Machine Vision for Metaverse
Overview
Metaverse = Meta (가상, 초월) + Universe (세계)
“Metaverse is about the steady dematerialization of physical space, distance and objects.”
Metaverse는 3D graphics로 구현된 virtual space만을 의미하지 않고, physical world에서 인식되는 공간, 거리, 객체의 현실적인 가치와 기능이 실제 material 없이 지속적으로(특정 제한이나 한계 없이) 구현되는 것을 의미한다.
Metaverse platform의 구성
기능 관점에서 7 계층의 설명:
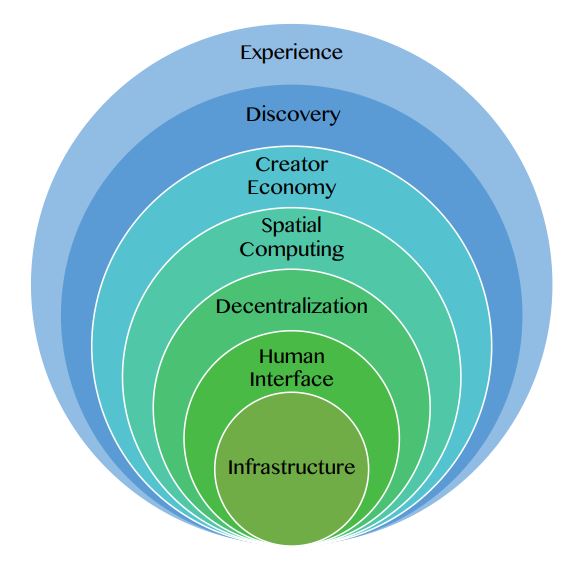
Experience: games, social, E-sports, shopping, festivals, events, learning, and working
Physical 거리를 dematerialize하는 체계. 즉, 기존에는 경험하기 어려웠던 것들이 훨씬 더 accessible하고 경험하기 쉬워진다. 특히, game 분야에서 physical 거리의 dematerialization이 잘 구현된다. 누구나 game 속에서는 원하는 환경에 들어가서 원하는 캐릭터가 되고 원하는 일을 체험해볼 수 있다.
Physical distance의 dematerialization으로 일상 생활이 더 자유로워 질 수 있다. Distance의 제한 없이, 집에서 공연 관람, 쇼핑, 회의 참석, 등을 경험 할 수 있다.
또한, 사용자가 virtual space에서 제공되는 contents를 소비하는 것만이 아니고, 직접 contents를 만들거나 또는 사용자들간의 상호작용 자체만으로 새로운 contents가 생성된다. 3D grpahics로 구현되는 “공간적 몰입” 뿐만이 아니라, 사람들간의 상호 작용, 대화, 공동체에서 생성되는 contents로 “사회적 몰입”이 구현된다.
Experience 관점의 service:
Beat Saver (VR game)
- Fortnite, Roblox, Rec Room (music concerts, immersive theater)
- Zoom (virtual meetings, conferences)
- Peloton (싸이클링)
- Clubhouse (다양한 사람들과의 대화)
Discovery: advertising networks, virtual stores, social curation, ratings, avatar, and chatbot.
지속적인 Push(Inbound) & Pull(Outbound)를 통해 사용자들을 새로운 경험으로 이끄는 체계. Virtual world에서 사용자가 어떤 정보와 경험을 추구할지는 커뮤니티와 타 사용자의 실시간 정보 및 현황으로 부터 큰 형향을 받는다.
이 체계의 요소들로 인해 가상 공간 속 사용자들의 “비동기 social networking”가 “실시간 social activity”로 변한다.
Inbound: 사용자가 능동적으로 정보/경험을 찾는 형태
real-time presence (실시간으로 지금 어디에 어떤 사람들이 모여있는지)
community-driven content (어떤 그룹의 사람들이 어디에 관심이 있는지)
app stores (applications의 reviews, ratings, categorization, tagging, etc)
curation (featured application listings, influencers’ 추천)
search engines, media
Outbound: 사용자의 요청이 없더라도 정보/경험이 사용자에게 보여지는 형태
display AD, spam
notifications
Creator economy: design tools, asset markets, E-commerce, and workflow
사용자가 immersive 3D virtual world에서 contents를 만들고 수익을 창출하는 체계. 직관적인 API, 간소화된 SDK, 초경량 웹어셈블리와 같은 여러 툴을 활용해 비 전문가의 콘텐츠 창작도 점점 용이해진다.
현존하는 platform들(Roblox, Rec Room, Manticore)에서는 creator들을 위한 full suite of tooling, discovery, social networking, monetization 기능이 제공된다. 사용자들이 쉽게 타 사용자들에게 새로운 경험을 제공할 수 있다.
Spatial computing: 3D engines, VR, augmented reality (AR), XR, geospatial mapping, and multitasking.
Physical world와 virtual world간의 barrier를 허문다. Spatial computing을 통해 3D 공간 속 몰입감을 향상시키고, 가상 세계에서 얻는 정보와 경험을 바탕으로 사용자가 실제 세계를 확장시킬 수 있도록 하는 체계.
Spatial computing의 주요 aspects:
- 3D engines to display geometry and animation (Unity and Unreal과 같은 3D creation tools)
- Mapping and interpreting the inside and outside world (geospatial mapping, object detection)
- Voice and gesture recognition
- Data integration from devices (IoT) and biometrics from people (e.g., health/fitness 분야)
- Next-generation user interfaces to support concurrent information streams and analysis
Decentralization: edge computing, AI agents, blockchain, and microservices.
Metaverse에서 개방과 분산을 구현하는 체계.
