Ensemble
Bias-variance trade-off
ensemble model이 prediction을 만들때에, prediction error를 bias와 variance로 표현할 수 있다. 이 둘은 서로 trade-off 관계이며 모델의 과대/과소 적합이 발생하는 현상을 설명해줄 수 있다.
Bias
bias = error that arises sue to false assumptions made in the learning phase of a model.
Bias(편향)는 model의 average prediction과 actual value사이의 차이를 의미한다.
Bias가 높으면, learning algorithm이 중요한 information이나 independent variable들과 class label들 사이의 correlation을 놓칠 수 있어서 under-fitting을 발생시킬 수 있다. 즉, 편향이 높은 model은 training data의 정확하게 이해하지 못해서 결국 oversimplified 될 수 있는 것이다. 그래서 높은 error on training and test data가 확인 된다.
Variance
variance = how sensitive a model is to small changes in the training data.
Variance(분산)는 given data point 또는 value에 대한 model prediction의 variability이며 the “spread” of our data를 알려준다. Variance가 높으면, model이 훈련 dataset안의 각각의 random noise에 더 민감하게 반응하여서 훈련 데이터를 더 완벽하게 이해하지만, 일반화가 부족하여서 over-fitting을 발생시킬 수 있다. 그래서 training data로는 잘 동작하지만, test data로는 높은 error를 발생시킬 수 있다.
Bias and variance using bulls-eye diagram
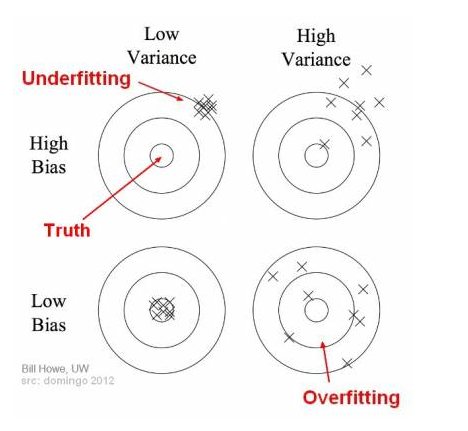
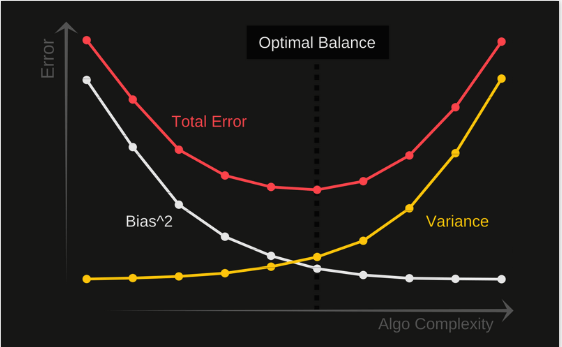
Bias와 variance가 서로 trade-off 관계인 이유는 model이 너무 simple하면 (defined only with very few parameters) bias는 높지만 variance는 낮고, 반대로 model이 너무 complex하면 bias는 낮지만 높은 variance를 가지기 때문이다. 그 사이에서 다음 그림과 같이 total error를 최소화 하는 right/good balance를 찾아야한다.

투표기반 classifier
hard voting(직적 투표): 다수결 투표로 정해지는 분류기
다수결 투표 분류기는 ensemble에 포함된 각각의 분류기 중 가장 높은 성능을 가진것 보다 더 높은 성능을 가질 수 있다. 각 분류기가 weak learner이더라도 (random 추측보다 조금 더 높은 성능을 내는 분류기) 충분히 많고 다양하다면 앙상블은 strong learner가 될 수 있다. 이것은 the law of large numbers (큰 수의 법칙)을 기반으로 한다.
Ensemble 방법은 예측기가 최대한 서로 독립적일때에 최선의 성능을 발휘한다. 다양한 분류기를 얻는 방법 중 하나는 각기 다른 algorithm으로 학습시키는 것이다. 매우 다른 종류의 오차를 만들 가능성이 높기 때문에 ensemble 모델의 정확도를 향상시킨다.
soft voting(간접 투표): 개별 분류기의 예측을 평균 내어 확률이 가장 높은 클래스를 예측한다. (각 분류기가 클래스의 확률을 예측할 수 있어야함. (predict_proba() method가 있어야함. SVC와 같은 경우에는 기본값에서는 클래스 확률을 제공하지 않기때문에 probability 매개변수를 True로 지정해야한다.))
