LSTM & GRU
긴 sequence다루기
긴 sequence로 RNN을 훈련하면 많은 time step을 거쳐서 실행해야하기때문에 펼쳐진 RNN이 매우 깊은 network가 된다. 앞서 RNN의 기본구조를 설명하면서 언급했던것처럼 gradient 소실 또는 폭주 문제가 발생할 수 있다.
불안정한 gradient 문제를 개선하기위해서 보통 DNN에서 활용되는 가중치 조기화, 빠른 optimizer, dropout, gradient clipping등을 사용할 수 있다. dropout을 사용하려는 경우, 모든 순환층과 keras가 제공하는 모든 cell은 dropout 매개변수와 recurrent_dropout 매개변수를 지원하기때문에, 사용자 정의 cell을 만들 필요없이 dropout을 적용할 수 있다. dropout매개변수는 time step마다 입력에 적용하는 dropout 비율을 정의하고, recurrent_dropout 매개변수는 은닉상태에 대한 dropout 비율을 정의한다.
다른 방안으로 batch normalization을 사용할 수 있겠지만, RNN의 은닉 상태가 아니라 입력에 적용했을때만 조금 효과있다는 것이 확인되어서 큰 도움이 되지는 않는다. batch normalization 대신 RNN에 잘 맞는 정규화 방법으로 층 정규화(layer normalization) 기법이 있다.
층 정규화(layer normalization)
층 정규화는 batch 정규화와 비슷하지만, batch 차원에 대해 정규화하는 대신 특성 차원에 대해 정규화 한다. 장점은 sample에 독립적으로 time step마다 동적으로 필요한 통계를 계산하여 확인할 수 있다는 점이다. (train과 test data에서 동일한 방식으로 작동한다.) 층 정규화는 batch 정규화와 마찬가지로 입력마다 하나의 scale과 이동 parameter를 학습한다. RNN에서 층 정규화는 보통 입력과 은닉상태의 선형 조합 직후 (활성화 함수 전)에 사용된다. 층 정규화를 활용하기 위해서는 다음과 같이 사용자 정의 RNN cell을 define해야한다.
call 함수를 정의해서 각각 따로 정의된 층 정규화와 활성화 함수가 순차적으로 수행되도록 한다.
from tensorflow.keras.layers import LayerNormalization
class LNSimpleRNNCell(keras.layers.Layer):
def __init__(self, units, activation="tanh", **kwargs):
super().__init__(**kwargs)
self.state_size = units
self.output_size = units
self.simple_rnn_cell = keras.layers.SimpleRNNCell(units, activation=None)
self.layer_norm = LayerNormalization()
self.activation = keras.activations.get(activation)
def get_initial_state(self, inputs=None, batch_size=None, dtype=None):
if inputs is not None:
batch_size = tf.shape(inputs)[0]
dtype = inputs.dtype
return [tf.zeros([batch_size, self.state_size], dtype=dtype)]
def call(self, inputs, states):
outputs, new_states = self.simple_rnn_cell(inputs, states)
norm_outputs = self.activation(self.layer_norm(outputs))
return norm_outputs, [norm_outputs]
정의된 LNSimpleRNNCell은 keras.layers.RNN층을 만들어서 전달하면 된다.
model = keras.models.Sequential([
keras.layers.RNN(LNSimpleRNNCell(20), return_sequences=True,
input_shape=[None, 1]),
keras.layers.RNN(LNSimpleRNNCell(20), return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20,
validation_data=(X_valid, Y_valid))
# 0.012 수준의 mse가 확인된다.
LSTM
LSTM은 long short-term memory(장 단기 메모리)를 의미한다. LSTM 방식을 다음과 같이 생각해볼 수 있다. 글을 하나 읽고나서 그 글의 내용을 다른사람에게 이야기 해줄때에 글 전체를 쓰여있는 그대로 말해주기는 어렵다. 글의 내용을 전달하기 위해서는 기억에 남는 중요한 단어나 문장들을 추려내어서 다른 사람에게 이야기해주어도 충분하다. LSTM은 긴 sequene 데이터를 학습하기 위해 이와 비슷한 방식으로 동작한다.
LSTM은 다음과 같은 control flow를 통해서 정보를 잊어버리거나(forget) 또는 유지한다(keep).
