CNN(Convolutional Neural Network)
local receptive field(국부 수용장) - 뉴런들이 시야의 일부 범위 안에 있는 시각 자극에만 반응 한다. 시각 피질의 국부 수용장은 수용장이라 불리는 시야의 작은 영역에 있는 특정 패턴에 반응한다. 그리고 시각 신호가 연속적인 뇌모듈을 통과하면서 뉴런이 더 큰 수용장에 있는 더 복잡한 패턴에 반응한다.
이미지 인식 문제에서 일반적인 완전연결층의 심층 신경망을 사용하지 않는 이유 - 완전 연결층의 심층 신경망은 작은 이미지에서는 잘 작동하지만, 큰 이미지에서는 아주아주아주 많은 parameter들이 만들어지기 때문에 문제가 된다. (e.g., 100x100 pixel image의 경우 input layer의 neuron이 10,000개이며, 첫번째 은닉층에서 neuron을 1000개만 가져가도 연결이 총 1천만개가 되어버린다.) 그래서 CNN은 layer를 부분적으로 연결하고 가중치를 공유해서 parameter들이 너무 많아지는 것을 방지 한다.
또한, 완전연결층의 심층 신경망(fully connected neural network)의 문제는 spatial orientation을 잃어버린다는 것이다.
e.g., 강아지의 눈, 코, 입이 제대로된 위치에 존재하는것을 인지해야지만 해당 이미지가 강아지얼굴이라는 결론을 내릴 수 있을것이다.
convolutional layer(합성곱층)
첫번째 합성곱층의 뉴런은 input layer(입력 이미지)의 모든 pixel에 연결되는것이 아니라 합성곱층 뉴런의 수용장 안에 있는 pixel에만 연결된다. –> 두번째 합성곱증에있는 각 뉴런은 첫번째층의 작은 시각 영역 안에 위치한 뉴런에 연결된다.
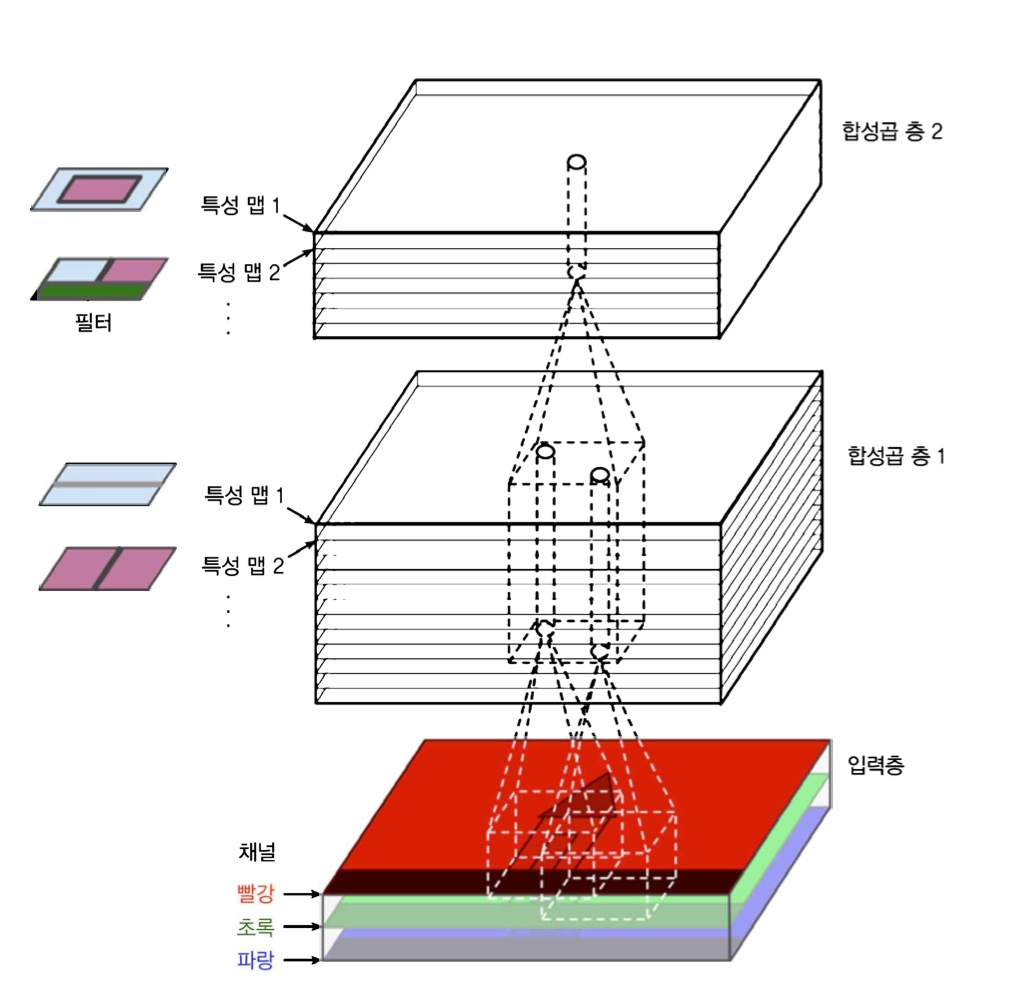
이런 network구조는 다음과 같은 방식을 가능하게 한다 - 첫번째 은닉층에서 작은 저수준 특성에 집중하고, 그 다음 은닉층에서는 더 큰 고수준 특성으로 조합해 나가도록 도와준다.
CNN에서는 각 층이 2D로 표현되므로 뉴런을 그에 상응하는 입력 (2D image)과 연결하기 더 쉽다.
