sQLEAR(speech Quality by machine LEARning)
sQLEAR은 infovista의 voice QOE(Quality of Experience) predictor이며 점차 줄어드는 MNO(mobile network operator)들의 VoLTE 고객들의 needs를 만족시키기위해 개발되었다.
MNO들은 CAPEX/OPEX 최적화를 구현하면서 voice service QOE를 maintain하고, 정확하고, 구현하기 쉽고, 제어된 voice service QOE predictor를 확보해야함.
이전 parametric voice QOE algorithms(ITU-T P.564)은 network parameter들만 사용해서 MOS를 estimate함. (so these solutions are non-intrusive) P.563, P.564는 VoLTE scenario를 평가하기에는 적절하지 못함.
sQLEAR: IP transport과 underlying transport, 그리고 codec and jitter buffer (in the end-user voice client)로 부터 result하여 voice quality에 끼치는 영향을 predict하는 algorithm이다.
(underlying transport란?: packet-based radio and core network parameters. jitter, packet loss, codec information, 등 이 RTP packet information에 포함됨.)
sQLEAR concept
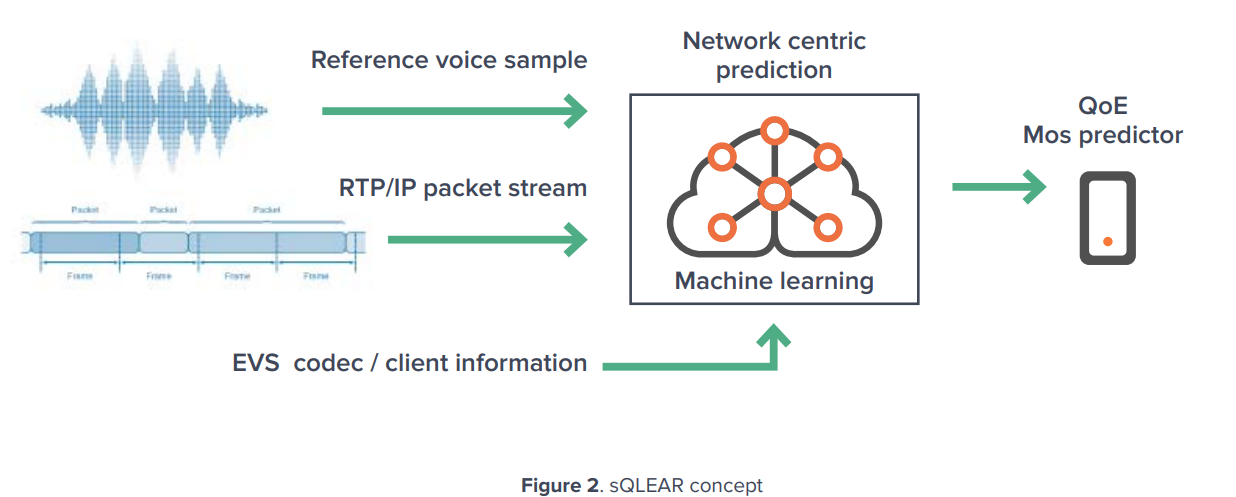
sQLEAR는 resulting degraded speech samples를 사용하지 않고 speech reference samples를 input으로 사용함. (그래서 sQLEAR은 first parametric intrusive voice QoE evaluation algorithm이다.) Parametric intrusive 방식을 사용하기때문에 기존에 다른 solutions에 비해 정확도가 확실하게 높다.
(기존 다른 solutions: existing parametric non-intrusive solutions (ITU-T P.564) and/or perceptual non-intrusive (ITU-T P.563) as well as with competitive performance against intrusive perceptual solutions (ITU-T P.863))
Degraded samples사용하지 않기때문에 background noise, automatic gain control, voice enhancement techniques, and frequency response와 같은 device specific degradations와 characteristics에 해당되지 않는다.
sQLEAR output은 MOS로 define되어 있음. (represents the first outcome from ongoing activities in the P.VSQMTF (Voice Service Quality Monitoring and Troubleshooting Framework) work item from ITU-T Study Group 12)
sQLEAR은 최신 voice services를 위해 설계되었기때문에, High Definition (HD) Enhanced Voice Service (EVS) codec and client (including the channel aware (CA) and Inter- Operability (IO) modes)를 활용하는 VoLTE services의 evaluation을 위해 사용될 수 있다. IO mode가 backwards compatibility with AMR codec를 보장한다.