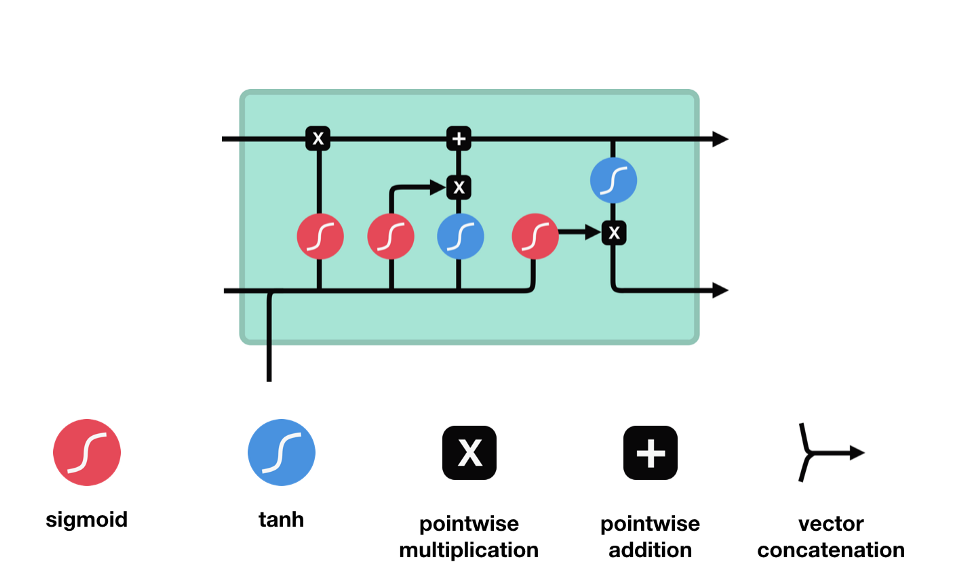
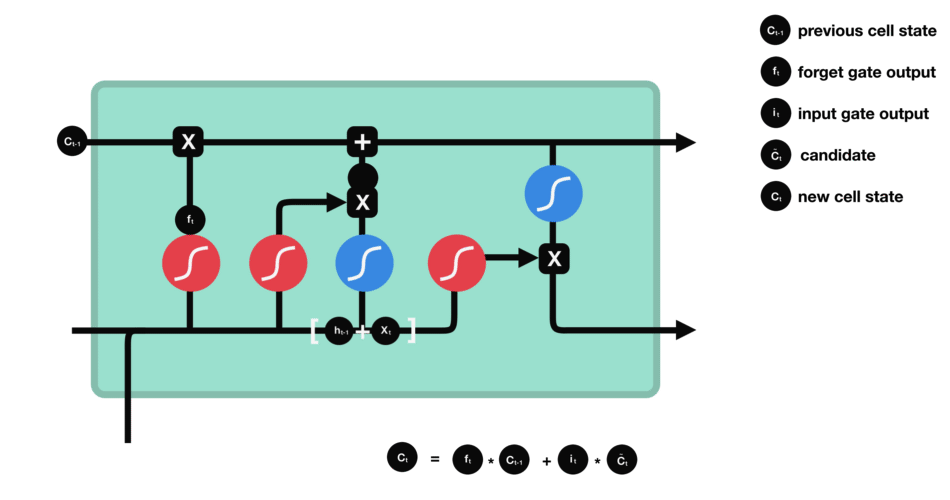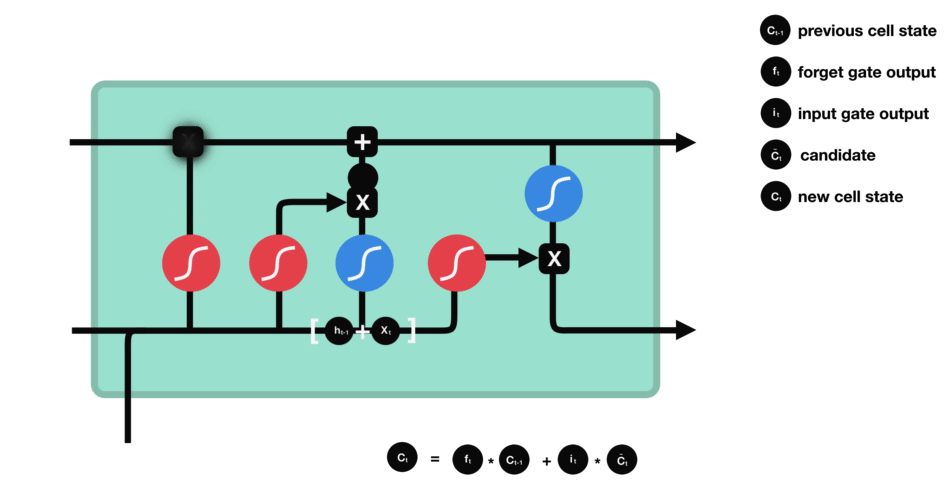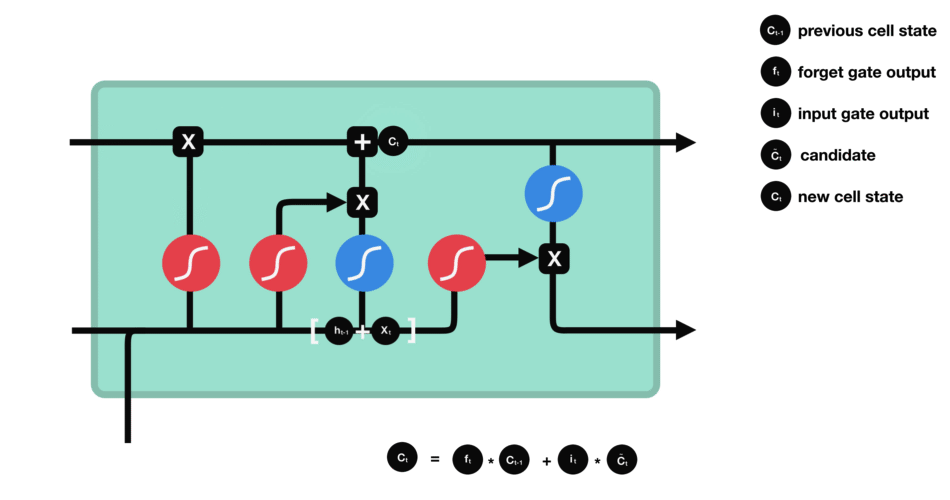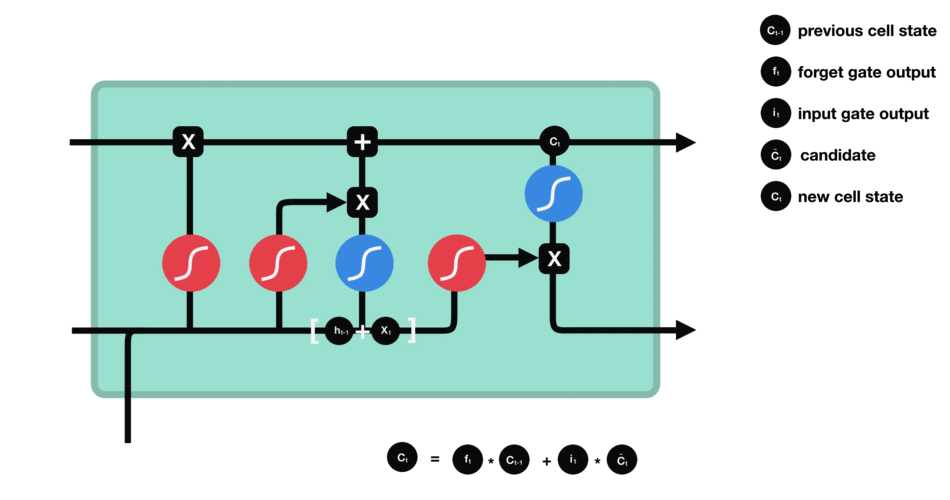
이 control flow에는 여러개의 cell state들과 gate들이 존재한다. cell state는 관련이 있는 정보를 쭉 전체 sequence chain을 따라서 전달해주기 위해 