간접투표 방식은 확률이 높은 투표에 비중을 더 두기때문에 직접투표 방식보다 성능이 높다.
Bagging & Pasting
투표기반 방식과 같이 다양한 알고리즘을 사용하는 방법과는 달리, 반대로 하나의 알고리즘을 사용하고 train dataset를 무작위로 여러 subset으로 구성해서 각기 다르게 학습시키는 방법이 있다. train dataset에서 중복을 허용하여 sampling하는 방식을 bagging(“bootstrap aggregating”)이라 하고, 중복을 허용하지 않고 sampling하는 방식을 pasting이라고 한다.
Bagging과 pasting 방식에서는 같은 훈련 sample들을 여러개의 예측기에 걸쳐 사용할 수 있다. 모든 예측기가 훈련을 마치면 ensemble은 모든 예측기의 예측을 모아서 새로운 sample에 대한 예측을 만든다. 수집 함수가 classification 문제에서는 통계적 최빈값을 찾고, regression 문제에서는 평균을 계산한다. 개별 예측기는 각각 원본 훈련세트의 subset으로 훈련되었기때문에 훨씬 더 편향되어 있지만, 수집 함수를 통화하면 편향과 분산이 모두 감소하게 된다. 보통 ensemble의 결과는 원본 데이터셋으로 하나의 예측기를 훈련시킨 결과와 비교했을때에 편향은 비슷하지만 분산은 줄어든다.
boostrap은 sampling 방식에서 중복을 허용하기때문에 예측기가 학습하는 data subset의 다양성을 증가시킨다. 그래서 bagging이 pasting보다 편향이 조금 더 높다. 그리고 다양성이 더 크면 예측기들의 상관관계를 줄기때문에 분산이 감소한다. 전반적으로 bagging이 더 나은 모델을 만드는것으로 예상된다. (but 실제 bagging과 pasting을 평가해서 판단이 필요함.)
Bagging을 사용해서 중복을 허용하여 어떤 세트는 여러번 sampling되고, 어떤 샘플들은 아얘 훈련에 사용되지 않을 수 있다. 훈련세트의 크기 만큼인 m개의 샘플을 선택한다면, 평균적으로 각 예측기에 훈련 샘플의 63% 정도만 샘플링된다는 것을 의미한다. 나머지 37%를 “oob”(out-of-bag) 샘플이라고 부른다. 이 샘플들은 훈련에 사용되지 않았기때문에 검증용 데이터로 사용될 수 있다.
Random patch & Random subspace
매우 고차원의 데이터셋을 다룰때 특성의 sampling방식이 유용하게 사용될 수 있다. BaggingClassifier의 경우 특성 샘플링도 지원한다. max_features, bootstrap_features 매개변수로 설정할 수 있다. 각 예측기는 무작위로 선택한 입력 특성의 일부분으로 훈련된다.
훈련 특성과 샘플을 모두 sampling하는것은 random patches method라고 하고, 훈련 샘플을 모두 사용하고, 특성은 sampling하는 것을 random subspaces method라고 한다. 특성 sampling방식에서는 더 다양한 예측기를 만들어서 분산을 낮출 수 있다.(편향이 늘어날 수 있음.)
RandomForest
RandomForest는 decision tree classifier 예측기에 bagging 또는 pasting 방식을 적용한 ensemble이다. (Bagging Classifier에 DecisionTreeClassifier를 넣어 생성하지 않고, RandomForestClassifier를 편리하게 사용함. 회귀 문제에서는 RandomForestRegressor를 사용.) RandomForest 알고리즘은 tree의 node를 분리할때에 전체 특성 중에서 최선의 특성을 찾지않고 무작위로 선택한 특성 후보중에서 최적의 특성을 찾는다. 이렇게 무작위성이 들어가서 각각의 다양성이 커지고 편향 또한 커지지만, 분산이 작아지는 장점을 얻는다.