[참고] what is AMR codec?: AMR stands for Adaptive Multi-Rate Codec. AMR is an audio compressed speech coding algorithm. This coding algorithm operates at 8-bit rates, ranging from 4.75 to 12.2 kbps, and is specially invented to improve robustness. AMR uses various technologies such as ACELP, DTX, VAD, and CNG. Many modern mobile phones use the AMR file format in order to store spoken audio. The common filename extension is .amr. Even, there exist other formats of AMR which can even store videos. In October 1999, AMR was adopted as standard speech codec by 3GPP. [https://www.geeksforgeeks.org/what-is-amradaptive-multi-rate-codec/]
key factors for sQLEAR
- transmitted speech reference
transport protocol information (e.g., jitter, packet loss, codec information inclusing rate and channel-aware mode(EVS codec case))
- prediction algorithm은 DPI(deep packet inspection)을 사용해서 relevant information을 확보함. network이 voice QOE에 주는 영향을 necessity of recording actual speech content 없이도 inspect할 수 있음.
- time characteristics of the reference signals are used to identify importance of individual sections of the bitstream in regard to speech quality –> able to take into account the real voice signal after the jitter buffer 장점이 있음.
sQLEAR의 장점
3 clear advantages of sQLEAR using machine learning:
- complexity of inter-dependencies betwen all network/codec/client parameters as wlel as their significance in impacting the speech quality가 multi-dimensional optimization techniques보다 machine learning이 더 잘 process할 수 있음. parametric voice QOE evaluation algorithm을 위해 필요한 estimation of new coefficient of multi-variable non-linear functions를 ML을 통해 더 잘 할 수 있음.
- ML techniques는 더 flexible해서 any time changes that emerge from introductionof new codecs/clients를 감안해서 더 빠르게 tuning 할 수 있음. This provides a significant advantage from the perspective of implementing the algorithm and ensuring operational efficiency.
- 추가적인 scaling/ calibration이 필요 없음. There is no need for additional calibration to the MOS scale using first or third order polynomials, because the machine learning based algorithm “learns” the precise MOS scale that it needs to predict.
ML techniques
어떤 machine learning technique/ overall process를 사용하는지:
sQLEAR의 learning & evaluation process
EVS VoIP client와 EVS voice codec을 위한 3GPP standardized code를 기반으로한 simulator를 사용하여 sQLEAR가 개발되었음. 이 simulations는 IP level에서 다음 knowledge를 베이스로 수행됨 - knowledge obtained from the analysis of real-life field data, collected during a significant number - and broad diversity - of drive tests in different locations, conditions, and in a number of MNO networks.
The standardized EVS VoIP client ensures that all devices with embedded EVS exhibit the same behavior. 그래서 sQLEAR은 testing에 사용되는 device로부터 독립적이고 transparent함.
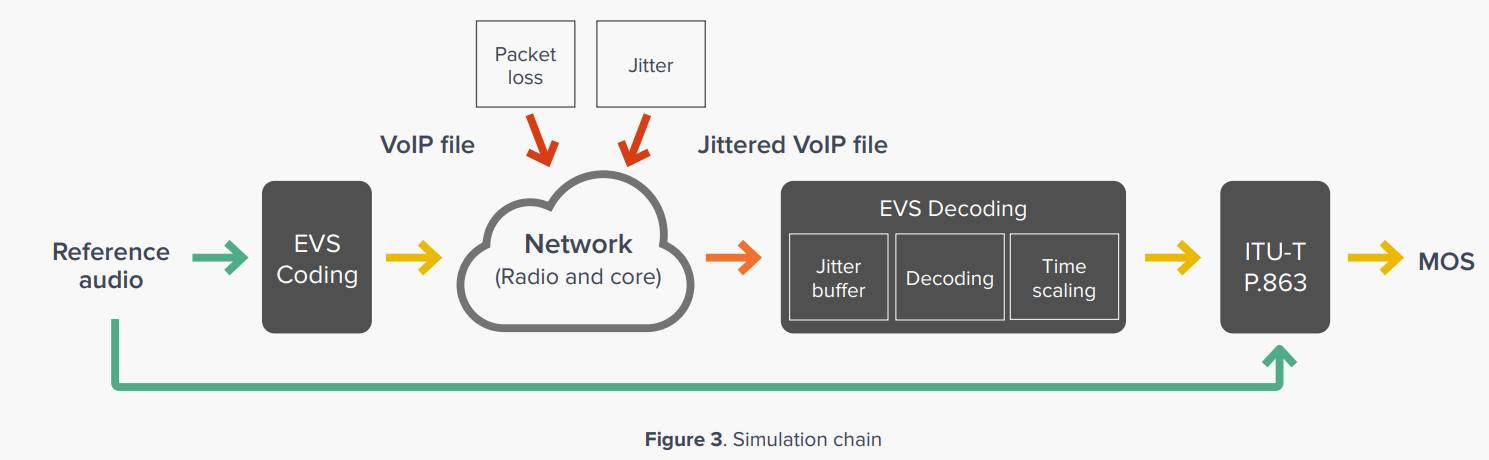
위 simulation chain의 진행과정:
- A reference audio file is injected into the simulation process, and coded with different EVS codec settings for bandwidth, codec rate and channel-aware mode.