존재한다. network의 “memory”역할을 수행하는 것이다. LSTM의 cell state를 통해서 sequence에서 앞쪽에 인지되었던 정보가 sequence의 뒤쪽이 처리되는 곳까지 잘 유지될 수 있도록 해준다. 이를 가능하게 하는 것이 gate들이다. cell state들은 gate들을 통과하면서 어떤 정보를 무시할지/유지할지가 정해진다. gate들은 어떤 정보가 관련성이 높아 유지되어야하고 어떤 정보가 관련성이 낮아 무시되어야하는지를 결정해서 cell state가 학습하는 정보를 제어하는 역할을 맡는다.
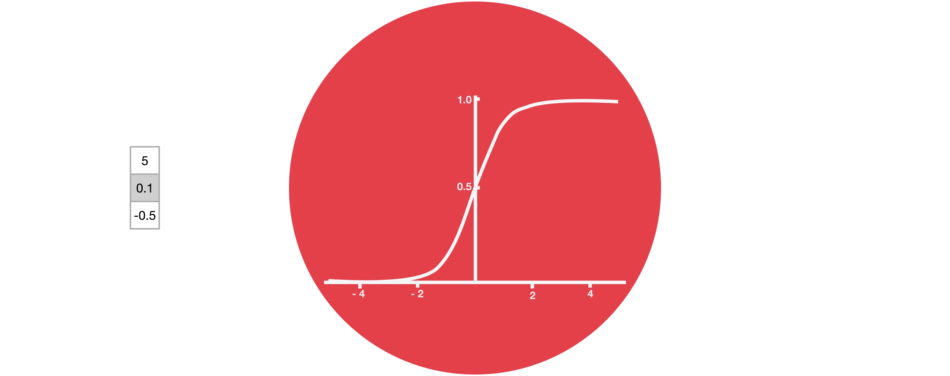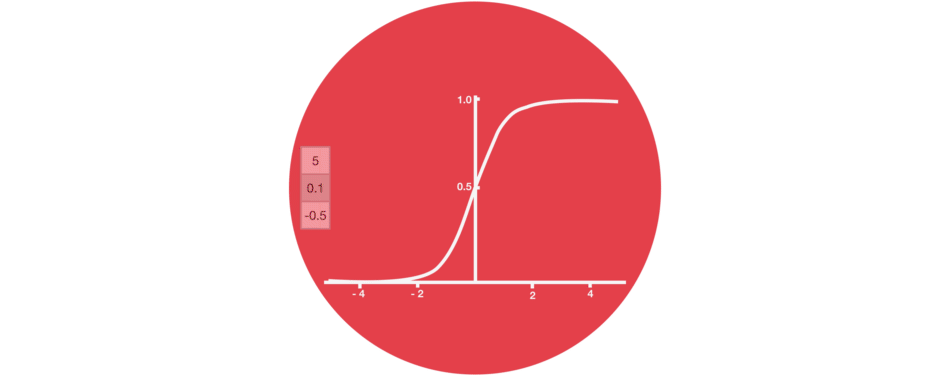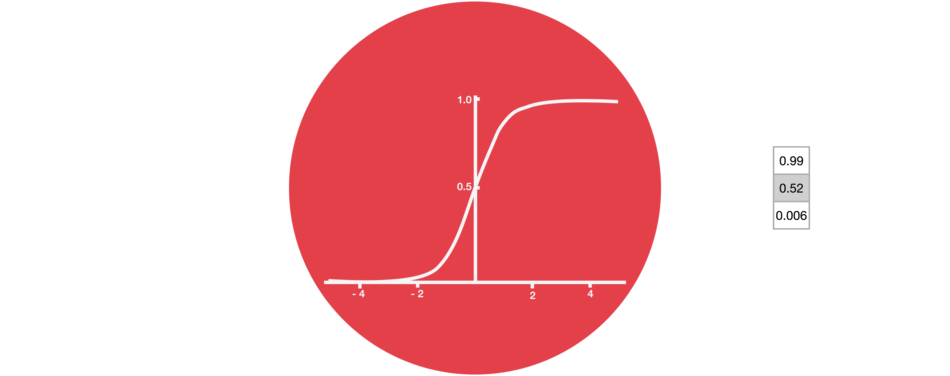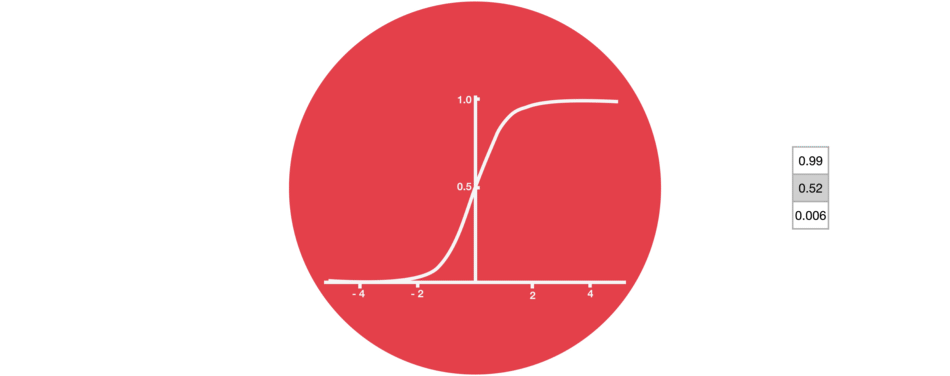
또 한가지 중요한 부분은 sigmoid 활성화 함수이다. 다음 그림과 같이 sigmoid 함수에 들어오는 input을 (0,1) 범위내로 변환시켜준다. 만약 무시해야하는 부분이 있다면 0을 곱해주면 값이 0이 되어 사라질 것이고, 유지해야하는 부분이 있다면 1을 곱해주어서 값이 그대로 유지될것이다.