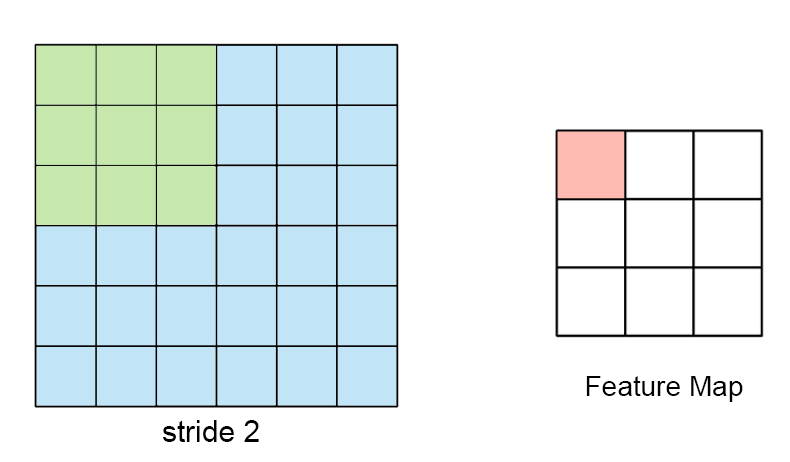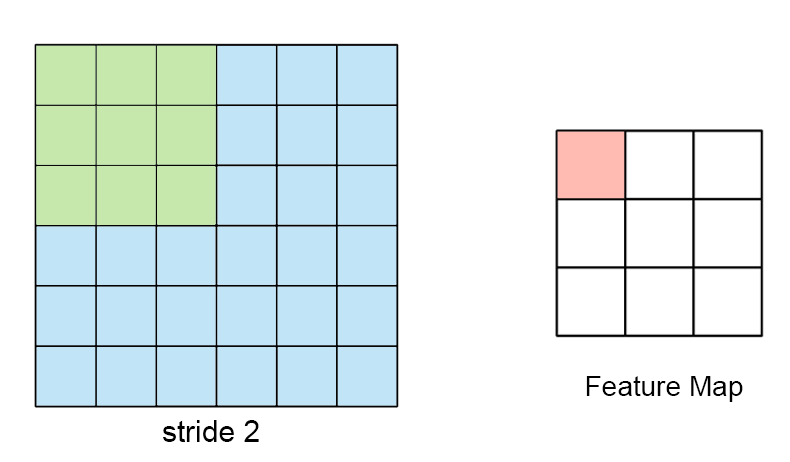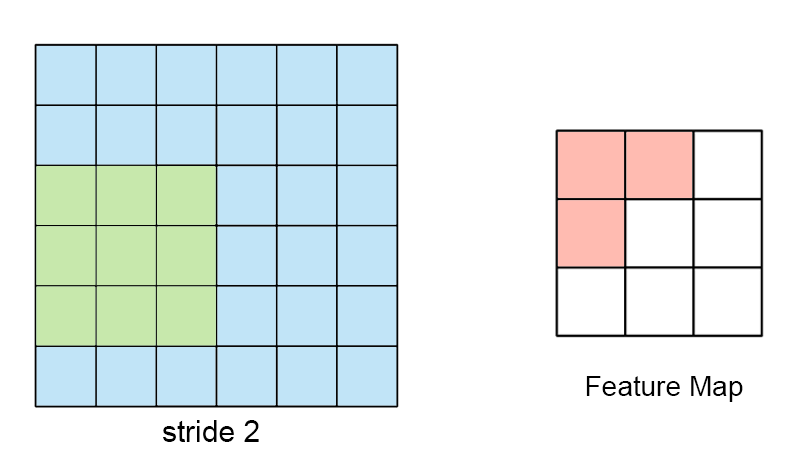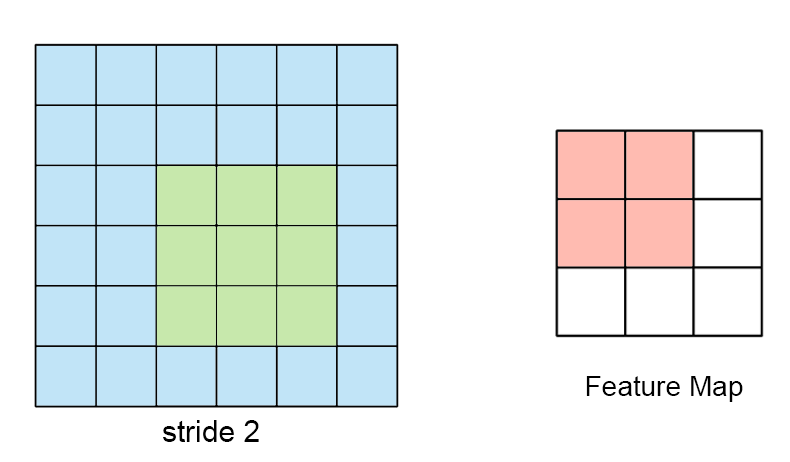
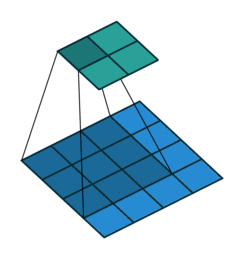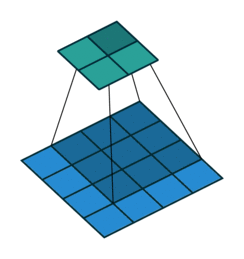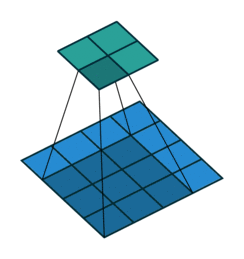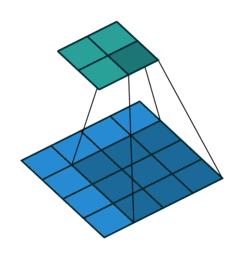
수용장 사이 간격을 두어서 더 큰 입력층을 훨씬 작은 층에 연결하는 것도 가능 함. 한 수용장과 다음 수용장 사이의 간격을 stride라고 부른다. 수평 stride는 s_w, 수직 stride는 s_h라고 표기한다면, 이전층(상위층)의 i행, j열에 있는 뉴런이 이전 층의 i x s_h에서 i x s_h + (f_h -1)까지의 행과 j x s_w에서 j x s_w + (f_w -1)까지의 열에 위치한 뉴런들과 연결된다.
다음 그림과 같이 stride값이 더 크면, 더 큰 pixel 크기의 이미지가 더 작은 feature map으로 추려질 수 있다.
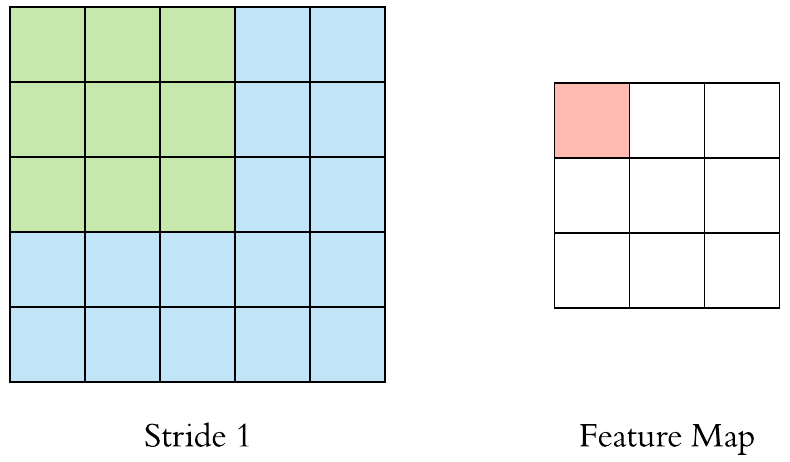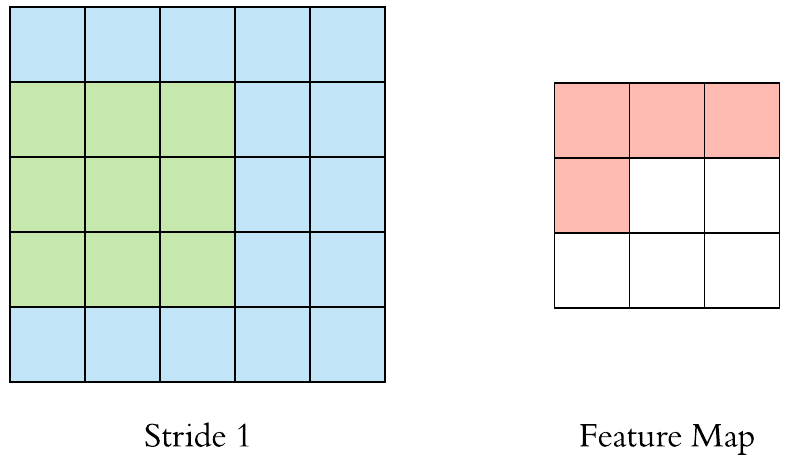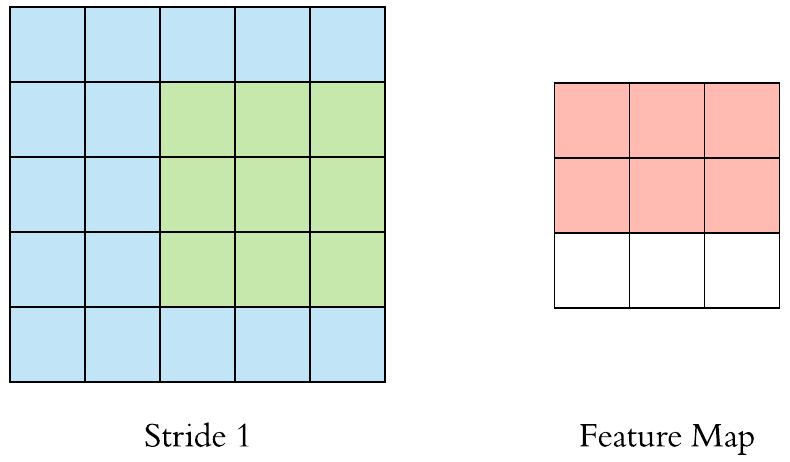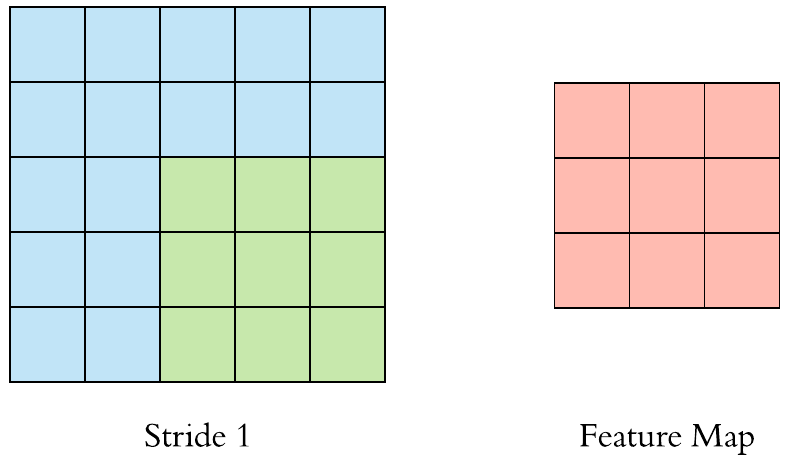
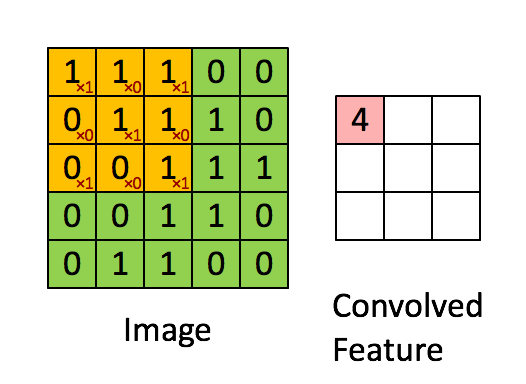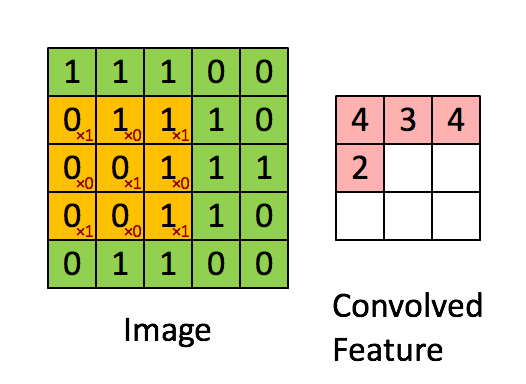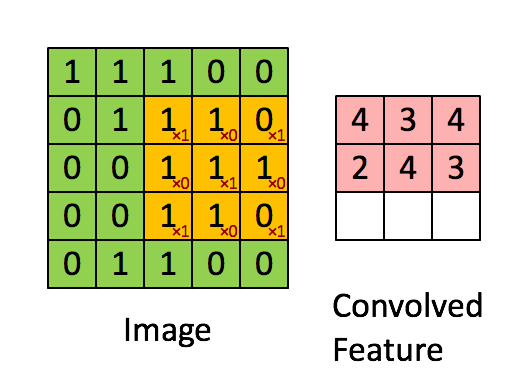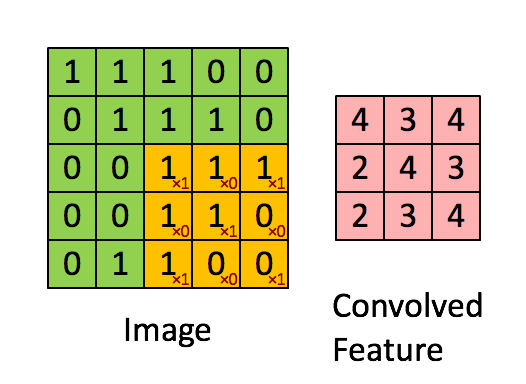
