Topic Modeling
Topic modeling:
비지도 학습 방식으로 model을 훈련하여 topic들을 모르는 상태에서도 document가 어떤 topic들에 matching 되는지를 구분하여 document들의 분류 또는 군집화를 수행 할 수 있다. Topic modeling은 각 document는 mix of topics이고, 각 topic은 mix of words라는 가정하에 구현된다 Document내 word들의 군집 또는 빈도수와 같은 pattern을 인식해서 topic들을 인지하는 것인데, 하나의 document에는 한 개 이상의 topic들이 존재할 수도 있다. Topic modeling은 다음 두 가지 output을 확보한다:
1) Topic을 기준으로 model이 grouping한 document들의 군집
2) Model이 word들간의 또는 document들 간의 관계를 찾아내기 위해 사용한 word들의 군집
Topic modeling을 통해 어떤 topic들이 존재하는지를 비슷한 또는 연관된 word들을 기반으로 찾을 수 있고, 이런 word들로 구성된 각각의 document들 속의 topic들의 분포를 표현할 수 있다. Topic modeling은 어떤 collection of documents 속에 숨겨진 themes/topics를 찾아고, documents를 발견된 theme으로 분류해서, collection 속의 내용을 요약, 정리, 또는 검색 하는 데에 유용하게 활용된다.
Latent Dirichelet Allocation
A. LDA(Latent Dirichlet Allocation): Topic modeling을 구현할 수 있는 알고리즘 중 하나이다. Document들을 구성하는 word들을 기반으로 topic을 구분하여 각 document안의 word를 알맞은 topic에 assign하고, 이를 통해 topic들에 document들을 mapping한다. LDA의 동작 원리는 document를 생성하는 방식에 기반되어 있다. 먼저 set of topics를 선택하고, 각 topic에 대해 set of words를 선택하여서 document를 생성하는 것이다. LDA 알고리즘은 위 과정을 반대로 진행하는 방식으로 topic들을 찾는다. 만약 M개의 document들이 주어지고, K개의 topic들이 존재한다면, LDA 알고리즘의 동작 방식은 Fig 1의 plate diagram으로 표현된다.
LDA 알고리즘 작동 방식을 표현하는 plate diagram:
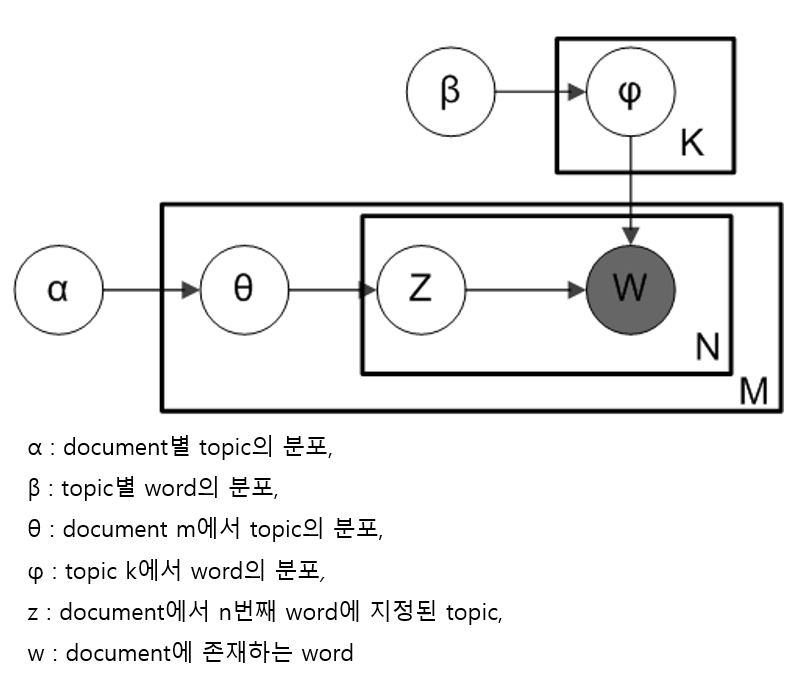
위 그림에서 word를 나타내는 W만 회색으로 색칠된 이유는 현 시스템에서 word만 직접적으로 확인이 가능한 variable이고 나머지는 아직 숨어있기 때문이다. K개의 topic들이 존재한다면, M개의 document들을 구성하는 word들에 개별적으로 topic을 지정하여서 document들에게 topic들을 분배한다. Dirichlet parameter α를 통해 이 분배과정을 제어할 수 있다. LDA 알고리즘은 document에서 특정 word에게 틀린 topic이 지정되고 나머지 word들에게는 맞는 topic이 지정되었다고 가정하고, 다음 두 가지 사항을 고려하여 각 word에게 topic을 지정한다:
1) m번째 document에 어떤 topic들이 존재하는지
2) document들 전체를 보았을 때에 특정 topic에 word가 몇 번 지정되었는지 (Parameter β를 통해 제어된다.)
위 과정을 반복을 통해 각 document에 적용하여 Fig 1에 숨겨진 variable들을 찾는다.
B. Word: Document를 구성하는 word들을 가리킨다. 자연어 데이터 처리의 경우, LDA 알고리즘에 입력 할 words들은 전처리 과정을 통해서 topic들을 인식하는 데에 도움을 주지 못할 word들(is, are, of, a, the, 등)이 제거되고, 각 word는 알고리즘이 다룰 수 있는 숫자형태의 vector로 변환된다.
C. Document: Document는 ‘collection of words’ 또는 ‘bag of words’이다. 여기서 word들간의 순서는 고려되지 않고, 자연어 처리의 경우, word의 문법적인 역할 또한 고려되지 않는다.
D. Topics: Document들과 그를 구성하는 word들의 군집 또는 빈도수와 같은 특성을 기반으로 구분되는 themes/topic들이다. LDA 알고리즘 훈련 시, document들 내에 존재할 topic들의 개수는LDA알고리즘의 hyperparameter로 설정된다.