forget gate - 어떤 정보를 무시할지를 결정한다. 이전 hidden state와 현재 input의 정보를 함께 sigmoid함수를 통과시켜서 (0,1)범위 내의 값을 찾는다. output되는 값이 0에 가까울수록 forget, 1에 가까울수록 keep이 되는 효과를 얻는다.
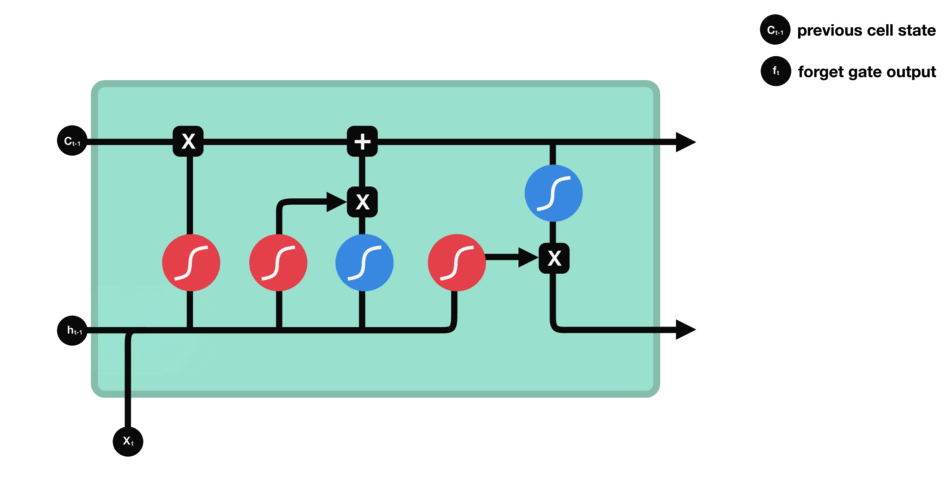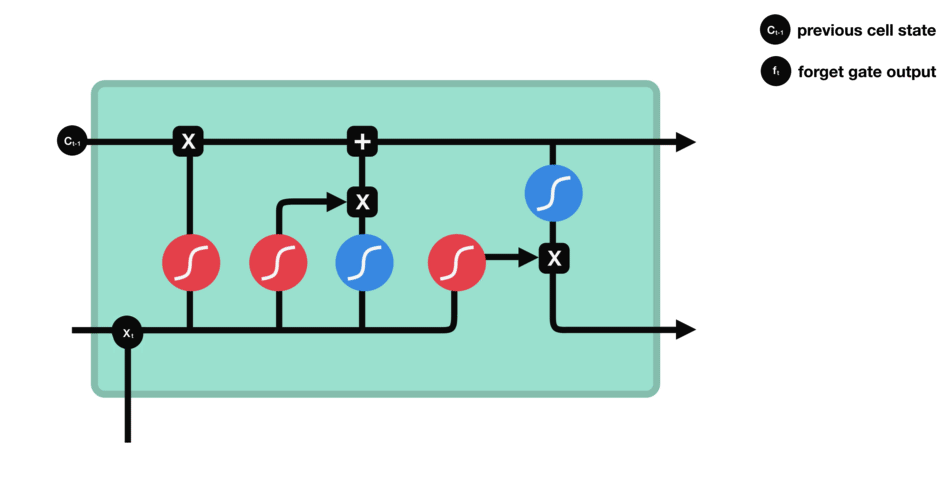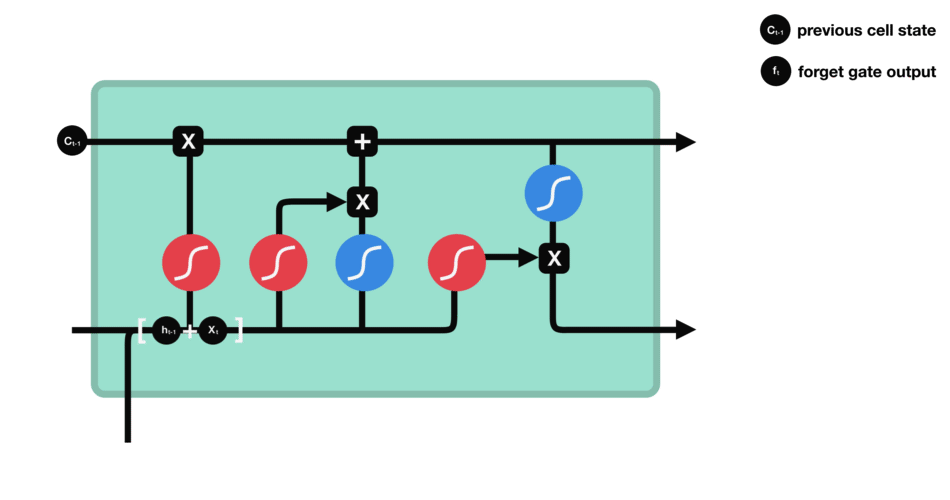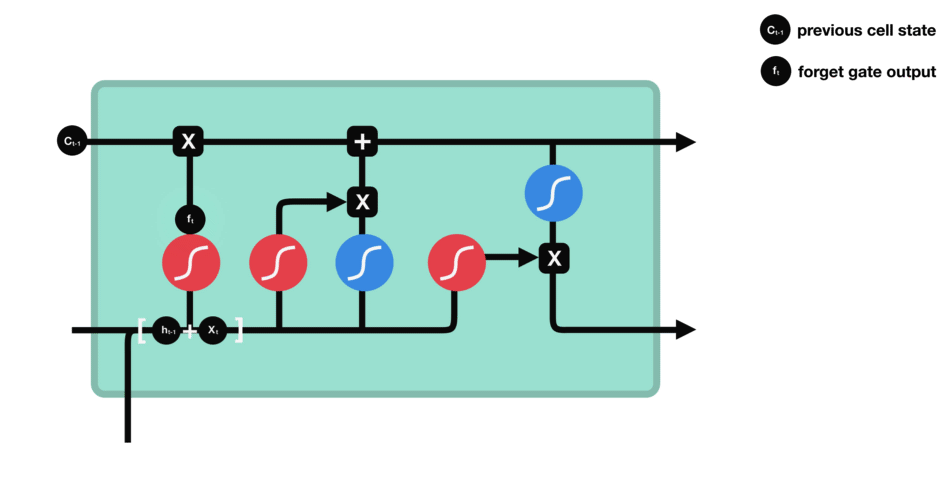
input gate - 이전 hidden state와 현재 input을 sigmoid 함수를 통과시켜서 (forget gate에서와 동일하게) forget/keep 할 것들을 결정하여 구분한다. 그리고 이번에는 이전 hidden state와 현재 input을 tanh 함수를 통과시켜서 (-1,1) 범위내의 값으로 output을 좁힌다. 그 다음 tanh의 ouput과 sigmoid의 output을 곱해서 유지할/무시할 정보를 구분한다.
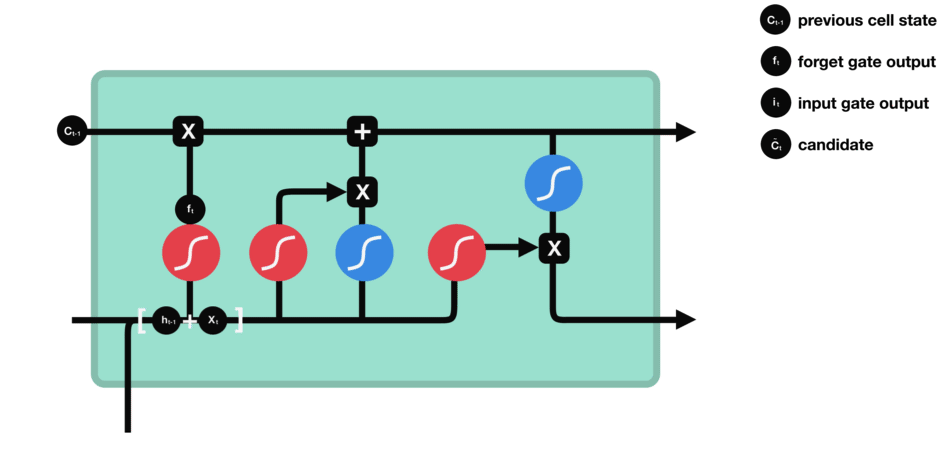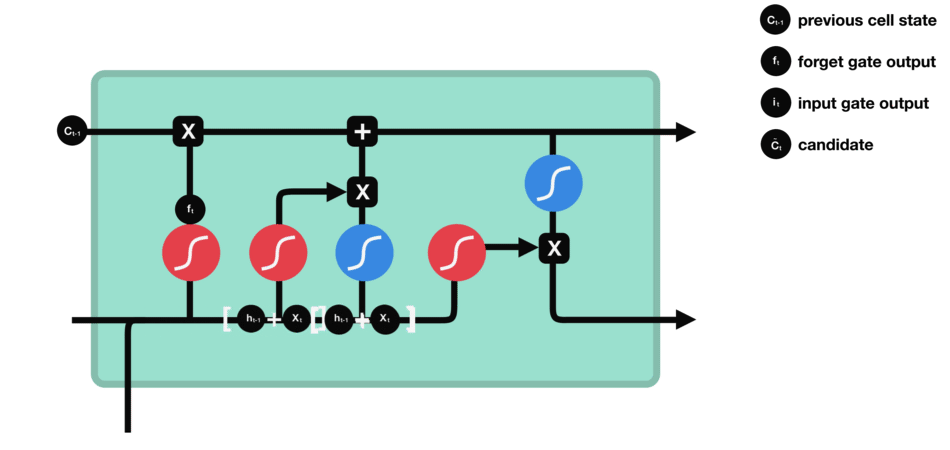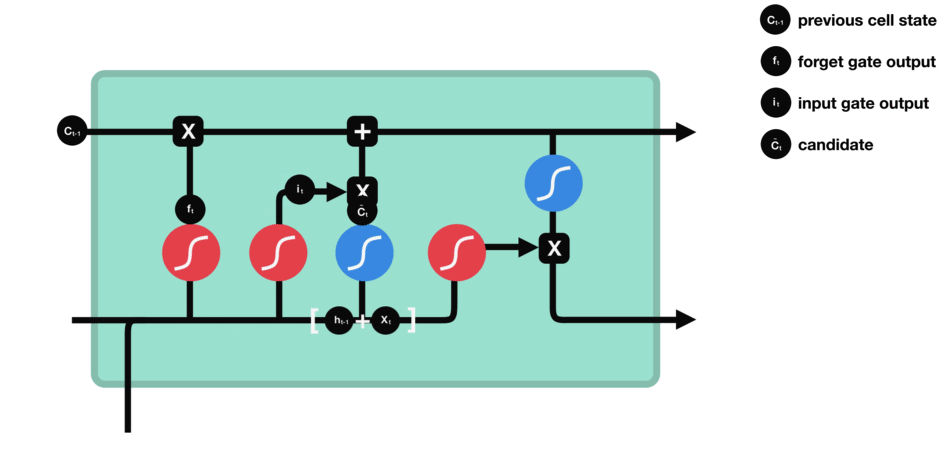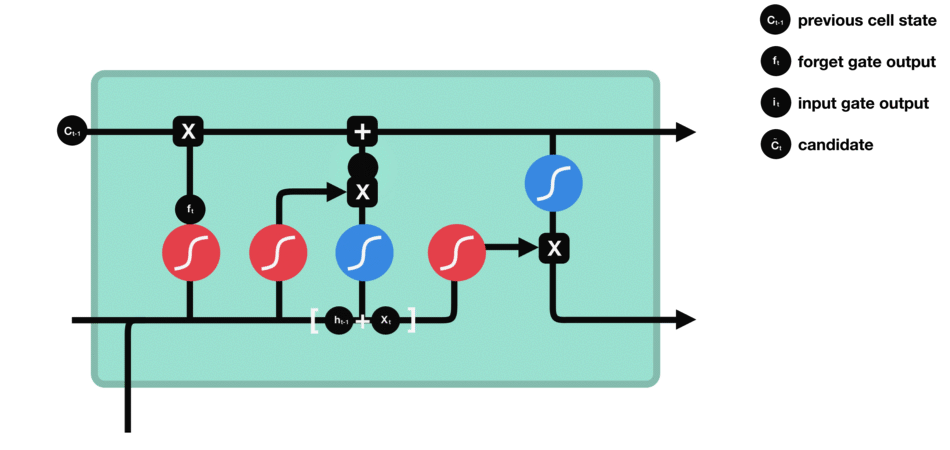
cell state - 위에서와 같이 forget과 input gate를 통해 정보가 얻어졌다면, cell state를 update할 준비가 되었다. 먼저 cell state가 forget vector와 point wise로 곱해진다. 이를 통해 cell state에서 불필요한 정보를 (0으로 곱해서) drop할 수 있다. 그 다음 input gate의 output과 pointwise로 더해져서 neural network이 중요하다고 생각하는 새로운 정보가 cell state에 추가된다. 이렇게 새롭게 update된 cell state를 얻는다.
ouput gate - 마지막으로 output gate에서 다음 hidden state이 무엇이 될지를 결정한다. 먼저 이전 hidden state와 현재 input을 sigmoid function에 통과시킨다. 방금 update된 cell state를 tanh function을 통과시켜서 sigmoid function의 output과 곱한다. 이를 통해 현단계의 hidden state가 다음 단계로 이동할때에 어떤 정보를 가져가야하는지 결정한다. 이렇게 cell state와 hidden state는 다음 단계로 넘어간다.