뉴런의 가중치는 수용장 크기의 작은 이미지로 표현될 수 있다. filter (or convolutional kernel)를 통해 이전층의 이미지에서 원하는 부분만 “filter”해서 학습할 수 있다 예를 들어서 수직 필터(가운데 열은 1로 채워져있고, 그 외에는 모두 0인 7x7 행렬)를 통해서 가운데 수직선 부분은 제외하고는 나머지는 모두 0이 곱해지기때문에 후속 층으로 전송되지 못하고 무시하게 된다.
다음 그림과 같이 filter-right sobel을 통해서 오른쪽 수직선만 filter하는 경우 extract된 결과물이 어떤지 실제 이미지로 보여준다. 이렇게 전체 뉴런에 적용된 하나의 filter는 하나의 feature map을 만든다. feature map을 보면 filter를 가장 크게 활성화 시키는 이미지 영역이 강조된것을 확인할 수 있다. 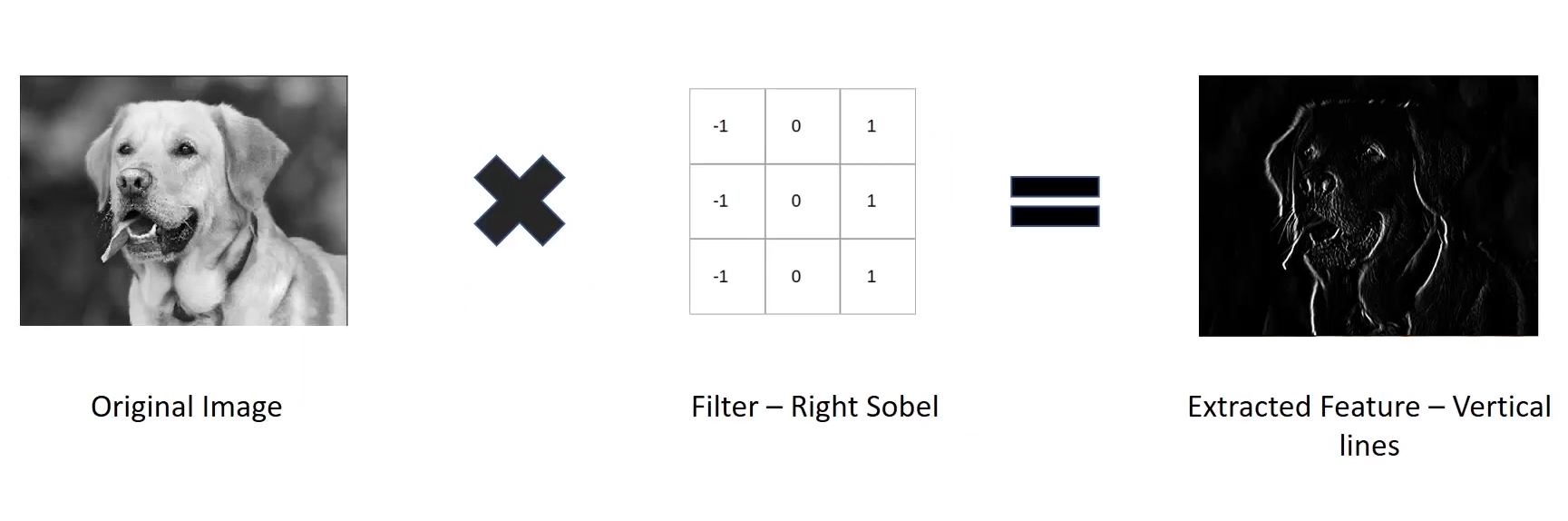
feature map 쌓기
실제 convolutional layers는 여러가지 filter를 가지고 filter마다 하나의 특성 map으로 출력함으로 3D로 표현하는것이 더 현실적이다. 각 특성 map (feature map)은 pixel하나의 뉴런에 해당하고 하나의 특성 map안에서는 모든 뉴런이 같은 parameter(동일한 wieghts & bias)를 공유하지만, 다른 특성 map에있는 뉴런은 다른 parameter를 사용한다. 한 뉴런의 수용장(receptive field)는 이전층에있는 모든 특성map에 걸쳐 확장된다. 즉, 하나의 합성곱층에 여러 필터를 동시에 적용하여 입력에 있는 여러 특성을 감지할 수 있는 것이다.
