Futures
동시성
python 3.2부터 동시성의 구현이 가능해짐.
비동기 작업 처리 : A -> B -> END (순차적)
동시성 활용 권장: 지연시간(Block) CPU 및 resource 낭비 방지할 수 있음. 특히 I/O 관련 작업 진행의 효율을 높일 수 있음
threading과 multiprocessing에서 조금 더 간단하게 사용할 수 있는 것으로 개선된것이 futures
futures: 비동기 실행을 위한 API를 고수준으로 작성 -> 사용하기 쉽도록 개선
concurrent.futures의 가장 기본적인 활용 예시
import os
import time
from concurrent import futures
WORK_LIST = [10000, 100000, 1000000, 10000000]
# 동시성 합계 계산 메인 함수
# 누적 합계 함수(generator)
def sum_generator(n):
return sum(n for n in range(1, n+1))
def main():
# Worker Count
worker = min(10, len(WORK_LIST))
# 시작 시간
start_tm = time.time()
# 결과 건수
# ProcessPoolExecutor or ThreadPoolExecutor
with futures.ProcessPoolExecutor() as executor:
# map -> 작업순서 유지, 즉시 실행
result = executor.map(sum_generator, WORK_LIST)
# 종료 시간
end_tm = time.time() - start_tm
# 출력 포멧
msg = '\n Result -> {} Time: {:.2f}sec'
# 최종결과 출력
print(msg.format(list(result), end_tm))
# 실행
if __name__ == '__main__': # 이렇게 시작점을 명시적으로 작성
main()
- 멀티스레딩/ 멀티 프로세싱 API가 통일되어있어서 -> 적합한 목적에 따라 선택하여 사용하기가 매우 쉬움.
- 실행 중에 작업 취소, 완료여부 체크, 타임아웃 옵션, 콜백 추가, 동기화 코드 매우 쉽게 작성 -> Promise 개념
GIL (Global Interpreter Lock)
Python interpreter가 GIL을 사용해서 thread에 lock을 건다. 여러 thread가 shared memory에 있는 python object를 동시에 access하여 문제가 발생하는것을 방지해준다.
GIL : Global Interpreter Lock - 전체가 lock이 걸리는 현상. 두 개 이상의 스레드가 동시에 실행될때, 하나의 자원을 엑세스 하는 경우 -> 문제점을 방지하기 위해
“GIL ensures that only one thread can run the interpreter at a given instance of time.”
GIL 실행, 리소스 전체에 lock이 걸린다. –> Context Switch (문맥 교환) GIL 때문에 차라리 스레드 하나만을 쓸때 더 빠를 때도 있음. GIL은 멀티프로세싱 사용, CPython(GIL 걸리지 않음)
그래서 GIL prevents the CPU-bound threads from executing in parallel.
그렇다고 multi thread 작업이 불가능한것이 아님. Multi-threads improve the performance of the Python application for IO-bound operations even though the interpreter is only executing the code for one thread at a time. 다음 그림과 같이 multi thread 작업이 수행된다. GIL is only acquired by one thread at a time.
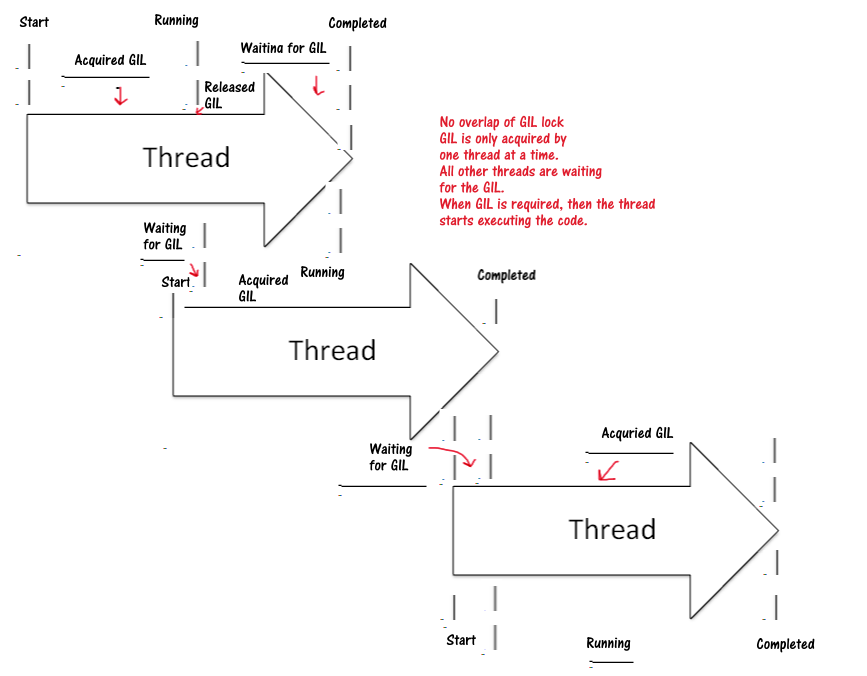
2 가지 pattern 실습: map & wait과 as_completed
concurrent.futures 사용법1 - map
import os
import time
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor, wait, as_completed
WORK_LIST = [10000, 100000, 1000000, 10000000]
def sum_generator(n):
return sum(n for n in range(1, n+1))
def main_wait():
# Worker Count
worker = min(10, len(WORK_LIST))
# 시작 시간
start_tm = time.time()
# futures
futures_list = []
# 결과 건수
# ProcessPoolExecutor or ThreadPoolExecutor
with ProcessPoolExecutor() as executor:
for work in WORK_LIST:
# future 반환
future = executor.submit(sum_generator, work)
# 스케쥴링
futures_list.append(future)
# 스케쥴링 확인
print('Scheduled for {} : {}'.format(work, future))