사용자들이 각자 creator가 되어서 자신의 data와 creation을 가지고 competitive market을 활성화시킨다. 이런 환경에서 사용자들에게 제공되는 option들이 최대로 다양해지고 가상 세계의 system이 하나의 entity가 아닌 여러 entities로 상호 운영된다. 이를 통해 다양한 실험과 빠른 성장이 가능해 진다.
Distributed computing과 microservices를 통해 사용자들이 system의 back-end integration에 관여하지 않고도 다양한 관점에서 system의 online capabilities의 발전에 기여할 수 있다.
Decentralization 구현 기술:
- blockchain, NFT: metaverse 세계 속 경험과 game들에서 필요한 value-exchange 구현
- edge computing: latency와 compuational complexity issue 해결
Human interface: mobile, smartwatch, smartglasses, wearable devices, head-mounted display, gestures, voice
사용자가 metaverse에 접근할 수 있게 연결해주는 hardware 제공.
Meta의 Oculus Quest: VR device + powerful computer
- 3D printed wearables integrated into fashion and clothing
- Miniaturized biosensors
Infrastructure: 5G, 6G, WiFi, cloud, data center, central processing units, and GPUs.
상위 계층의 기술이 구현될 수 있도록 디지털 장치의 활성화, 연결, 강화를 가능하게 하는 인프라 제공.
- networks: 5G and beyond
- computation chips: semiconductor (under 3nm process), microeletromechanical systems 기반 sensors,
- power: compact, long-lasting batteries
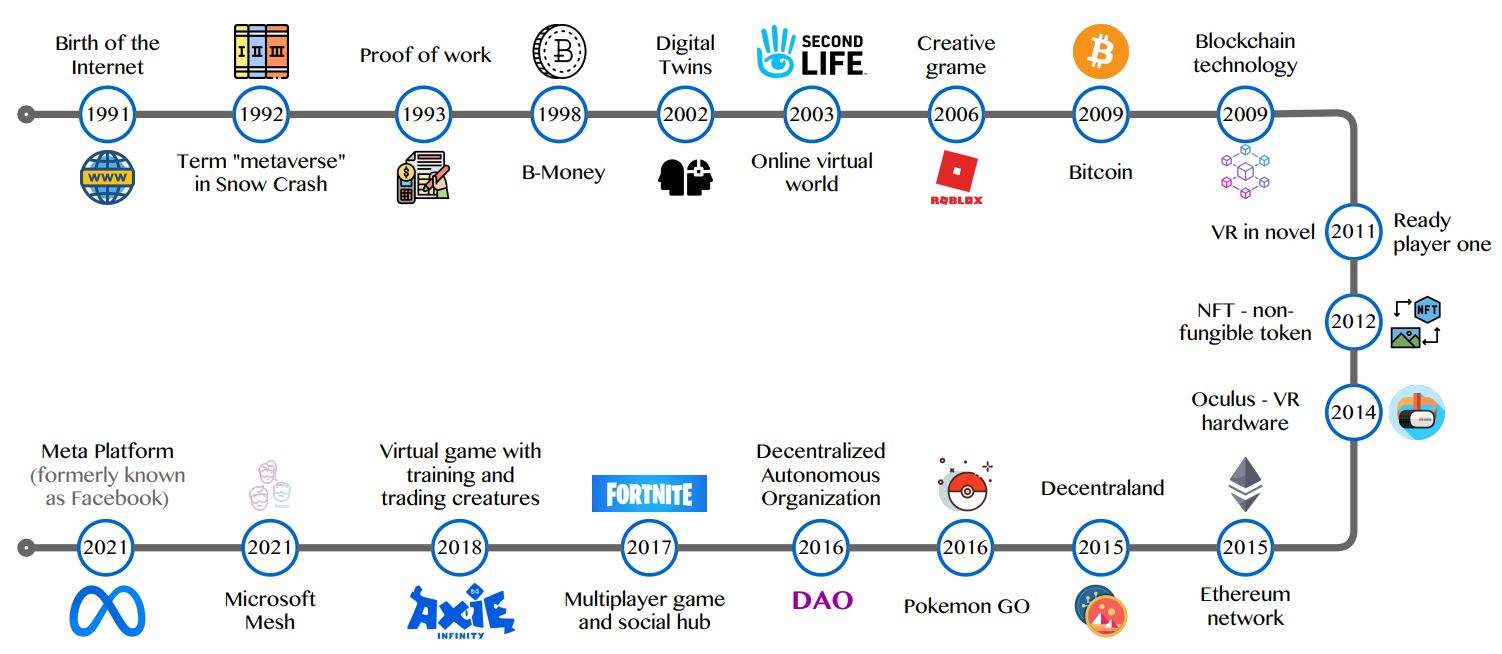
Metaverse의 timeline
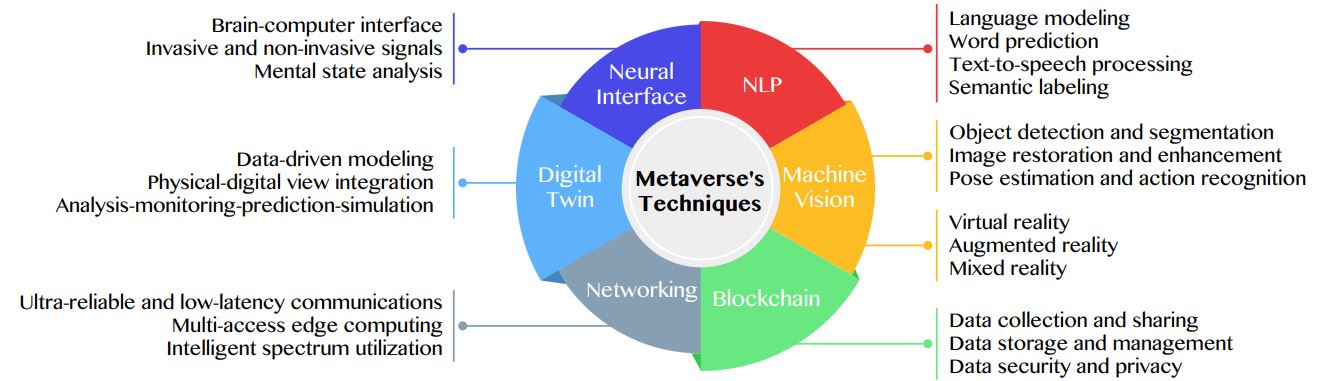
AI의 역할
다음 6 가지 분야에서 ML, DL algorithm 기반 AI 기술이 개발되고 metaverse services에 적용되어서, metaverse 사용자의 QoE를 향상시켜주고 있다.
