Test results for data augmentation
Time series data augmentation을 연구한 Fawaz의 논문을 보면 모든 데이터셋에서 DBA기반의 data augmentation이 분류성능 향상에 기여하지는 못한다. 실험에 사용되었던 UCR dataset중 몇 가지에는 negative 영향을 끼쳤다. Accuracy metric만 표기되어있어 평가결과를 해석하는데에 제한적이긴 하지만, accuracy의 개선이 확인되지 못한 케이스도 존재했다.
현재 진행하고 있는 분류 문제에 사용되고있는 데이터셋을 증폭하여 분류성능을 개선하는데에 DBA 기반의 data augmentation이 도움이 될 지 확인해보았다. 분류하려는 RCA(root cause analysis)의 시계열 데이터셋은 imbalance된 형태여서 10개 정도의 RCA class 중 3~4개의 class의 sample수가 전체의 1% portion도 못미친다. 해당 class sample들을 DBA(DTW Barycentric Averaging) augmentation을 활용하여 oversampling을 하고 분류 성능을 확인해 보았다.
다음과 같이 두가지 case로 augmentation이 분류 성능에 끼치는 영향을 확인해 보았다.
case1. minor class들의 augmented size를 fix하고, augment되는 class수를 늘려가며 분류 결과 확인
case2. augment되는 minor class 수를 fix하고, augmenting size를 늘려가며 분류 결과 확인
case1 (class수 증가)
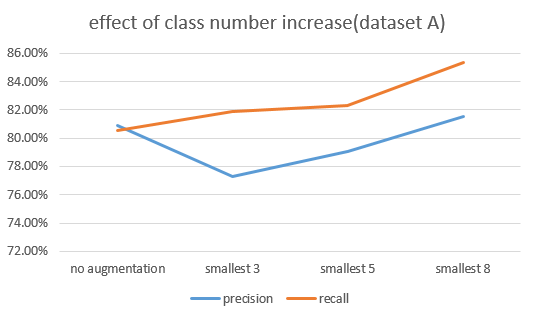
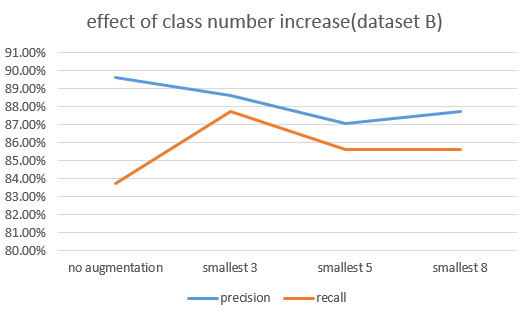
Cython을 사용하여 DBA 연산 속도를 향상시켜서 case별 훈련 및 분류 성능 metrics(recall, precision)을 확보할 수 있었다. Augmented sample size를 500으로 fix하고 augment하는 class의 수를 가장 minor한 class 3개, 5개, 8개까지 늘려가며 classification metrics를 확인해보았다.
DatasetA에서는 8개의 class의 augmentation이 진행되서야 precision, recall둘 다 개선되는 결과가 확인되었고, datasetB에서는 오히려 augmentation으로 인해 precision이 떨어지는 결과가 확인되었다.
case2 (augment size 증가)
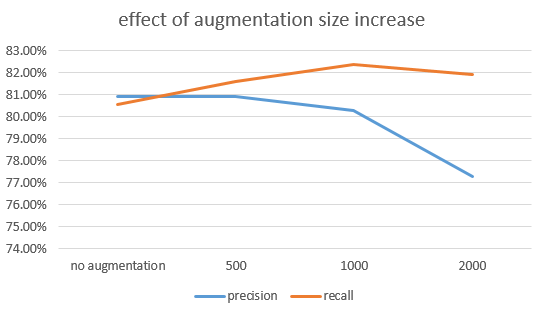
Augment되는 class수는 8개로 fix하고 각각의 class sample size를 500,1000, 2000까지 augment하여 classification metrics를 확인해보았다. Augmentation이 추가되기 전 보다, precision이 더 낮아지는 결과가 확인되었고, recall은 augmented size가 늘어날 수록 더 높은 값이 확인되었다.
References
Fawaz, Ismail, et al. Data augmentation using synthetic data for time series classification with deep residual networks (2018)
Forestier, G., Petitjean F., et al. Generating synthetic time series to augment sparse datasets (2017)