입력 이미지는 color channel마다 하나씩 여러 서브 층으로 구성되기도 한다 - 주로 R,G,B(빨강, 초록, 파랑) 만약 이미지가 흑백이라면 color channel은 1 이다. 위성 이미지의 경우에는 다른 빛 파장로 기록하기때문에 3개 이상의 channel을 사용하기도 함.
공식 표현:
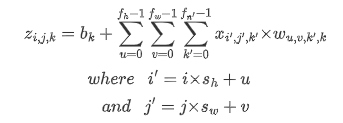
이미지에 filter를 적용해서 output을 만들기 위한 저수준 딥러닝 함수 - tf.nn.conv2d()에 다음과 같은 매개변수가 전달된다:
images - 입력의 mini batch (4D tensor)
filters - 적용될 일련의 filters (4D tensor). filter를 사용하는 이유는 입력 이미지속의 features들과 그들의 spatial orientation을 보존하기 위함이다. (e.g., 이미지에서 강아지의 얼굴, 다리, 꼬리를 인지해서 강아지라는결론을 내리는 것.) 아래 그림과 같이 이미지를 가로질러가며 filter(주황색)가 감지한 feature를 계산해서 output을 특성 map(분혹색)에 기록해둔다.
strides - 1 or 4개의 원소를 갖는 1D 배열로 지정할 수 있음. 4개에서 중간 2개는 수직, 수평 stride (s_h, s_w)이고 첫번째와 마지막 원소는 나중에 batch stride(일부 sample 건너뛰기위함)와 channel stride(이전 층의 특성 map이나 channel 건너뛰기위함)로 사용될 수 있다.
padding - “VALID” or “SAME” 둘중 하나 선택.
- “VALID”는 zero padding을 사용하지 않는것. 그래서 stride에 따라 입력 이미지의 아래/오른쪽 행과열이 무시될 수도 있음. 수용장이 입력의 안쪽에만 놓인다는 의미로 valid임.
- “SAME”은 필요한 경우 zero padding을 사용하는 것. (입력 크기가 13이고, stride가 5이면, 출력 크기는 3임. (13/5 = 2.6 –>올림해서 3)) 필요시 입력 데이터 주변에 가능한 양쪽 동일하게 0이 추가된다. padding을 추가함으로서 output dimension을 input dimension과 동일하게 가져갈 수 잇다.
훈련 가능한 변수로 filter를 정의해서 신경망에 가장 잘 맞는 filter를 학습할 수 있음. 변수를 직접 만들기보다는 다음과 같이 keras.layers.Conv2D 층을 사용한다.
conv = keras.layers.Conv2D(filters=32, kernel_size=3, strides=1,
padding="same", activation="relu")
합성곱 layer이 매우 큰 memory용량이 필요하다.
예시)
filter= 5x5, stride=1, padding=”SAME”, 입력 이미지=150x100(RGB image이기때문에 channel=3)
입력 이미지에 filter 적용되면 다음과 같은 합성곱층 (convolutional layer)이 만들어진다 -
해당 합성곱층의 parameter개수: (5x5x3+1)x200 = 15,200개 (‘‘+1”은 bias때문에 추가된것임. 200개의 feature map들은 각각 filter로 정의된 parameter를 가진 15,000개의 neuron을 갖고있기때문에, 각 feature map은 76 parameters를 갖고있다. 해당 층에는 총 200개의 feature map이 있기때문에 76x200 = 15,200개의 parameter가 존재한다.)
- 해당 합성곱층의 특성map 개수: 200개 (각 150x100 = 15,000개의 뉴런 포함하고있고, 각 뉴런은 5x5x3=75개의 입력에대한 가중치 합을 계산 해야 한다.)
- 이 합성곱증에서 수행되어야하는 실수 계산은 5x5x3x15000x200 = 2억2천5백만개
훈련을 할때에는 역방향 계산을 위해 정방향에서 계산햇던 모든 값을 가지고있어야 함. 그래서 사용하는 메모리양이 엄청나진다. 만약 메모리부족으로 훈련에 실패한다면, mini batch 크기를 줄여볼 수 있다. 또는 stride 조정해서 차원을 줄이거나 몇개의 층을 제거할 수도 있다.
Pooling
pooling층의 목적은 계산량, 메모리 사용양을 줄이는 목적으로 만들어졌는데, 결과적은 과대적합의 위험을 줄여준다. prameter수를 줄이기 위해 입력 이미지의 subsample(축소본)을 만드는 것이다.
pooling은 일정 수준의 invariance(불변성)을 만들어 준다. 작은 변화에 둔감해지는것이다. 최대 풀링으로 인해 이동, 회전, 확대, 축소에대한 불병성을 얻을 수 있다. 분류작업처럼 작은 부분에 영향을 받지않는 경우에 최대 풀링이 유용하게 사용될 수 있다. 이름 그대로 가장 큰 특징만 유지하고 나머지는 버려버리는 조금 극단적인 방법이다.
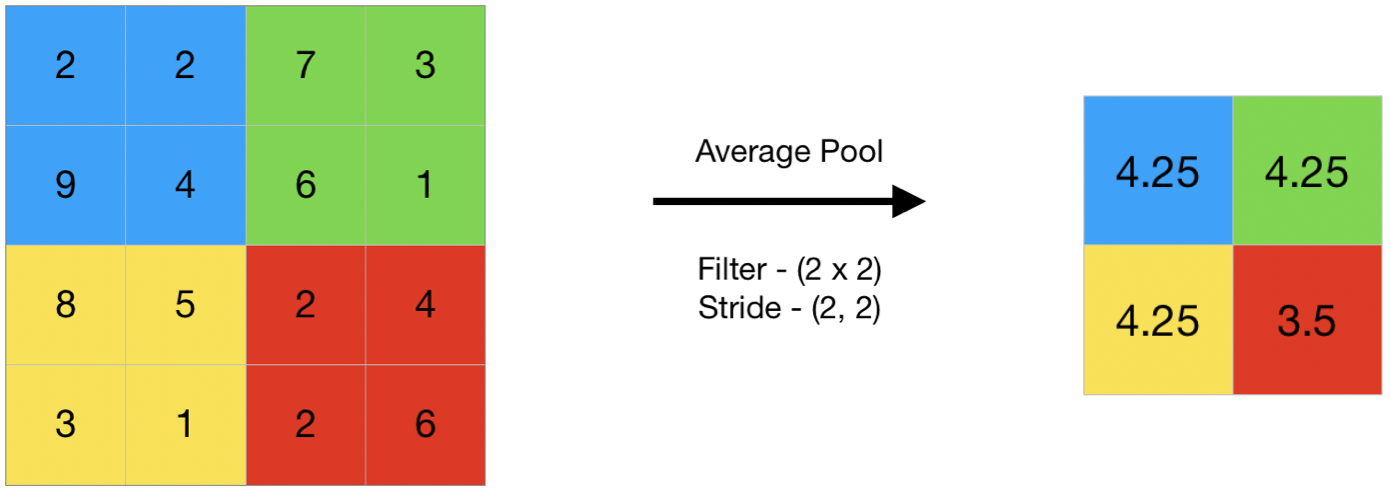
최대 풀링은 파괴적이기때문에 시맨틱 분할(pixel이 속한 객체에 따라 pixel을 구분하는 작업)과 같은 경우에는 최대 풀링이 적절하지 않다. (입력의 작은 변화가 출력에서 그에 상응되는 작은 변화로 이어져야 하기 때문에) 평균 풀링을 사용하면 최대 풀링보다 정보손실이 적어진다.
