Ensemble
Cascading
Ensemble은 여러 model의 장점을 leverage해서 collective하게 결국 더 좋은 성능을 확보하는 기법이다. Collected model들의 prediction에 variety가 있다면 이를 활용해서 ensemble은 더 좋은 성능을 확보할 수 있다. Ensemble은 보통 여러 model들을 parallel하게 실행하고 그들의 output들을 통합해서 final prediction을 만든다. Cascades는 ensemble의 다양한 기법중에 한 종류로서 collected models를 parallel이 아닌, sequential하게 실행한다. 각각의 output을 confidence threshold를 기준을 충족할시에 solution으로 merge한다. 간단한 inputs를 다룰때에는 cascades는 더 적은 computation을 활용하지만, 더 복잡한 inputs를 다룰때에는 많은 개수의 models를 실행해야할수도있어서 결국 더 높은 computation cost가 발생할 수 있다.
overview of ensemble and Cascade:
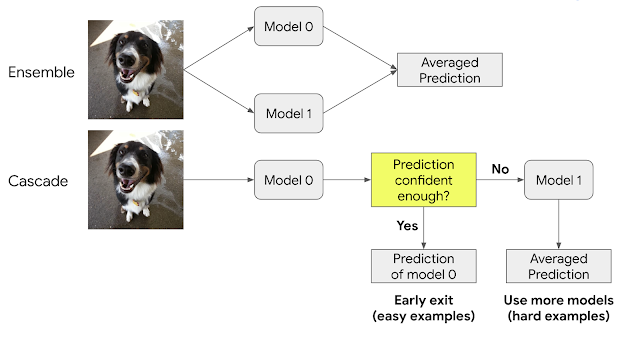
특정 경우에따라 복잡한 DNN보다 간단한 model들의 ensemble이 더 좋은 (more efficient) solution을 제공할 수 있다. 다음과 같이 ensemble model의 beneficial properties가 있다:
- simple to build - ensemble은 보통 복잡한 technique가 필요하지 않다. early exit policy learning 참고
- easy to maintain - ensemble안의 모델들이 각각 따로 훈련되기 때문에 유지보수하고 배포하는 작업이 더 간단해질 수 있다.
- affordable to train - ensemble안의 모델들의 total training cost는 비슷한 성능의 하나의 모델의 training cost에 비해서 더 낮은 경우가 많다.
- on-device speedup - computation cost (FLOPS) successfully translates to a speedup on real hardware
효율성과 훈련 속도
동일한 computational cost를 가진 ensemble vs. single model을 비교하여 어떤것이 더 높은 성능을 확보하는지 확인해본 결과 (analysis of series of models, EfficientNet-B0 to EfficientNet-B7), ensemble이 large computation regime(>5billion FLOPS)에서는 더 cost-effective하다는 것이 확인되었다.
Ensemble of two EfficientNet-B5 models은 ~50% fewer FLOPS가 필요하지만, 모델의 성능 관점에서는 single EfficientNet-B7 model과 비슷한 수준이다. 또한 training cost of an ensemble can be much lower (e.g., two B5 models: 96 TPU days total; one B7 model: 160 TPU days) 실제 모델훈련과정을 구현할때에는 multiple accelerator를 사용해서 training을 parallelize할 수도 있다.
Power and cascade의 simplicity
Ensemble의 subset만으로도 원하는 답을 얻을 수 있다면, cascade 방식으로 early exit을 구현해서 computation을 save할 수 있다. 여기에서 문제는 cascade에서는 언제 exit을 해도 되는지를 결정하는 것이다. 간단한 heuristics를 사용해서 prediction의 confidence를 확인할 수 있다. model의 confidence 값을 가지고 각 class에 assign된 maximum probabilities를 판단한다.
예시) multiclass classifier (cat, dog, horse) -> prediction outcome with probabilities cat: 20%, dog: 80%, horse: 20%이라면, confidence of the model’s prediction(dog)은 0.8이다. 이 값을 우리가 정한 threshold값과 비교해서 cascade를 exit할지 아니면 계속 후속 모델로 어어갈지를 결정한다.
EfficientNet, ResNet, MobileNet2 families로 구성된 cascade ensemble로 avg. FLOPS vs. image 분류 정확도를 확인해본 결과, 모든 computation regime에서 (FLOPS range from 0.15Billion to 37Billion) cascade가 single model을 outperform하는 것이 확인되었다. For more details on experiment, refer to paper. 이 논문에선 cascade의 구성을 at most 4 models로 제한했다. Cascade ensemble을 사용하면 large pool of models에서 더 빠르게 combination option들을 구현하고 확인해 볼 수 있다.
References
- Model Ensembles Are Faster Than You Think https://ai.googleblog.com/2021/11/model-ensembles-are-faster-than-you.html
- https://medium.com/@saugata.paul1010/ensemble-learning-bagging-boosting-stacking-and-cascading-classifiers-in-machine-learning-9c66cb271674