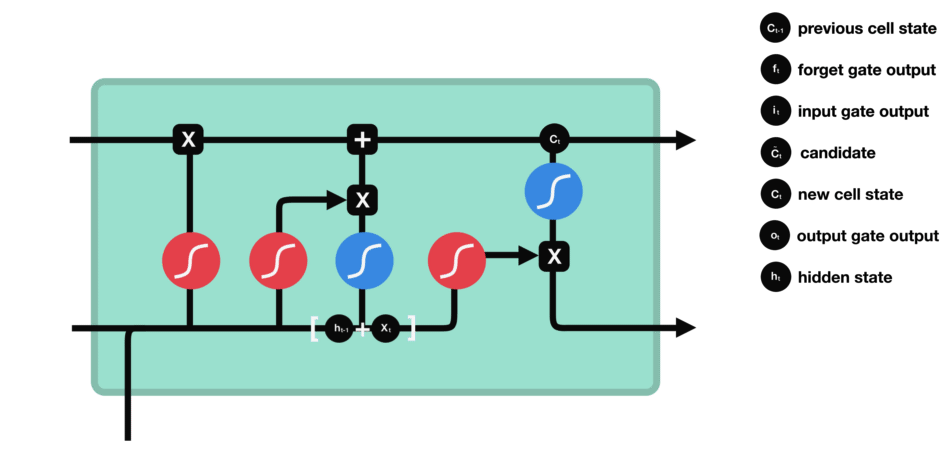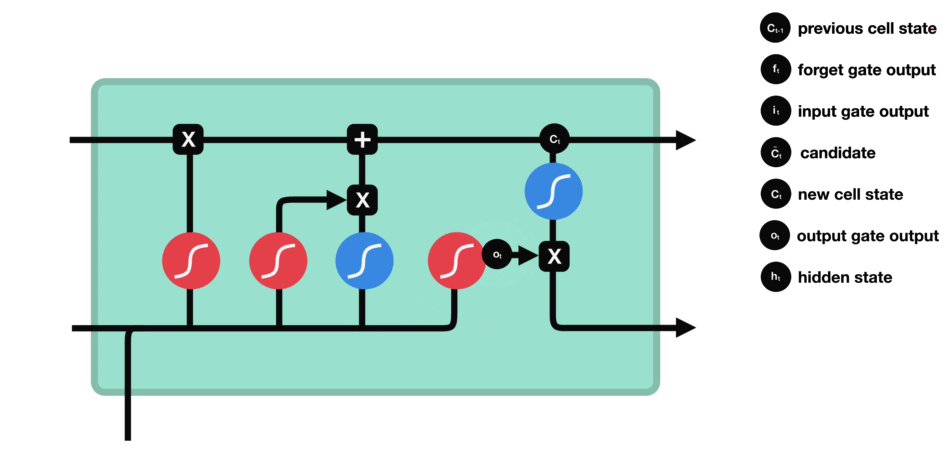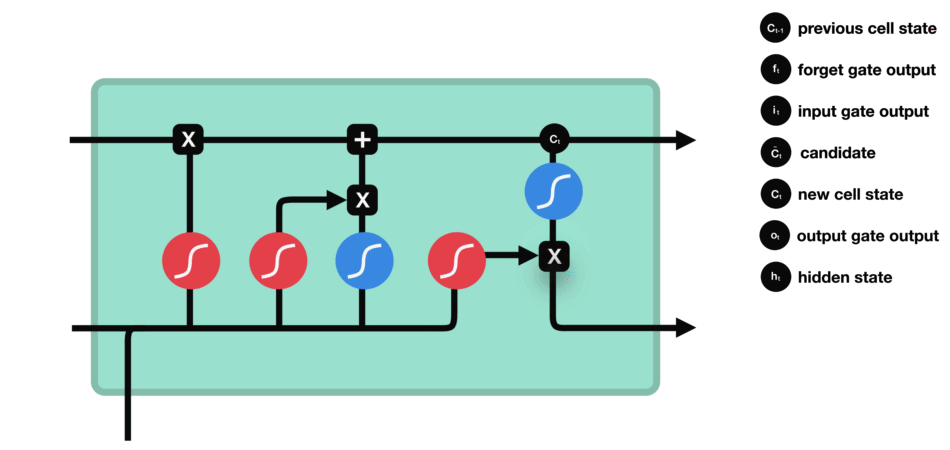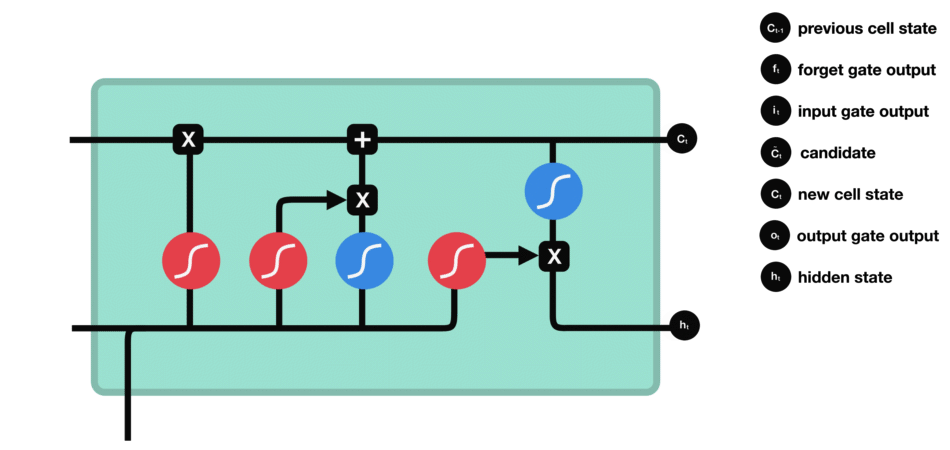
정리해보자면, forget gate는 이전 단계에서 전해져 내려온 정보 중 어떤것들을 유지할지를 결정하고, input gate는 현 단계에서 어떤 새로운 정보를 더할지를 결정한다. 그리고 마지막으로 output gate는 다음 단계로 넘어갈 hidden state를 결정한다.
전체적인 flow를 code 구현한것은 다음과 같다.