max pooling:

avg pooling:
CNN구조
#MNIST dataset기반 문제 해결위한 CNN
model = keras.models.Sequential([
keras.layers.Conv2D(64, 7, activation="relu", padding="same",
input_shape=[28,28,1]),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128, 3, activation="relu", padding="same"),
keras.layers.Conv2D(128, 3, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(256, 3, activation="relu", padding="same"),
keras.layers.Conv2D(256, 3, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Flattten(),
keras.layers.Dense(128, activation="relu")
keras.layers.Dropout(0.5)
keras.layers.Dense(64, activation="relu")
keras.layers.Dropout(0.5)
keras.layers.Dense(10, activation="softmax")
])
위 code의 설명:
MNIST dataset에서는 이미지가 아주 크지 않기 때문에 첫번째 층은 63개의 큰 필터(7x7)와 stride=1를 사용한다. 이미지가 28x28 크기이고 흑백이기때문에 input_shape=[28, 28, 1]로 지정한다.
pooling 크기가 2인 max pooling을 통해 공간 방향 차원을 절반으로 줄인다.
CNN이 출력층에 다다를수록 filter개수가 늘어난다.
저수준 특성(작은 동심원, 수평선, 등)의 개수는 적지만 이를 연결해서 고수준 특성을 만들 수 있는 방법이 많고 이런 방법이 더 합리적이다. 일반적으로 pooling층 다음으로 filter 개수를 두배로 늘린다. (64–> 128 –>256개) pooling층이 공간 방향 차원을 절반으로 줄이므로 이어지는 층에서 parameter 개수, 메모리 사용량, 계산비용을 늘리지 않고 특성 map 개수를 두배로 늘릴수 있다.
Convolution층 이후, 완전연결 network는 두 개의 은닉층과 하나의 출력층으로 구성되어있다. Dense network는 sample의 특성으로 1D 배열을 기대하므로 입력을 일렬로 펼쳐야 한다. 그리고 밀집층 사이에 과대적합을 줄이기 위해 50%의 dropout 비율을 가진 dropout층을 추가한다.
Data augmentation
진짜 같은 훈련 데이터를 생성해서 훈련세트 크기를 늘린다. 훈련이미지를 랜덤하게 이동하거나, 수평으로 뒤집고 조명을 바꾸는 등 data를 증식해서 더 다양한 case가 포함되게 하는 것이 목적이다.
예시) 조명 조건에 민감하지 않은 모델을 만들기 위해 비슷하게 여러가지 명암을 가진 이미지를 생성하는 data augmentation을 진행할 수 있다.
LRN(local response normalization)
합성곱층의 ReLU 활성화 함수 단계이후 LRN라는 경쟁적인 정규화 단계를 사용하는것이다. 가장 강하게 활성화된 뉴런이 다른 특성 맵에 있는 같은 위치의 뉴런을 억제한다. (이런 경쟁적인 활성화가 생물학전 뉴런에서 관측되어서 적용하게 되었음.) 이는 특성 map을 각기 특별하게 다른것과 구분되게 하고, 더 넓은 시각에서 특징을 탐색할수 있도록 유도해서 결국 모델의 일반화 성능이 개선된다. AlexNet에서 처음 적용되면서 알려졌다.
tf.nn.local_response_normalization() 를 통해 구현할 수 있다. keras 모델에서 사용하려면 lambda층에 감싸서 사용할 수 있다.
Image classification 성능 향샹 순서대로 model :
LeNet-5(by Yan LeCun(1998)) –> AlexNet(by Alex Krizhevsky, et al(2012)) –> GoogLeNet(by Christian Szegedy(2014)) & VGGNet(by Karen Simonyan(2014)) –> ResNet(by Kaiming He(2015)) –> Xception(by Francois Chollet(2016)) –> SENet(2017)
GoogLeNet
inception module을 사용해서 더 깊이있는 CNN architecture을 형성할 수 있게한다.
inception module
inception module에서는 합성곱층을 형성해 나아가면서 ReLU 활성화 함수를 사용한다. 그리고 stride=1과 padding=”same”을 유지해서 입력과 동일한 높이 너비로 (이미지 사이즈) 연결층”filter concatenation”으로 연결된다. 연결층은 ““깊이 연결 층(depth concatenation layer)”으로 불리며 모든 출력을 깊이 방향으로 연결해준다.
아래 그림에서 ‘3x3+1(S)’는 3x3 kernel, stride=1, padding=”same”을 의미한다.
처음에 입력신호가 복사되어 4개의 다른 층에 주입된다. 그리고 두번째 합성곱 층은 각기 다른 kernel size (1by1, 3by3, 5by5)를 사용해서 각기 다른 크기의 패턴을 잡는다.
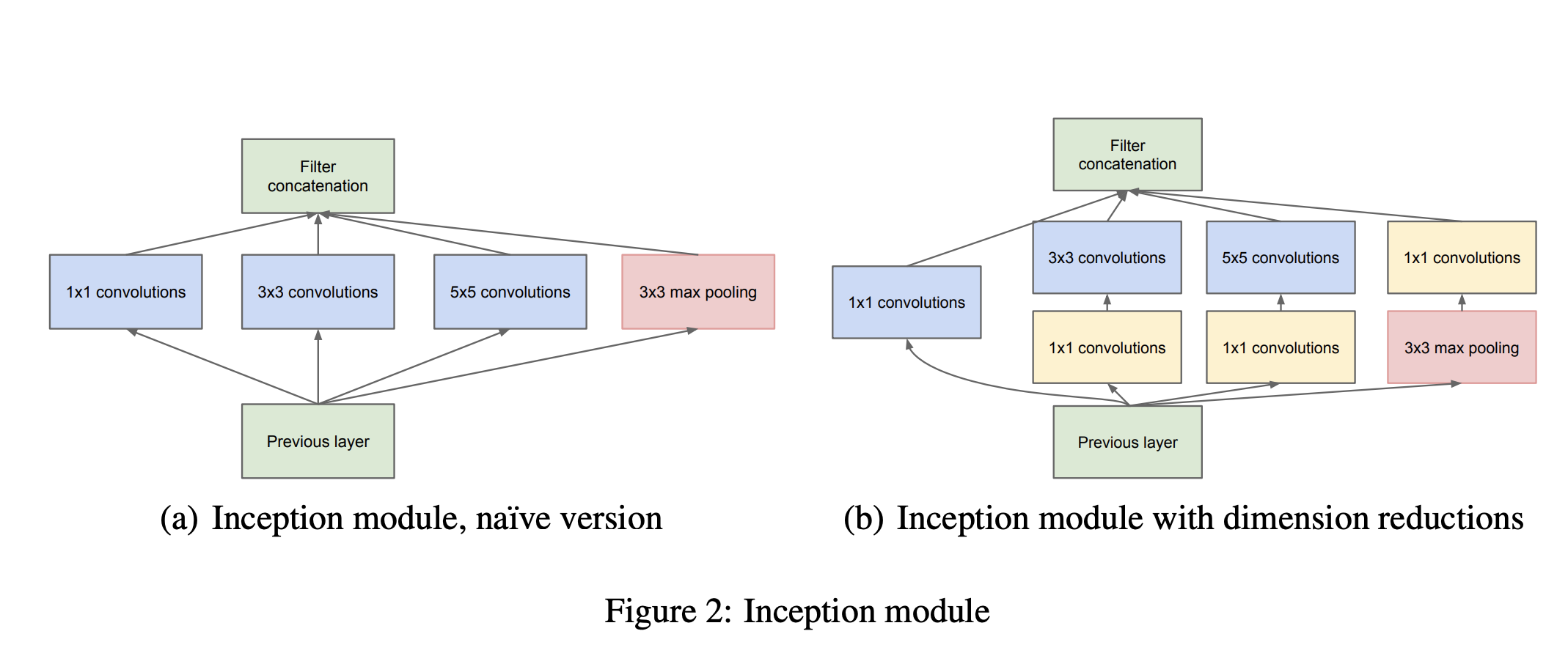
An Inception Module is an image model block that aims to approximate an optimal local sparse structure in a CNN. Put simply, it allows for us to use multiple types of filter size, instead of being restricted to a single filter size, in a single image block, which we then concatenate and pass onto the next layer.