각 분야 별 주요 tasks:
Vision AI
위 6 가지 분야 중 “Machine Vision”에 대한 내용이다.
AI 기술은 big data를 처리/학습하고 immersive experience와 virtual agents의 human like intelligence를 가능하게 하면서 metaverse의 발전에 크게 기여하고 있다. Vision AI는 computer가 image나 video를 이해하고 사람처럼 판단을 내릴 수 있도록 human vision system과 같은 기능을 구현한다.
(주요 내용이 bold 처리 되어있음.)
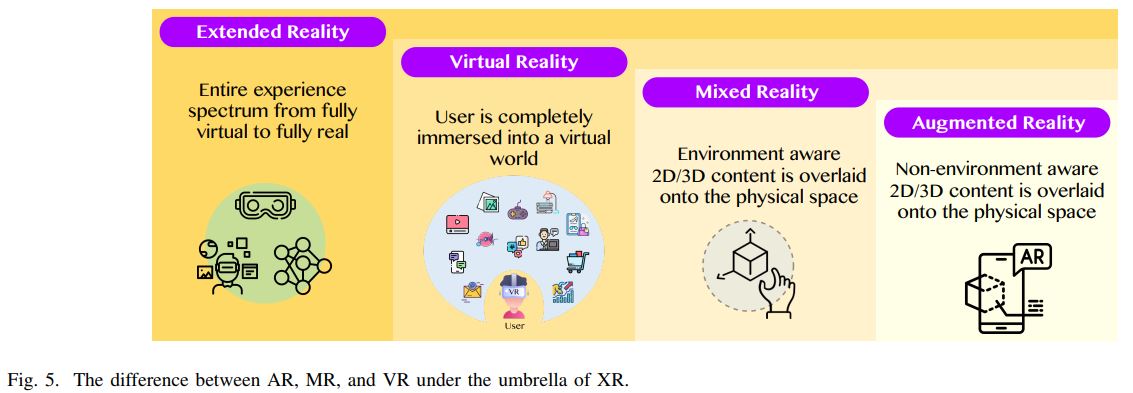
Extended Reality
Vision AI는 XR(extended reality)과 통합되어 metaverse에 활용되고 있다.
XR device들은 vision AI를 통해 의미 있는 visual-based 정보를 확보하고 사용자의 activities를 분석하고 이해한다. (e.g, 가상 세계의 3D space에서 avatar를 통해 사용자가 자유롭게 움직이고 metaverse object들과 interact할 수 있다.) Visual environments로 부터 얻은 raw data를 capture 및 process해서 head-mounted devices(e.g., smart glasses, smartphones)를 통해 사용자에게 전달한다.
“Reality” 기술은 다음 그림과 같이 설명된다. XR은 가장 넓은 범위로 VR, AR, MR(mixed reality), 그리고 이들 사이를 연결할 수 있는 다양한 기술들을 다 포괄적으로 의미한다.
VR: 사용자가 완전히 가상 세계에 들어간 상태의 viewing을 경험한다.
AR: 사용자가 실제 세계 (physical world)에서 graphics, video streams, holograms를 경험한다.
MR: 사용자가 AR과 VR 사이의 transition을 경험 할 수 있다.
사용자들은 실제 세계과 가상 세계에서 다양한 방식으로 제공되는 service들을 통해 metaverse를 경험할 수 있는데, XR과 AI 기술을 통합하면 사용자가 metaverse에 완전히 몰입하는 경험(“full immersion”)을 구현할 수 있다.
Human-machine interaction
VR device에 (visual-based information 기반의) AI 기술을 적용해서 human-machine interaction experience를 개선한다. VR에 AI가 접목된 분야는 gaming, working, shopping scenarios, 등 다양하다.
사용자들이 VR device를 통해 metaverse속 다양한 services와 applications를 사용하고 더 나아가서 가상 세계 속에서 hyperreal media contents를 만들어낸다. 다음과 같이 관련 연구 논문이 공유되어 있다:
- “Fixationnet: Forecasting eye fixations in task-oriented virtual environments,” (Hu, May 2021) : 가상 세계의 contents design과 rendering을 위한 “gaze-based applications” 분야의 논문. VR image, gaze data, head data와 같은 다양한 data를 학습해서 사용자의 eye fixation을 예측하는 multiple CNN기반 DL framework을 개발 함. 이 DL framework은 eye fixations과 other factors (likes VR content and headset motion)사이 correlations를 활용한다.
- “Human identification using neural network-based classification of periodic behaviors in virtual reality,” (Pham, Mar 2018) : 사용자와 VR gear들(e.g., controllers and head-counted displays) 사이의 주기적인 behaviors를 분석해서 human identification과 authentication을 구현할 수 있는 neural network를 개발 함.