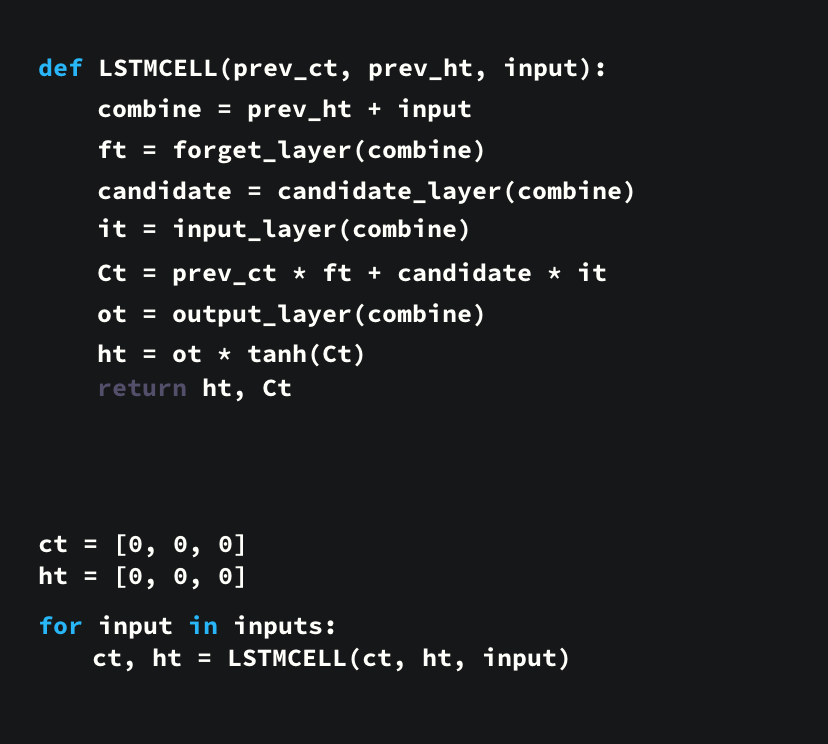
keras의 LSTM층을 사용해서 다음과 같이 구현할 수 있다.
model = keras.models.Sequential([
keras.layers.LSTM(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.LSTM(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20,
validation_data=(X_valid, Y_valid))
GRU
GRU는 LSTM 이후에 개발된 기법이고, LSTM과 비슷하다.
GRU는 LSTM의 cell state를 없애고 hidden state를 사용해서 정보를 전달한다. GRU는 2개의 gate를 가지고있다 - reset gate과 update gate.
다음 그림과 같이 GRU는 LSTM보다 더 간단한 구조를 가지고있다. 더 적은 tensor operation을 가지고있어서 LSTM보다 더 빠른 속도로 훈련할 수 있다. (아직 둘 중 어떤 것이 우월한지는 명확하지 않음.) 일반적으로 researcher/ engineer들은 LSTM과 GRU 모두 실험 해보고, 더 나은 모델을 선택한다.
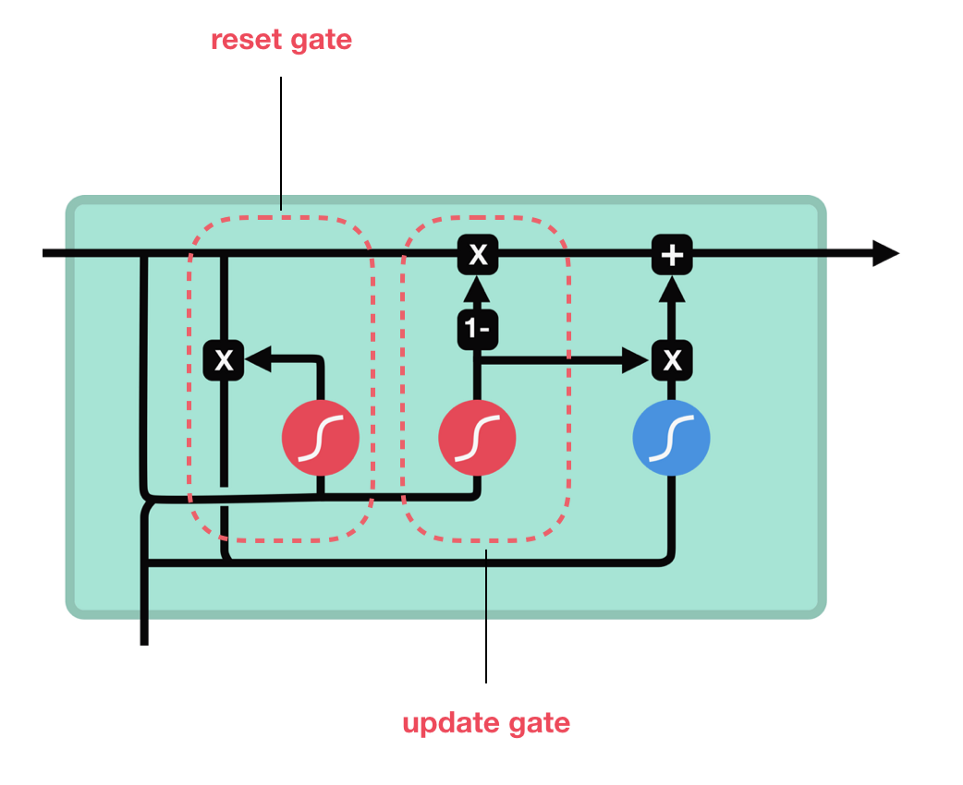
- update gate - LSTM의 forget gate & input gate와 비슷하게 동작한다. 어떤 정보를 무시할지 그리고 어떤 새로운 정보를 더할지를 결정한다.
- reset gate - 이전 단계에서 전해진 정보를 필터링할 수 있는 또 다른 gate이다.
keras의 GRU층을 사용해서 다음과 같이 구현할 수 있다.
model = keras.models.Sequential([
keras.layers.GRU(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.GRU(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20,
validation_data=(X_valid, Y_valid))
Reference
- Geron, Aurelien. Hands on Machine Learning. O’Reilly, 2019
- LSTM with illustration: https://d2l.ai/chapter_recurrent-modern/lstm.html / https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21