inception module은 1 x 1 kernel의 합성곱층을 가진다. 이 층은 한번에 하나의 pixel만 처리하는것인데 무슨 목적으로 사용하는 것일까?:
- 공간상의 pattern(e.g., spatial orientation)을 잡을 수는 없지만, 깊이 차원에 따라 놓인 pattern을 찾을 수있음.
- 입력보다 더 적은 특성맵을 출력하기때문에 차원을 줄이는 의미의 bottleneck layer역할 수행 (parameter 수 감소, 훈련 속도 향상, 일반화 성능 향상)
- 합성곱 쌍을 통해 더 강력한 합성곱층을 구현한다. 합성곱 쌍을 사용하면 두개의 층을 가진 신경망으로 이미지를 훑는 것과 같기때문에 합성곱쌍은 단순한 선형분류기보다 더 깊이있게 이미지의 특성을 찾아낸다.
“Think of the inception module as 여러 크기의 복잡한 패턴이 담긴 특성 맵을 출력하는 합성곱 층 on steroids.”
GoogleNet구조:
합성곱 층 + 풀링 층 + 9개의 inception module으로 구성되어 매우 깊은 network이다. 다음과 같은 순서로 network flow가 형성된다:
입력직 후 많은 정보를 유지하기 위해 첫번째 층은 큰 크기의 kernel을 사용한다. 처음 2개의 층에서는 계산의 양을 줄이기위해 max pooling을 통해 이미지의 높이 & 너비를 4배로 줄인다. (면적은 16배 줄어듬)
LRN층은 이전층이 다양한 특성을 학습하도록 만든다.
그 다음 이어지는 2개의 합성곱층에서는 첫번째 층이 병목처럼 작동한다. 이 두개의 층이 쌍으로 활동한다.
다시한번 LRN층으로 통해 이전 층이 다양한 패턴을 학습하도록 만든다.
max pooling 층이 계산 속도를 높이기 위해 이미지의 높이와 너비를 2배로 줄인다.
그 다음, 9개의 inception module이 이어진다. 차원 감소 & 속도 향상의 목적으로 중간에 max pooling이 들어가있다.
inception module이 끝난 후, 전역 평균 풀링 층이 각 특성맵의 평균을 출력한다. 여기에서 spatial orientation(공간 방향)을 모두 잃게 된다. 그래도 이 지점에서는 별로 공간 정보가 안남아있기때문에 괜찮다. (GoogleNet의 전체 network을 지나게되면 224x224 이미지가 7x7크기로 줄어들게된다.) image classification 문제는 위치 추정(localization)이 아니기때문에 분류작업에는 물체가 어디있는지가 중요하지 않기때문에 괜찮다. 여기에서 수행되는 차원 축소 적문제 CNN위에 몇개 fully connected 층을 둘 필요가 없다. 이런 방식은 parameter수를 크게 감소시키고 overfitting 위험도 줄여준다.
마지막 층에서는 규제를 위한 dropout층 다음에 1000개의 unit과 softmax 활성화 함수를 적용한 완전 연결 층으로 각 1000개의 class의 확률값을 출력한다.
실제 GoogleNet 에는 부가적인 분류기가 포함된다. 소실 문제를 줄이고 network를 규제하기 위함이지만 그 효과가 적은것으로 알려져있다.
장점: 더 깊은 CNN network를 구현했다. GoogLeNet은 inception module를 sub network로 가지고 있어서 GoogLeNet이 이전의 구조보다 훨씬 효과적으로 parameter를 사용한다. (GoogLeNet은 AlexNet대비 10배 적은 parameter를 가짐)
단점: inception module에서 합성곱 층의 합성곱 kernel 수는 hyperparameter이다. 그래서 inception module이 하나 추가될때마다 hyperparameter가 6개가 추가된다.
VGGNet
단순 + 고전적인 구조이다. 2개 또는 3개의 합성곱 층 뒤에 pooling층이 나오는 형태가 반복된다. VGGNet 종류에 따라 총 16개 또는 19개의 합성곱 층이 있다. 그리고 마지막 fully connected는 2개의 은닉층과 출력층으로 이루어짐. 그리고 많은 개수의 filter를 사용하지만 kernel size는 3by3만 사용한다.
ResNet
더 적은 parameter로 더 깊은 network model을 만드는 trend를 따라서 만들어졌다.
ResNet이 다른 모델 architectuer와 다른점은 skip connection (or shortcut connection)을 활용한다는 것이다. skip connection을 사용하게되면 어떤 층에 주입되는 신호가 상위 층의 출력에도 더해진다. 다음 그림을 보면 입력되는 x가 identity function을 통해 있는 그대로 전달되어서 정상적으로 convolutional layer를 거쳐서 출력되는 F(x)와 함께 통합되는것을 확인할 수 있다.
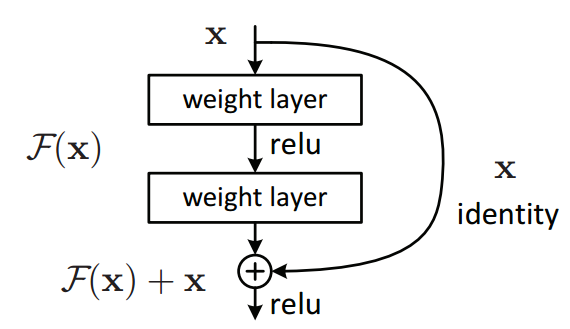
그러면 아래 그림과 같이 network는 convolutional layer을 통해 전해져온 h(x)대신 h(x)와 입력 x사이의 차이를 학습하게 된다. 이런 학습 방식을 잔차 학습이라고 한다.
residual unit
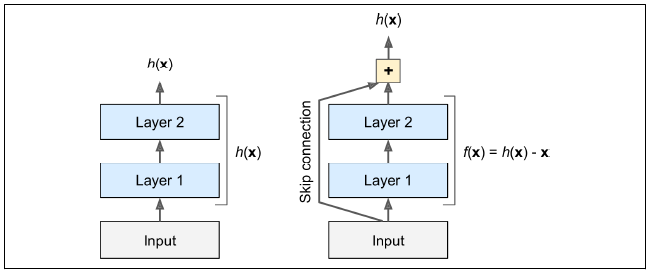
또한, skip connection을 사용하게되면 skip 연결덕분에 입력 신호가 전체 network에 쉽게 영향을 미치기때문에 일부 층이 아직 학습되지 않았더라도 network 훈련을 시작할 수 있다.