- “Sensory-glove-based human machine interface for augmented reality (AR) applications,” (Zhu, Apr 2020) : 가상 세계에서 사용자의 quality of experience (QoE)를 개선하기위해 innovative한 솔루션들이 제안됨. (e.g., triboelectric sensory gloves and display components in VR devices를 활용해서 multi dimensional motion of gestures를 인식하고 ML/DL algorithm을 통해 VR/AR 세상속의 가상의 object를 작동한다.)
- “A new interactive haptic device for getting physical contact feeling of virtual objects,” (Kataoka, Aug 2019) : metaverse내 가상의 objects를 인식하고 사용하기위해 AR headsets외에도 다양한 device들이 개발되고 있다. (triboelectric gloves, hand-held touch screen devices, tabletops, etc.)
Video Quality Assessment
VR devices를 통한 고화질의 영상 viewing experiences를 구현하기 위해서는 효과적인 video quality assessment가 필요하다. DL이 quantitative & qualitative benchmark objective를 얻는데에 활용 될 수 있다.
- “Subjective and objective quality assessment of 2D and 3D foveated video compression in virtual reality,” (Bovik, Jun 2021) : Quality assessment를 2D와 3D foveated-compressed video에 적용 가능하도록 확장했다. (이를 통해 VR system이 효과적으로 limited data transmission bandwidth를 처리할 수 있다.)
- “Virtual reality video quality assessment based on 3D convolutional neural networks,” (Wu, Aug 2019) : 3D CNN architecture로 video reference 없이 VR quality를 판별하는 high-performance method를 구현할 수 있다.
- “3D panoramic virtual reality video quality assessment based on 3D convolutional neural networks,” (Yang, 2018) : handcrafted feature extraction기반으로 ML algorithm을 구현하는 방식보다 3D CNN-based approach가 더 성능 및 효율성 관점에서 superior함.
- “Accuracy analysis on 360 degree virtual reality video quality assessment methods,” (Han, Dec 2020) : 현재 video quality assessment method들의 장/단점과 status를 분석하고, AR system과 더욱 다각화된 video contents를 위한 효과적인 video transmission mechanism을 위해 필요한 조건들을 제안함.
MR (Mixed Reality)
MR은 physical과 digital world를 섞어서 3D human, computers, 그리고 surrounding environment간의 자연스럽고 intuitive한 interaction을 가능하게 한다. 다음 분야들의 획기적인 발전이 이를 가능하게 한다. “DVV: a taxonomy for mixed reality visualization in image guided surgery,” (Kersten-Oertel, Feb 2012)에서 논의 됨.:
- computer vision
- graphic processing
- display
- remote sensing
- AI technologies
AR 또는 VR 보다는 MR이 holographic devices과 immersive devices를 통해 virtual experience들간의 hybrid를 구현하는데에 더 적절하다. 그리고 미래에는 이 두 가지 device들이 specification이나 utility 관점에서 각각 다른 gap을 줄여 나가야 사용자들의 visual-interactive experience를 더욱 개선해 나아갈 수 있을 것이다.
- holographic device with see through display (allows users to manipulate physical objects while wearing it)
- immersive device (allows users to interact with virtual objects in the virtual world)
Computer Vision
다양한 network architecture의 DL에 대한 연구와 high-performance graphic processing unit을 기반으로 높은 정확도를 가진 visual system이 가능케 되었고, 이런 AI 기술을 통해 최근 computer vision 분야가 크게 발전해왔다. Computer vision의 근본 기술은 metaverse의 가상 세계에서 physical world와 virtual environment간의 상호 작용을 가능하게 하여 사용자 experience를 개선하는데에 매우 중요하다.
Computer vision domain의 두 가지 근본 task:
- semantic segmentation
- object detection
Semantic segmentation & object detection
semantic segmentation : Image내 각 pixel을 미리 정답으로 정의된 semantic class들로 분류한다. Semantic segmentation 구현을 위해 deep learning architecture이 다양하게 개발되고있음.
object detection: Input image에서 인식되는 객체를 표기하는 “bounding box”와 객체의 정보를 의미하는 tag를 통해 객체의 정보 및 위치를 파악한다.
- “Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs,” (Chen, Apr 2018) : Neural network의 parameter수를 적게, computational cost를 낮게 유지하면서 atrous convolution을 통해 receptive field of filter size를 키워서 feature 학습 과정을 개선 함.
- “Cross-attentional bracket-shaped convolutional network for semantic image segmentation,” (Hua, Oct 2020) : CNNs with channel-wisely and spatially attentional schemes.
- “Picanet: Pixel-wise contextual attention learning for accurate saliency detection,” (Liu, Apr 2020) : pixel-wise local & global attention pooling-convolution.
- “Visual and semantic knowledge transfer for large scale semisupervised object detection,” (Tang, Dec 2018) : CNNs with knowledge transfer via visual similarity and semantic relatedness. DL-based semi-supervised and unsupervised learning models를 활용하여 “unseen” classes에 대한 예측도 할 수 있도록 훈련을 진행 함.
- “Relation graph network for 3D object detection in point clouds,” (Feng, Oct 2021) : CNNs with 3D object-object relation graphs.
- “Structured knowledge distillation for semantic segmentation,” (Liu, Jan 2019) : pixel-level에서 classification model이 학습되어야하기 때문에 image segmentation은 보통 large memory, computation cost 이슈가 있다. 이를 해결하기 위해 새로운 network design이나 학습 기법을 조정하는 방법 중 하나로 “transfer learning” 기법을 개발 함.