print()
time_limit = 0.5
# wait 결과 출력
result = wait(futures_list, timeout=time_limit)
# 성공
print('Completed tasks:' + str(result.done))
# 실패
print(f'Pending ones afer waiting for {time_limit} seconds:' + str(result.not_done))
# 결과 값 출력
print([future.result() for future in result.done])
# 종료 시간
end_tm = time.time() - start_tm
# 출력 포멧
msg = '\n Result -> {} Time: {:.2f}sec'
# 최종결과 출력
print(msg.format(list(result), end_tm))
# 실행
if __name__ == '__main__': # 이렇게 시작점을 명시적으로 작성
main_wait()
concurrent.futures 사용법2 - wait, as_completed
wait vs. as_completed
wait: 작업의 workload량에 따라서 결정하기 보다는 시간제한을 두고 다 같이 처리해서 예를 들어 DB에 저장해야하는 경우
as_completed: 작업 workload가 적은 일들을 thread로 처리하는데에 유리함.
def main_as_completed():
# Worker Count
worker = min(10, len(WORK_LIST))
# 시작 시간
start_tm = time.time()
# futures
futures_list = []
# 결과 건수
# ProcessPoolExecutor or ThreadPoolExecutor
with ProcessPoolExecutor() as executor:
for work in WORK_LIST:
# future 반환
future = executor.submit(sum_generator, work)
# 스케쥴링
futures_list.append(future)
# 스케쥴링 확인
print('Scheduled for {} : {}'.format(work, future))
print()
# as_completed 결과 출력
for future in as_completed(futures_list):
result = future.result()
done = future.done()
cancelled = future.cancelled
# future 결과 확인
print('Future Result: {}, Done: {}, Cancelled: {}'.format(result, done, cancelled))
# 종료 시간
end_tm = time.time() - start_tm
# 출력 포멧
msg = '\n Result -> Time: {:.2f}sec'
# 최종결과 출력
print(msg.format(end_tm))
# 실행
if __name__ == '__main__':
main_as_completed()
References
- Python official document on concurrent.futures: https://docs.python.org/3/library/concurrent.futures.html
- Python official document on multiprocessing: https://docs.python.org/3/library/multiprocessing.html
- “Ways to make pandas dataframe operations faster” https://towardsdatascience.com/cython-for-data-science-6-steps-to-make-this-pandas-dataframe-operation-over-100x-faster-1dadd905a00b
- “Why is Python so slow and how to speed it up” https://towardsdatascience.com/why-is-python-so-slow-and-how-to-speed-it-up-485b5a84154e
- “Multi tasking in Python” https://towardsdatascience.com/multi-tasking-in-python-speed-up-your-program-10x-by-executing-things-simultaneously-4b4fc7ee71e
- “Advanced multi tasking in Python” https://towardsdatascience.com/advanced-multi-tasking-in-python-applying-and-benchmarking-threadpools-and-processpools-90452e0f7d40
- “Multiprocessing in Python” https://machinelearningmastery.com/multiprocessing-in-python/
- “Configuring number of worker processes” https://superfastpython.com/multiprocessing-pool-num-workers/