- The resulting VoIP file output includes audio packets coded together, with an ideal arrival time increasing by 20ms for each packet.
- Network errors, in the form of jitter and packet loss patterns, are applied to the coded audio to simulate degradations that may occur in an all-IP network.
To simulate the jitter and packet loss behavior of a radio and core network, jitter files are created by using a combination of simulations and drive test data. A large set of databases, spanning approximately 120,000 samples and covering a broad range of conditions that generate voice degradations for the entire voice quality range, have been generated.
By applying the jitter files and simulating network degradations, EVS frames are removed when there is packet loss and the arrival time of the frames are changed relative to the jitter file. The new Jittered VoIP file is then submitted to the EVS jitter buffer. It is decoded and time scaled, which produces a degraded audio file. Finally, the degraded audio file is graded using ITU-T P.863 and compared it to the original reference, resulting in a MOS score.
결과적으로 network condition을 describe하는 각 simulated jitter file은 corresponding degraded audio file과 associated MOS score을 가지고 있다. The 120,000 samples represent the databases used for sQLEAR learning and evaluation, with a 50%-50% split, as recommended by current academic research in machine learning (see “Handbook of Statistical Analysis and Data Mining Applications”, by Elsevier Publisher, 2009)
ML algorithm으로는 combination of bagged decision trees + SVM machine learning algorithm을 활용함.
Parameters
어떤 Parameter를 사용했는지:
sQLEAR은 creation, selection of features를 수행하고, QoE prediction을 perform한다. 사용하는 feature들은 basic network parameter로 부터 aggregate됨.
two sources of features:
- information derived from RTP stream generated by the simulated jitter buffer implementation
- statistical measures built from the RTP stream. proved through extensive testing to have a significant impact on accuracy of the algorithm (compared to ITU-T 863)
important factors that impact the performance of sQLEAR (accuracy of QoE prediction):
- speech content and frequency
duration of silence , distribution of silence within the voice samples
- for further improvement of the performance, audio reference-based features are used
jitter files 가 codec과 reference voice sample로 부터 독립적이게 하기위해서 + feature creation을 간단하게 하기위해서 -> sQLEAR은 다음과 같은 pre-processing operation을 수행한다:
- DTX cleaning
- addition of codec information(e.g., rate, mode, 등)
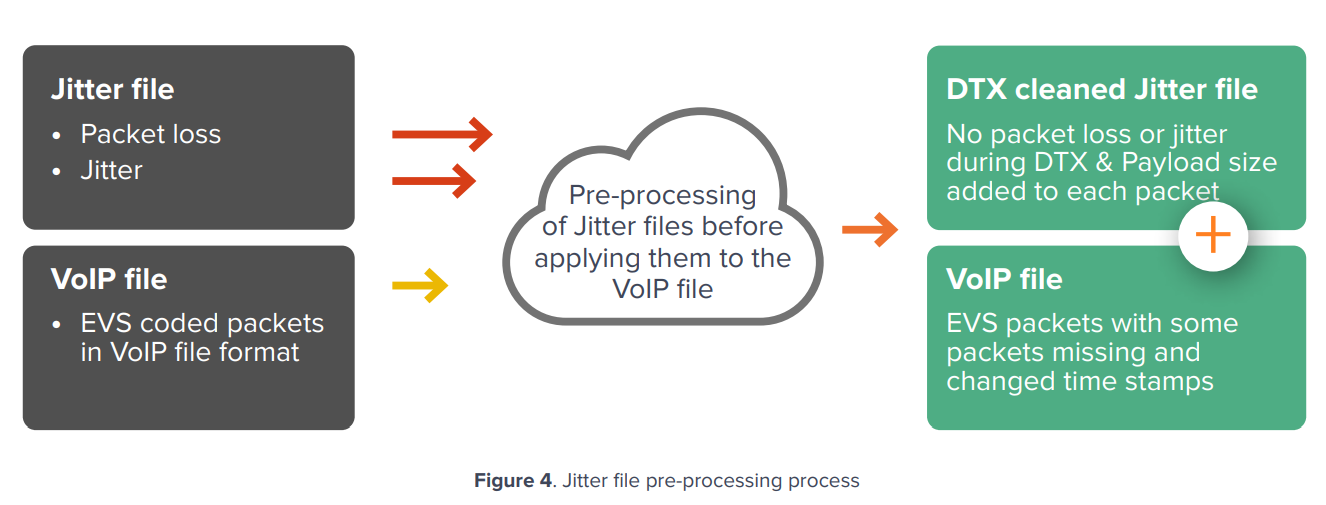
preprocessing의 output은 새로운 “DTX-cleaned” jitter file이고 codec audio payload size와 Channel Aware mode data를 포함하고있다.