- real & virtual object를 다 구별하려면 detect해야하는 object가 너무 많다. 그래서 CNN architecture을 조정하거나, DL 기반의 semi-supervised 또는 unsupervised 방식의 학습을 통해 학습데이터에는 없는 class를 구별 할 수 있게 하거나, advanced image processing 또는 depth sensing algorithm을 통해 “naural problems” (occlusion, illumination variation, view-point changes, 등)과 같은 이슈들을 해결할 수 있다.
- “Improved object detection with iterative localization refinement in convolutional neural networks,” (Cheng, Sep 2018) : CNN architecture를 조정해서 정확도와 processing speed를 개선 함.
- “3D object proposals using stereo imagery for accurate object class detection,” (Chen, May 2018) : Advanced image processing과 depth sensing algorithm을 활용해서 3D environment의 object detection을 방해하는 문제들 (occlusion, illumination variation, and view-point change)에 대응하는 방법.
- “Real-time panoramic depth maps from omni-directional stereo images for 6 DoF videos in virtual reality,” (Lai, Aug 2019) : geometric sensor를 통해 depth information을 추정할 수 있는데, 이런 추정 algorithm을 활용하여 object positioning의 정확도를 향상시킴.
Multi-scale image resolutions에서도 deep visual feature들을 추출할 수 있는 CNN이 주로 활용되고 있다. 관련 논문:
“Image segmentation using deep learning: A survey,” (Minaee, Feb 2021)
“Fully convolutional networks for semantic segmentation,” (Long, Oct 2015)
“Fully convolutional networks for semantic segmentation,” (Shelhamer, Apr 2017)
“STC: A simple to complex framework for weakly supervised semantic segmentation,” (Wei, Nov 2017)
“Unet++: Redesigning skip connections to exploit multiscale features in image segmentation,” (Zhou, Jun 2020)
Image restoration & image enhancement
사용자의 visual perception을 개선하기 위해 image의 quality를 떨어뜨리는 noise, blur, low-resolution과 같은 이슈들을 해결해야한다. Perspective image processing이나 computer vision 분야에서는 image restoration, image enhancement를 통해 visual perception 문제들을 해결할 수 있다.
- “Multi-scale deep residual learning-based single image haze removal via image decomposition,” (Yeh, Dec 2019) : deep residual structure U-Net이라는 learning frame을 사용해서 decomposed image components (a.k.a feature maps)를 개선 할 수 있다.
- 기존의 image enhancement 기법(e.g., histogram analysis, image decomposition, 등)으로 부터 발전하여서 최근에는 ML algorithm(특히, DL with CNN architecture)을 통해 image quality를 개선하는 기법들이 개발되었다.
- “An improved enhancement algorithm based on CNN applicable for weak contrast images,”(Wang, 2020) : convolutional down-sampling and up-sampling network으로 image들의 overall contrast 를 개선한다. Combination of deep features extracted by CNNs via a feature-based fusion scheme (deep features of RGB (reg, green, blue) channels are combined via a feature-based fusion scheme to obtain cross-channel contract balance.)
- “Image super-resolution using deep convolutional networks,” (Dong, Feb 2016) : fully convolutional neural network을 사용해서 low resolution image를 input하면 high-resolution image를 output할 수 있도록 light weight structure로 end-to-end learning 을 구현 함. Super-resolution 기법을 통해 low-resolution image/video sources로 부터 cost-efficient하게 high resolution virtual world를 만들고 제공할 수 있다.
- “Spatial and spectral joint superresolution using convolutional neural network,” (Mei, 2020) : Full 3D CNN architectures with simultaneous and separated spatial-spectral joint feature learning mechanisms.
- “AIPNet: Image-to-image single image dehazing with atmospheric illumination prior,” (Wang, Jan 2019) : CNN architecture를 활용하여 image compression artifacts를 감소시키고, downscaled 또는 blur된 image를 깨끗하게 복원한다.
- “A flexible deep CNN framework for image restoration,” (Jin, Apr 2020) / “Residual dense network for image restoration,” (Zhang, Jul 2021) : VR devices에서는 virtual contents와 real displayed images/videos간의 image quality 또는 video specification관점의 차이가 존재할 수 있다. 이런 경우, AI-empowered image restoration 기법들을 통해 gap을 매꿀 수 있다. 주로 사용되는 restoration methods:
- blur estimation
- hazy removal
- color correction
- texture rescontruction
- “Lightweight modules for efficient deep learning based image restoration,” (Lahiri, Apr 2020) : 만족스러운 실시간 metaverse service experience를 위해서는 real-time video processing speed에 적합한 computational complexity가 필요하다.
Human pose/action estimation
Metaverse에서는 사용자들이 그들의 avatars(i.e., virtual characters)를 제어하고, 타 사용자들 또는 non-player characters(NPC)들과 상호 작용해야 한다. 이 과정에서 character들의 posture과 action이 motion sensing interactive devices(e.g., controllers, gloves, cameras)를 통해 estimate되고 인식되어야 한다.
Human pose estimation은 body parts를 인식하고 이들을 실시간 환경에서 track한다.
“Human action recognition with video data: research and evaluation challenges,” (Ramanathan, Oct 2014) : 현실적으로 매우 복잡한 “cluttered” environment에서 human pose를 추정하기 어려운 문제를 해결하기 위해 다음 두 가지 discriminative models를 활용한다. Discriminative model들은 pose representation과 관련된 local features들 간의 correlation을 structural dependencies로 추출한다. Discriminative model들은 다음 요소를 기반으로 만들어진다.:
standard structural support vector regression SVR
latent structural support vector regression SVR
- “LCR-net++: Multi-person 2D and 3D pose detection in natural images,” (Rogez, May 2020) : CNNs with dense layer connection and channel-attention connection.
