate splits를 찾는것은 매우 어려운 일이다. 모든 training instance들이 equal weights를 가지고있다면, “quantile sketch”를 활용해서 해결할 수 있지만, quantile sketch 방식 소개 자료 1 ,quantile sketch 방식 소개 자료 2,
Weighted datasets에는 적당한 quantile sketch방법이 없었는데, 이 논문에서 a novel distributed weighted quantile sketch algorithm을 솔류션으로 소개했다. (can handle data with provable theoretical gaurantee) 해당 algorithm의 general idea는 certain level of accuracy를 유지할 수 있도록 merge와 prune operations를 지원하는 data structure을 propose하는 것이다.
Handling missing values in split finding
현실세계의 dataset은 sparse dataset일 경우가 많다. algorithm이 dataset내에 존재하는 sparsity pattern을 인식하도록 이 논문에서는 “default direction”을 each tree node에 추가했다. Sparse matrix x dptj missing value가 있는 경우에는, 해당 instance를 “default direction”으로 classify하는 것이다. (e.g., if a sample’s feature value is missing and a decision node splits on that feature, the path takes the default direction of the branch and the path continues down to the next node.)
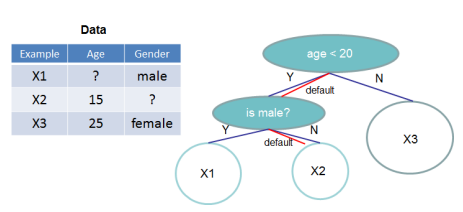
각 branch에는 two choices of default direction이 존재한다. Algorithm은 data를 통해 the “optimal” default directions를 학습한다. 여기서 가장 중요한 point는 Algorithm 3에서 보이는 바와 같이 algorithm이 non-missing entries I_k만을 visit하는 것이다.
하나의 feature set I가 주어졌다면, all possible splits가 enumerate되고 corresponding loss가 계산될것이다. 이때 corresponding loss가 한번이 아닌 두번 계산된다 - loss for each default direction(which the missing values for that feature can take)가 추가되는 것이다. The best of the two is the best default direction to assign when splitting according to the value j of the feature m. 여기에서 computed score를 maximize하는 split이 best split으로 결정된다. (The best split is still the split that maximizes the computed score, but now a default direction is attached.)

XGBoost는 모든 sparsity pattern들을 하나의 unified 방식으로 처리한다. 또한, sparsity dataset을 기반으로 수행되는 computation의 속도 또한 dense dataset을 기반으로 수행되는 basic algorithm 보다 50배 이상으로 빠르다는 장점이 있다.
단점으로는, sparsity-aware split finding 방식이 whole sample을 기반으로 best split을 판단하지 못한다는 것이다. This approach only gaurantees that on average taking the default direction leads to the best possible result given the already traversed splits. This doesn’t gaurantee that the already traversed splits (possibly solved by taking a default direction) were the best ones considering the whole sample. Samples들의 missing value percentage가 증가할수록 built-in strategy의 성능이 떨어질 가능성이 크다.
“The default direction is the best possible choice given that it reached the current position, but there is no gaurantee that the current position is the best situation possible considering all the features of the current sample.”
XGBoost as an Interpretable Model
Python XGBoost interface에는 각 feature의 importance를 graph로 표현해주는 plot_importance()함수가 있다. plot_importance() 함수에는 “importance_type” parameter를 다음과 같이 3 가지 attribution methods 중 하나를 설정하여 feature importance를 확인할 수 있다:
- weight(default): number of times a feature is used to split the data across all treees
- cover: number of times a feature is used to split the data across all trees weighted by the number of training data points that go through those splits
- gain: average training loss reduction gained when using a feature for splitting
어떤 attribution method를 설정하느냐에 따라서 다른 feature importance결과를 얻을 수 있는데, 이 중 어떤 feature attribution을 참고해야하는지 비교하기가 쉽지않다. 참고한 medium blog에서는 “good” feature attribution method를 선정하기위해서는 다음과 같이 두가지 properties를 고려해야 한다고 한다:
- consistency - model이 특정 feature에 더 의존하게되도록 model 변경시, 해당 feature의 attributed importance가 감소되어서는 안된다. (e.g., 만약 두개의 model들이 consistency 조건을 만족하지 못한다면, 이 두 model간의 attributed feature importance를 비교할 수 없다. b/c then having a higher assigned attribution doesn’t mean the model actually relies more on that feature.)
- accuracy - 모든 feature importance 값들의 합은 model의 total importance값과 동일해야 한다. (e.g., if importance is measured by the R^2 value, then the attribution to each feature should sum up to the R^2 of the full model. If not, we cannot know how the attributions of each feature combine to represent the output of the whole model.)
Consistency & accuracy of the attribution methods
다음 두 가지 사항으로 “importance”를 정의하여 consistency를 확인할 수 있다:
- change in the model’s expected accuracy when a set of features is removed
- feature들이 model에게 끼치는 global impact를 표현
- change in the model’s expected output when a set of features is removed
- feature들의 indivisualized impact on a single prediction
attribution method인 weight, cover, gain은 모두 global feature attribution method들이다.
Consistency를 확인하기위해 다음 5 가지 feature attribution methods를 활용할 수 있다.
- Tree SHAP - 새로운 individualized method
- Saabas. An individualized heuristic feature attribution method.
**mean( Tree SHAP ).** A global attribution method based on the average magnitude of the individualized Tree SHAP attributions. - Gain. The same method used above in XGBoost, and also equivalent to the Gini importance measure used in scikit-learn tree models.
- Split count. Represents both the closely related “weight” and “cover” methods in XGBoost, but is computed using the “weight” method.
- Permutation. The resulting drop in accuracy of the model when a single feature is randomly permuted in the test data set.
여기서 사용되는 Tree SHAP은 consistent하고 accurate한 method이다. 이 방법은 fair allocation of profits를 기반으로한 game theory proof를 통해서 특정 feature attribution 방식의 uniqueness를 보장할 수 있다. details on NIPS paper
shap python package를 통해서 Tree SHAP 방식을 통한 feature importance를 구하고 graph할 수 있다.
References
- XGBoost: A Scalable Tree Boosting System (T. Chen, 2016)
- https://medium.com/towards-data-science/interpretable-machine-learning-with-xgboost-9ec80d148d27
- https://towardsdatascience.com/xgboost-is-not-black-magic-56ca013144b4