Applications
How sQLEAR runs in the field:
ITU-T requirements를 충족해야함. the test set-up and run-time/ measurement scheme은 다음과 같다:
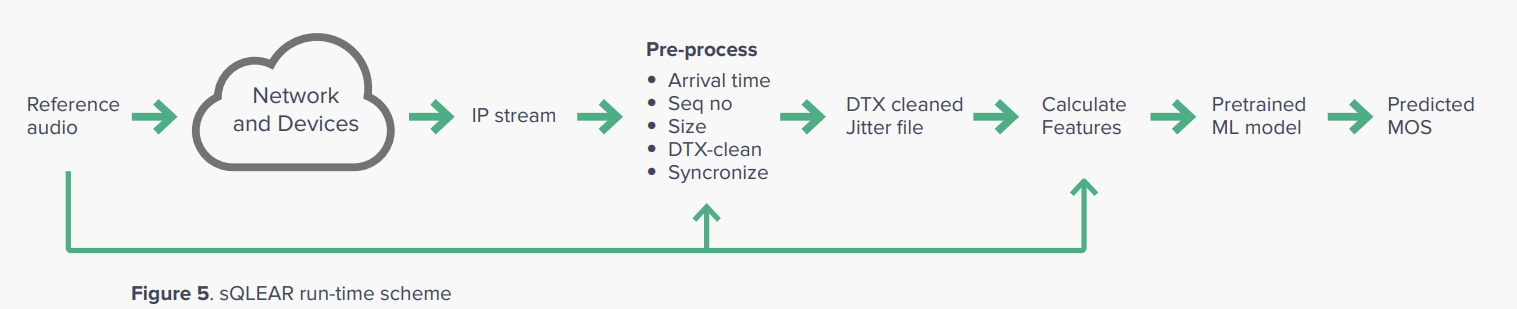
In order to ensure the best performance of the predictor against ITU-T P.863, some specifics need to be considered:
reference voice samples:
preprocessing during run-time:
다른 언어에도 sQLEAR의 적용이 가능할지?
현재는 British & American English만 trained & validated 완료된 상태임. 그러나 sQLEAR algorithm은 보다 쉽게 trained & adapted될 수 있다.
addition of new languages requires only a brief temporal analysis of the reference voice file and the subsequent learning of the algorithm.
sQLEAR does not use the audio path, but rather only the time structure of the reference signal for identifying the importance of individual sections of the bitstream in regard to speech quality, as well as for the creation of reference based machine learning features.
sQLEAR의 정확도 (accuracy)?
more than 96% correlation and prediction errors (rmse) lower than 0.26MOS across all evaluation databases (60,000 samples)
다른 voice QoE solution과 비교해서 sQLEAR의 다른점?
sQLEAR is neither solely speech-based, like perceptual intrusive and non-intrusive algorithms (e.g. ITU-T P.863, P.563), nor solely parametric based and non-intrusive such as ITU-T P.564
sQLEAR is leveraging network/codec/client parameters and the reference speech sample.
같은점?
sQLEAR와 ITU-T P.863 모두 class of instrusive voice quality이다.
Both ITU-T P.863 and sQLEAR support VoLTE services evaluation and are part of ITU work. sQLEAR is based on the ongoing ITU work item, ITU-T P.VSQMTF “Voice service quality monitoring and troubleshooting framework for intrusive parametric voice QoE prediction”
Reference
- what is sQLEAR(white paper) : https://www.infovista.com/sites/default/files/resources/wp_infovista_new-approach-for-Testing-Voice-Quality-sQLEAR_0.pdf