- “Hierarchical topic modeling with pose-transition feature for action recognition using 3D skeleton data,” (Huynh-The, May 2018) : Generative models with latent Dirichlet and Pachinko allocations.
- “Learning to acquire the quality of human pose estimation,” (Zhao, Apr 2021) : Body part localization을 정확도를 개선하고 varying view로 인한 이슈들을 해결 하기 위해, depth cameras로부터 얻는 depth information과 color information을 ML/DL model에 학습시킬 수 있다. CNN architecture에 다음 요소들을 활용하여 structural connection을 구현한다. Object occlusion과 같은 문제들을 해결할 수 있다.:
- dense layer connection
- skip connection
- channel attention connection
Action recognition은 개별적인 action과 complex interactive activities를 인식한다. (e.g., human-machine interaction and human-human interaction) Human pose estimation으로 capture한 body information을 활용해서 pattern recognition models를 통해 action을 identify할 수 있다.
- “Encoding pose features to images with data augmentation for 3-D action recognition,” (Huynh-The, May 2020) : Geometric feature transformation을 CNN architecture과 함께 활용. Action discriminative models의 학습 과정을 효과적으로 수행하기 위해, advanced CNN architectures 또는 hybrid CNN-RNN architecture가 활용된 innovative model들이 제안되고 있다.
“ML-HDP: A hierarchical bayesian nonparametric model for recognizing human actions in video,” (Tu, Mar 2019) : Instant posture를 detect하는 방식은 혼란을 일으킬 수 있다. 최근에는 instant posture 방식 대신에 long-term으로 temporal domain에서 body motion을 tracking하는 방식으로 action recognition의 정확도를 높이고 있다. 예를 들어 각각의 다른 body parts 사이의 spatio-temporal geometric features를 capture해서 human pose transition을 분석할 수 있는 statistical models가 개발되고 있다.
- “Beyond frame-level CNN: saliency-aware 3-D CNN with LSTM for video action recognition,” (Wang, Apr 2017) : DL을 활용하여 visual-based action recognition의 정확도를 높이고, 다수의 realistic single action들과 grouped activities를 효과적으로 처리할 수 있다.
그 외에도 hand gesture recognition, gait identification, eye tracking 기술이 활용되어 XR environment에서 interactive experiences를 경험할 수 있도록한다.
Applications
주요 application 분야는 4 가지 - healthcare, manufacturing, smart cities, gaming이고, minor 분야는 e-commerce, human resources, real-estate, de-fi(decentralized finance)이다.
각 분야 별 상세 응용 cases:
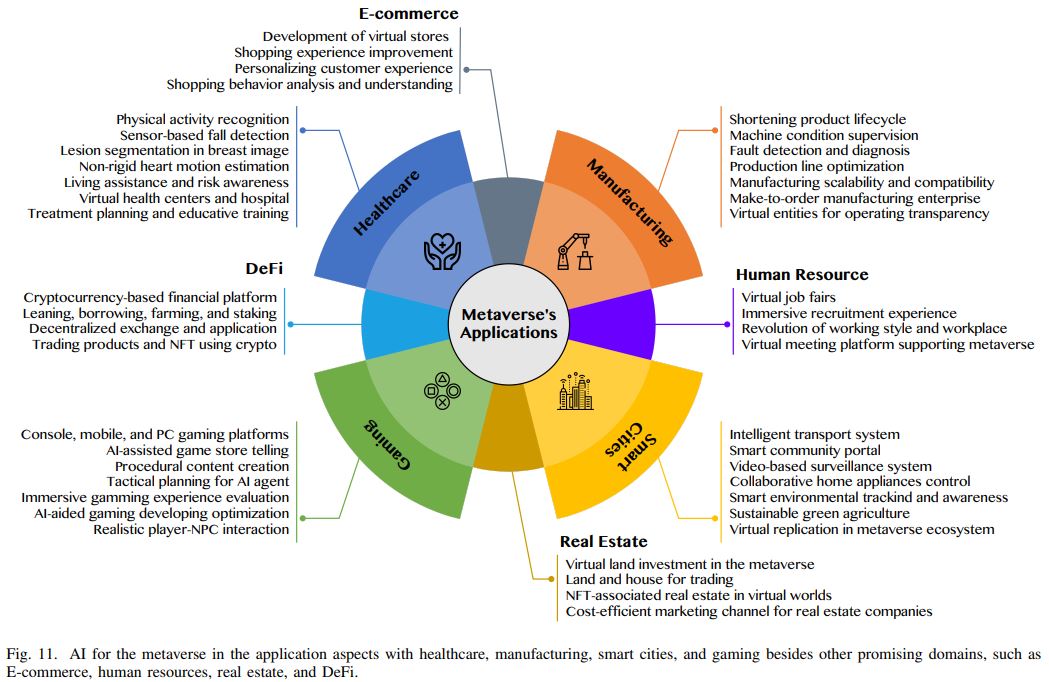
분야 별 AI techniques:
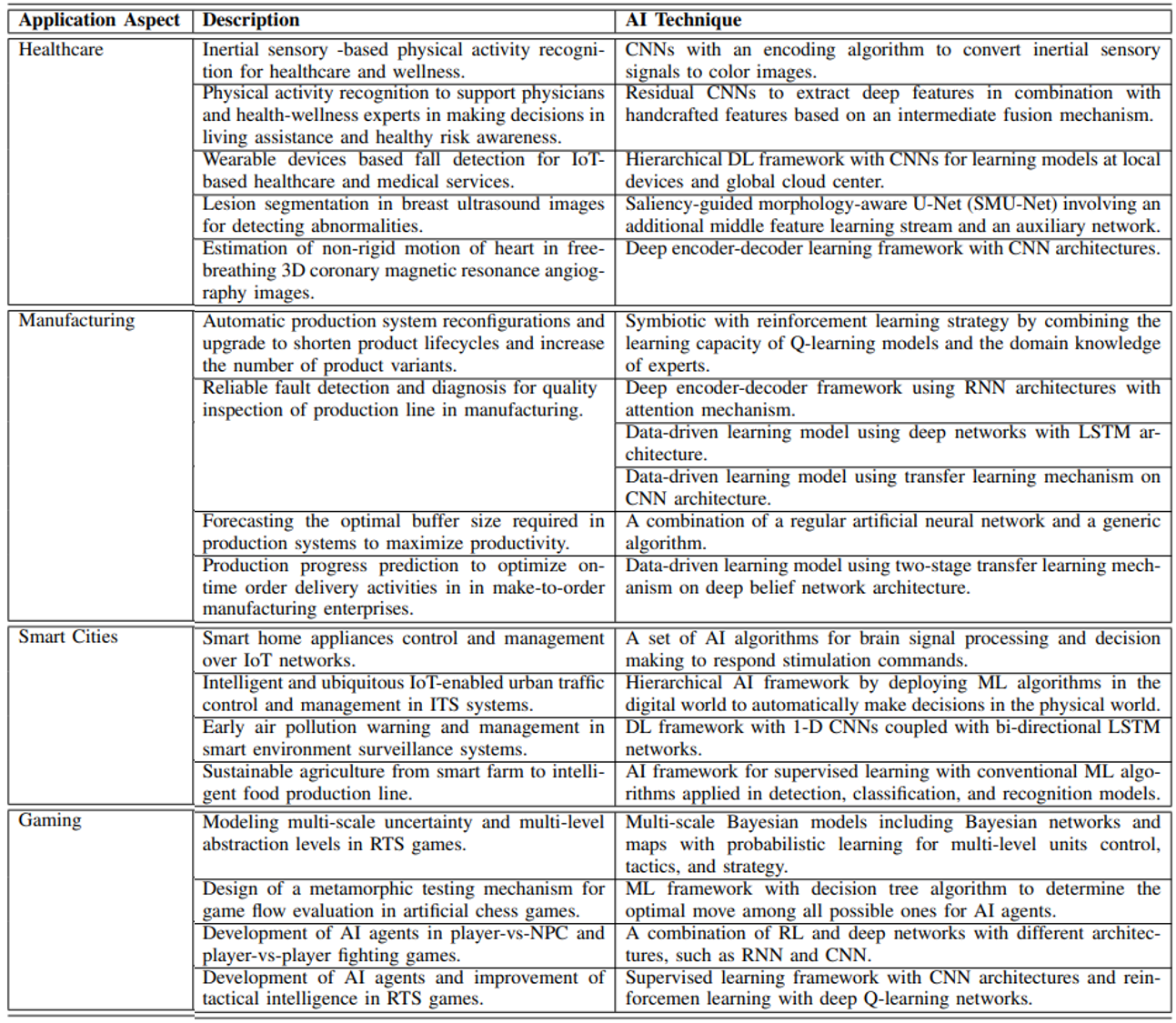
위 table의 상세 내용:
Healthcare
VR과 big data기반의 AI를 활용한 software & hardware를 사용해서 medical devices의 proficiency를 높이고 health service cost를 줄이거나, healthcare operations를 개선하고 medical care의 accessibility를 확장하고 있음.