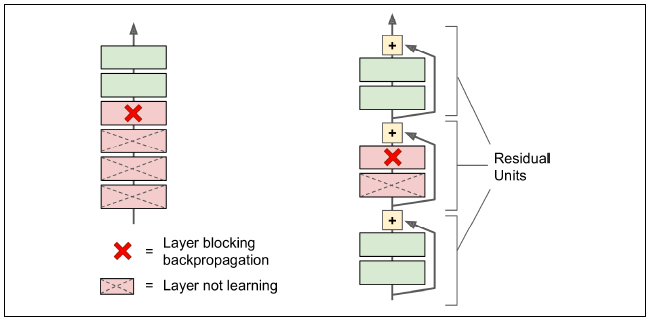
Skip connection이 있는 심층 잔차 network에는 작은 신경망인 residual unit(잔차 유닛)이 존재한다. Residual unit을 가진 ResNet architecture은 다음과 같다:
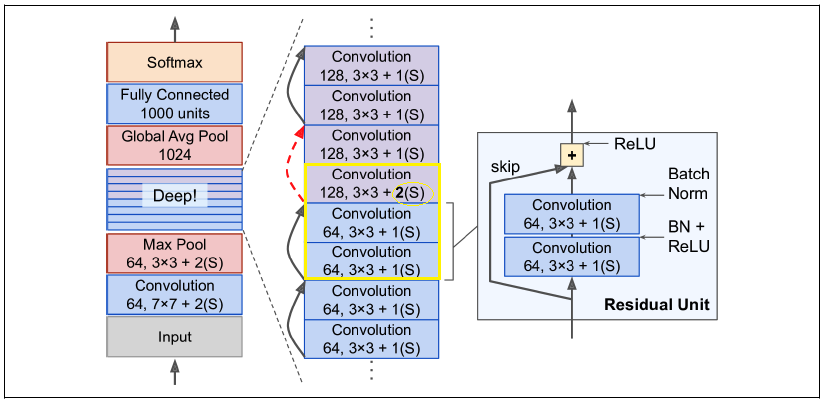
GoogleNet과 똑같이 시작하고 종료한다. 다른점은 중간에 단순한 잔차 unit을 매우 깊게 쌓는것이다. 각 잔차 unit은 BN, ReLU, 3x3 kernel을 사용하고 공간정보를 유지하는 (stride=1, padding=”same”) 두개의 합성곱층으로 이루어져 있다.
특성 map 개수는 몇개의 residual unit마다 두배로 늘어나고, 높이와 너비는 절반이 된다. 높이와 너비가 달라지기때문에 입력이 residual unit에서 출력에 바로 더해질수가 없다. 이 문제는 stride=2 & 출력 특성map의 수가 같은 1x1 합성곱 층으로 입력을 통과시키면서 해결된다.
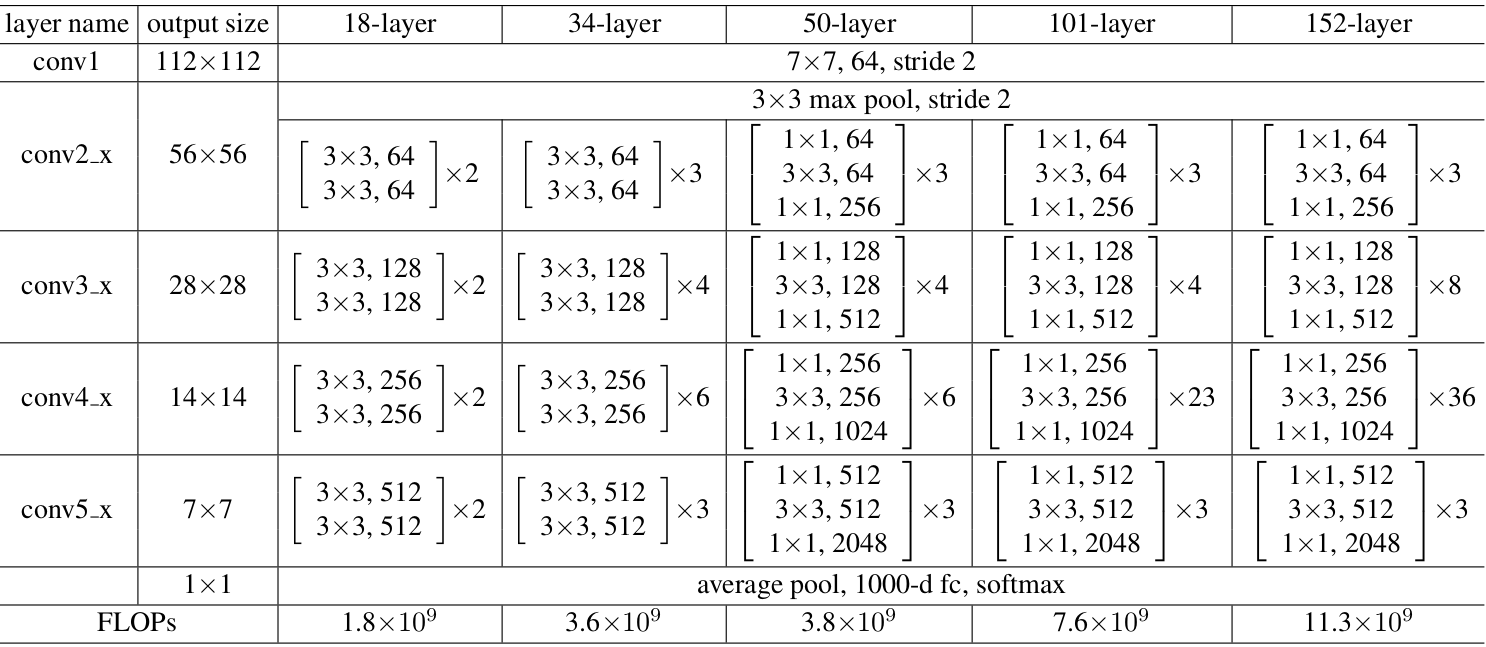
다음 그림과 같이 18, 34, 50, 101, 152 layer를 가진 변종들이 존재한다. ResNet-34는 34개의 층으로 이루어진 ResNet구조이며 합성곱층와 fully connected layers만으로 구성되어있다.
Google의 Inception-4는 GoogleNet과 ResNet를 통합해서 모델 구조를 설계하여 매우 높은 이미지 분류 성능을 확보했다.
Xception (Extreme Inception)
Xception에서는 깊이별 분리 합성곱 층(depthwise separable convolution layer) 방식으로 inception module을 처리한다.
기존 일반적인 convolutional layer는 공간상의 패턴과 channel 사이의 패턴을 모두 동시에 잡기위해 filter를 사용한는데, depthwise separable conv layer는 공간 패턴과 channel 사이 패턴을 따로 분리해서 modeling 할 수 있다고 가정한다. 그래서 다음과 같이 두개의 부분으로 구성된다.
- 하나의 공간 필터를 각 입력 특성 map에 적용해서 합성곱 층을 형성한다. (채널마다 한개의 공간 필터 적용. channel 마다 하나의 공간 필터를 가지기 때문에 (입력층과 같이) channel이 너무 적은 층 다음에 사용하지 말아야 함.)
- channel사이 패턴만 감지한다. (이 layer는 1x1 필터를 적용한 일반적인 합성곱층이다.)
GoogleNet에서 처음 얘기했던 inception module은 공간패턴과 channel사이 패턴을 함께 고려하는 일반적인 합성곱층과 이들을 아얘 따로 고려하는 depthwise separable 합성곱층사이에 중간 형태로 생각하면 된다. 실제로는 depthwise separable conv layer가 더 나은 성능을 보여준다.
SENet (squeeze-and-excitation network)
SENet 모델에서는 다음과 같이 inception module이나 residual module에 SE block을 추가한다.