트리를 더욱 무작위하게 만들기위해 특성을 사용해서 무작위로 분할한다음, 그중에서 최상의 분할을 선택한다. 이렇게 극단적으로 무작위한 트리의 random forest를 extremely randomized trees (“extra-tree”) 라고 부른다. (Sci-kit learn에 ExtraTreeClassifie를 사용). RandomForest를 시킬지
Boosting
hypothesis boosting
boosting방식은 앞 모델을 보완해나가면서 예측기를 학습시키는 것이다. 주로 많이 사용되는것들이 Adaboost (Adaptive Boosting)과 gradient boosting이다.
Adaboost
adaboost 방식에서는 이전 모델이 과소적합했던 훈련 샘플의 가중치는 더 높여서 이전 예측기의 부족한 부분을 보완하며 새로운 예측기를 만들어 간다. 예를 들어서 알고리즘이 기반이 되는 첫번째 분류기를 훈련세트에 훈련시키고 예측을 만든 다음, 잘못 분류된 샘플들의 가중치를 더 높인다. 이렇게 업데이트된 가중치를 가지고 두번째 분류기에서 예측을 만들다. 그 다음 계속 지속적으로 가중치의 업데이트가 진행된다. 이런 flow는 분류하기 더 어려운 샘플에 예측기가 점점 더 맞추어지도록 한다.
다음과 같은 공식과 parameters를 사용해서 업데이틀할 가중치 값(D)을 구한다.

맞게 classify된 샘플에 주어지는 가중치는 다음과 같이 계산되고

틀리게 classify된 샘플에 주어지는 가중치는 다음과 같이 계산된다.
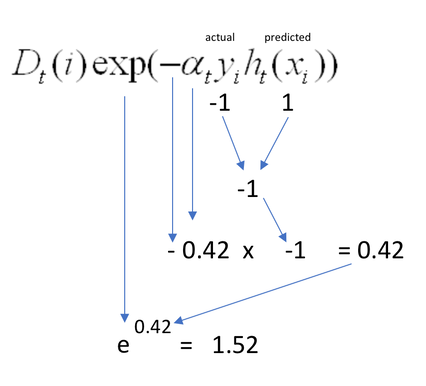
Adaboost에서는 지정된 예측기 수에 도달하거나 완벽한 예측기가 만들어지면 반복을 중지한다.
훈련 후 실제 예측을 할때에, Adaboost는 모든 예측기의 예측을 계산하고 예측기 가중치 (D)를 더해서 예측 결과를 만든다.
Gradient boosting
adaboost처럼 gradient boosting 방식은 ensemble에서 이전까지의 오차를 보정하도록 예측기를 순차적으로 개선/추가한다. But, adaboost와는 다른게 iteration마다 샘플의 가중치를 수정하지 않고, 이전 예측기가 만든 잔여 오차(residual error)에 새로운 예측기를 학습시킨다.
decision tree를 기반으로 gradient boosting이 사용된다면, learning rate 매개변수를 조정해서 각 tree의 기여 정도를 조절할 수 있다. 축소(“shrinkage”)라고 부르는 규제 방식인데, learning rate을 아주 낮게 설정하면 ensemble 훈련 세트에 학습시키기 위해 많은 예측기가 필요해지지만 ensemble의 성능이 결국 더 좋아지는 효과를 얻을 수 있다. tree(예측기)가 충분하지 못하면 과소적합의 문제가 발생할수도 있고, 너무 많으면 과대적합 문제가 발생할 수 있기때문에, 처적의 tree 수를 찾기 위해서 early stopping을 활용할 수 있다.
최적화된 gradient boosting 기법으로 XGBoost (Extreme Gradient Boosting) 패키지가 있다.
References
“Understanding the Bias-Variance Tradeoff” by Seema Singh https://towardsdatascience.com/understanding-the-bias-variance-tradeoff-165e6942b229
Geron, Aurelien. Hands on Machine Learning. O’Reilly, 2019
https://towardsdatascience.com/adaboost-for-dummies-breaking-down-the-math-and-its-equations-into-simple-terms-87f439757dcf#:~:text=Simply%20put%2C%20the%20idea%20is,iterations%20of%20the%20algorithm%20proceed
XGBoost Documentations
https://xgboost.readthedocs.io/en/stable/
https://xgboost.readthedocs.io/en/stable/tutorials/index.html
https://www.kaggle.com/general/236940