VR/XR system이 발전하며, 2D environment에서부터 3D virtual world로 transition되고 immersive manner로 환자의 health condition이 관찰될 수 있다. 다음과 같은 healthcare operation이 개선된다:
- better efficiency in providing diagnosis
- delivering accurate and faster medical decisions
- providing better real-time medical imaging & radiology
- supporting more convenient simulated environment to educate interns and medical students
Healthcare and wellness application cases:
wearable devices: AI를 통해 sensory data의 complex pattern을 자동으로 인식한다.
- multiple wearable devices의 sensory data를 통해 환자의 physical activities를 인식하고 physician이 data를 바탕으로 daily living assistance 또는 early healthy risk awareness를 제공할 수 있다. globally handcrafted features + locally deep features의 통합 over an immediate fusion mechanism -> activity recognition rate의 개선
- Iss2Image: convert inertial sensory signal (e.g., accelerometer, gyroscope, and magnetometer) into a color image for CNN-based human activity classification. lightweight CNN with few layers in a cascade connection was designed to learn the physical activity patterns from encoded activity images.
- fall detection: cloud server의 데이터와 local device의 sensory data를 함께 사용. hierarchical DL framework with CNN architecture. Multiple wearable devices와 함께 사용됨. detection rate 높고, data privacy 또한 높음.
- CNN외에도 RNN, LSTM network을 통해서 wearable device의 sensory data를 통해 early health risk attention을 확인할 수 있음. e.g., fall detection, heart failure
medical image analysis: 숙련된 expert의 specialized knowledge가 필요한 task를 DL(특히, CNN architectures in image processing and computer vision domain)을 활용하여 수행 가능
saliency-guided morphology-aware U-Net(SMU-Net): additional middle feature learning stream and auxiliary network의 활용. coarse-to-fine representative features from the auxiliary network were fused with other features (e.g., background-assisted, shape-aware, edge-aware, and position-aware) to discriminate morphological textures.
cost-efficient unsupervised DL approach was introduced to accelerate the processing speed of non-rigid motion estimation of heart in free-breathing 3D coronary magnetic resonance angiography images. Replying on a deep encoder-decoder architecture, the network can learn image similarity and motion smoothness without ground truth information in a patch-wise manner to save computing resources significantly instead of a regular volume-wise manner.