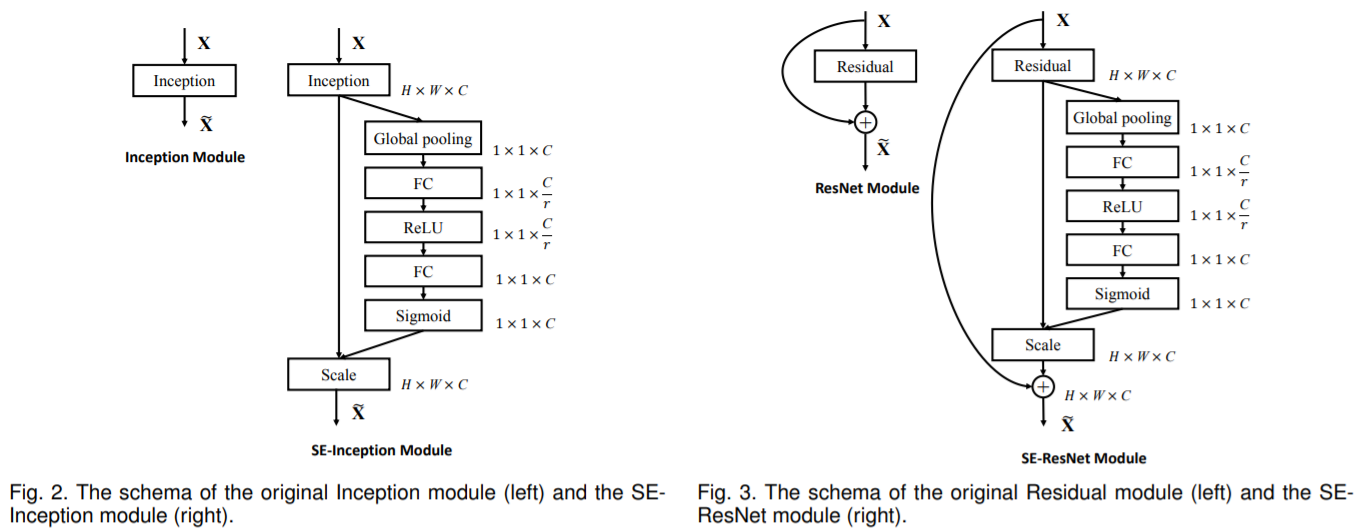
SE block부분이 추가된 부분의 unit의 출력을 (깊이 차원으로) 분석해서 덜 중요한 feature의 활성화정도를 약하게해서 더 중요한 feature의 활성화정도가 더 강해지도록 조정한다. 예를 들어서, SE block이 이미지의 눈, 코, 입을 학습할 수 있는데, 입과 코의 특성 map이 강하게 활성화되고 눈 특성 map은 약한상태라면, 이 SE block이 눈 특성map의 출력을 높여준다. (다른 특성map을 약하게 만들어서 눈 특성map이 더 강하게 활성화되도록함.) 이렇게 특성map을 “보정” 하면서 애매함을 결정하는 역할을 수행한다.
SE block은 3개의 층으로 구성된다 - global average pooling , FC (+RELU), FC (+sigmoid)
global avg pooling 이후 FC 단계에서 저차원으로 압축이 되고, 저차원 vector가 생성되어 특성이 embedding된다. 이 저차원 단계를 통해 SE block이 특성의 조합에 대한 일반적인 표현을 학습하는 것이다. 그 다음, 출력층은 이 임베딩을 받아서 특성 맵마다 0과 1 사이의 하나의 숫자를 담은 보정된 vector를 출력한다. 특성 map과 이 보정된 vector를 곱해서 (“scale”단계) 관련없는 특성값은 낮추고 관련높은 특성값을 (1.0을 곱해서) 그대로 유지한다.
(source: SENet 소개 논문: https://arxiv.org/pdf/1709.01507.pdf)
ResNet-34 구현해보기 (keras sequential model)
main_layer와 skip_layer을 만들어서, strides > 1 일때에, skip_layer을 구현하고, main_layer의 합성곱층을 구현한다.
call()이라는 호출 함수를 하나 정의해서 main_layer와 skip_layer(if any)를 통과 시킨 후 두 출력을 더하고 활성화를 거쳐 residual unit의 출력이 나올 수 있도록 한다.
다음과 같이 ResidualUnit class를 생성해서 residual unit을 하나의 층 처럼 다룰 수 있다.
#residual unit층 만들기
class ResidualUnit(keras.layers.Layer):
def __init__(self, filters, strides=1, activation="relu", **kwargs):
super().__init__(**kwargs)
self.activation = keras.activations.get(activation)
self.main_layers = [
keras.layers.Conv2D(filters, 3, strides=strides,
padding="same", use_bias=False),
keras.layers.BatchNormalization(),
self.activation,
keras.layers.Conv2D(filters, 3, strides=1,
padding="same", use_bias=False),
keras.layers.BatchNormalization()]
self.skip_layers = []
if strides >1 :
self.skip_layers=[
keras.layers.Conv2D(filters, 1, strides=strides,
padding="same", use_bias=False),
keras.layers.BatchNormalization()]
def call(self, inputs):
Z = inputs
for layer in self.main_layers:
Z = layer(Z)
skip_Z = inputs
for layer in self.skip_layers:
skip_Z = layer(skip_Z)
return self.activation(Z+skip_Z)
#residual unit층을 모델 ResNet-34에 더하여 진행하기
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(64, 7, strides=2, input_shape=[224, 224, 3],
padding = "same", use_bias=False))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation("relu"))
model.add(keras.layers.MaxPool2D(pool_size=3, strides=2, padding="same"))
#residual unit을 반복적으로 추가하는 구간
prev_filters = 64 #첫filter는 64개
for filters in [64]*3 + [128]*4 + [256]*6 + [512]*3:
#현 filters개수가 이전 filters개수와 동일할때만 strides=1
strides = 1 if filters == prev_filters else 2
# residual unit 추가
model.add(ResidualUnit(filters, strides=strides))
#filters 계속 update해주기
prev_filters = filters
model.add(keras.layers.GlobalAvgPool2D())
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(10, activation="softmax"))
사전훈련 모델
keras에서 제공하는 사전훈련된 모델을 가져와서 사용할 수도 있다. 사전훈련된 ResNet-50 모델을 로드하는 방법은 매우 간단하다. imagenet dataset으로 사전 훈련된 ResNet-50 모델의 가중치(parameter)가 다운로드 된다.
model = keras.applications.resnet50.ResNet50(weights="imagenet")
ResNet-50 모델은 input 이미지의 크기를 224 x 224 pixel 크기로 생각하고 동작하기때문에 만약 다른 크기의 이미지를 input해야한다면 model의 preprocess_input()함수를 사용해서 이미지를 resize할 수 있다. (가로세로 비율이 유지되는지 확인 필수! 필요시 tf.image.crop_and_resize()함수를 사용하면된다.)
Reference
- Geron, Aurelien. Hands on Machine Learning. O’Reilly, 2019
- Optimizing parameters in CNN: https://www.analyticsvidhya.com/blog/2021/06/create-convolutional-neural-network-model-and-optimize-using-keras-tuner-deep-learning/
- simple explanation on CNN (and related terms): https://shubhamchauhan125.medium.com/a-simple-explanation-to-filters-stride-and-padding-in-cnn-d0236d4a57ef
- what is an inception module: https://paperswithcode.com/method/inception-module#:~:text=An%20Inception%20Module%20is%20an,pass%20onto%20the%20next%20layer
- ResNet model diagrams: https://jason-adam.github.io/resnet50/
- ResNet architecture : https://towardsdatascience.com/a-deeper-dive-into-residual-learning-d92e0aaa8b32 / https://towardsdatascience.com/residual-blocks-building-blocks-of-resnet-fd90ca15d6ec