3D image 속 complex pattern을 학습하는 CNN network에서 필요한 large network size와 computation complexity를 줄이기 위해 2D neuroevolutionary networks가 인용됨.
metaverse에서 여러 healthcare application들의 collaborative treatment 또는 educative training이 구현될 수 있음.
For example, medical students can improve surgical skills by doing interactive practice lessons built for medical education in the virtual world or patients can find some healthcare services via virtual assistants at virtual health centers and hospitals
Manufacturing
기존의 digital transformation을 통해 machine들과 system 사이의 연결을 향상해서 physical entities (e.g., machines, products, operators, etc)를 더 잘 이해하고 분석 할 수 있게되었음. 여기에서 더 발전해서 AI와 DT(Digital Twin)과 같은 기술을 적용하여 physical world로 translate될 수 있는 virtual world를 생성하고, digital operation을 modernize해서 physical world를 향상시키고 있음.
Through virtual entities in the metaverse, the industrial manufacturing efficiency is generally improved with AI to speed up production process design, motivate collaborative product development, reduce operation risk to quality control, and obtain high transparency for producer and customers.
quality inspection:
intelligent data-driven condition supervision 기술의 개발이 집중됨. 다양한 operating conditions, diversified tasks and application에 적용 될 수 있는 기술을 개발하는것이 어려움.
fault detection, diagnosis를 개발하기 위해 RNN과 CNN architecture 기반의 DL이 활용됨. real-time monitoring을 높은 정확도로 구현하는것이 목표임. RNN was developed with an encoder decoder structure coupled with attention mechanism to predict and diagnose interturn short-circuit faults in permanent magnet synchronous systems.
- a data-driven LSTM based fault diagnosis approach was introduced to early detect multiple open-circuit faults in wind turbine systems.
- DL-based intelligent fault diagnosis method was introduced to address two challenging problems, i.e., the lack of labeled data for learning model and the data distribution discrepancy between training and testing sets, by incorporating CNN architecture and transfer learning mechanism.
production line 최적화: 최적의 serial production line을 설계 및 구현해서 manufacturing process 전체의 productivity를 향상시킨다.
- prediction model to estimate the optimal buffer size in production line by combining a regular artificial neural network and generic algorithm.
- efficient production progress prediction method formulated with combination of DL and IoT - dynamic production과 on-time order delivery activities를 최적화함.
Smart cities
시민들의 needs를 해결하는데에 도움이 되는 data를 IoT, video cameras, social media,등 으로부터 확보하고 metaverse platform을 통해 “smarter interactive services”를 시민들에게 제공할 수 있다. By gathering big data from multiple authenticated sources, many administrative services can be provided and improved in the metaverse thanks to AI technology for data analytics,
- The environmental data (e.g., air quality, weather, energy consumption, traffic status, and available parking space) are fully replicated in the virtual world for user-friendly interface. ITS(Intelligent Transportation System), smart street light management systems, automatic parking systems, smart community portals, indoor/outdoor surveillance systems, utility payment, smart home control과 같은 service들이 metaverse로 만들어진 virtual world에서 제공 될 수 있음.
- 가전제품 제어: integrating EEG-based BCI, VR, and IoT technologies fueled by AI -> a steady-state visual evoked potential-based BCI architecture to collaboratively control home appliances.
- 교통 관리: intelligent and ubiquitous IoT-enabled architecture to control and manage urban traffic.
- 환경 오염 제어/관리: Air pollution warning과 forecasting을 위해, 1-D CNNs and bi-directional LSTM network을 통합한 DL architecture으로 multiple sensors로 부터 얻은 multivariate time series data를 분석하고 intrinsic correlation features를 추출한다.
Gaming
Metaverse의 주요 적용 분야이다. ML/DL이 적용되어서 PC, mobile, 등 다양한 platform 모두에서 gaming 산업내 큰 변화가 만들어졌다.
- NPC (non-player character)의 interaction with players’ actions : 사용자의 input에 대한 NPC의 response를 더 dynamic하게 resonable하게 구현할 수 있게 됨. 다음 topic들에서 AI와 CI (computational intelligence)의 역할이 중요함:
- NPC behavior strategy and learning,
- tactical planning,
- player repsonse modeling,
- procedural content creation,
- player-NPC interaction design,
- general game AI,
- AI-assisted game story telling,
- AI in commercial games
- 주로 사용되는 AI algorithms:
- decision making을 위해 - decision tree, fuzzy logic, Markov model, rule-based system, finite-state machine
- learning based tasks를 위해 - Naive Bayes, ANN, SVM, case-based reasoning systems
- real-time strategy (RTS) game에서 multi-scale uncertainty와 multi-level abstraction을 model하기 위해 - Bayesian models
- human-like response mechanism을 test하기 위한 metamorphic testing mechanism - decision tree models to reveal metamorphic relations, which in turn effectively determine the optimal move among all possible ones
- To address come inherent difficulties in real-time fighting games (pro players를 1:1로 이길 수 있는 AI agent 개발)을 위해 - combination of RL and deep networks, RL with supervised learning.
References
The Metaverse Value-Chain The Metaverse Value-Chain. Trillions of dollars are pouring into… by Jon Radoff Building the Metaverse Medium - Artificial Intelligence for Metaverse (IEEE, 2022)