Video Quality Assessment paper review
주요 papers:
- Quality Assessment of In-the-Wild Videos by Dingquan Li (2019)
- KonVid-150k: A Dataset for No-Reference Video Quality Assessment of Videos in-the-Wild by Franz Götz-Hahn (Mar 2021)
- UGC-VQA: Benchmarking Blind Video Quality Assessment for User Generated Content by Zhengzhong Tu (Apr 2021)
- RAPIQUE: Rapid and Accurate Video Quality Prediction of User Generated Content by Zhengzhong Tu (Nov 2021)
- Study on the Assessment of the Quality of Experience of Streaming Video by Aleksandr Ivchenko (2020)
Quality Assessment of In-the-Wild Videos
Pytorch를 통해 model을 구현했고 source code는 https://github.com/lidq92/VSFA
computational efficiency - 저자의 실험 환경= Intel Core i7-6700K CPU@4.00 GHz, 12G NVIDIA TITAN Xp GPU and 64 GB RAM in Ubuntu 14.04
No Reference Image and Video Quality Assessment 기법들 (설명: https://live.ece.utexas.edu/research/Quality/nrqa.htm)
BRISQUE(blind/referenceless image spatial quality evaluator) - use scene statistics of locally normalized luminance coefficients to quantify possible losses of “naturalness” in the image due to the presnce of distortions, leading to a holistic measure of quality
관련 논문: https://live.ece.utexas.edu/publications/2012/TIP%20BRISQUE.pdf
NIQE(Natural Image Quality Evaluator) - completely blind image quality analyzer that only makes use of measurable deviations from statistical regularities observed in natural images, without training on human-rated distorted images, and, indeed without any exposure to distorted images.
CORNIA(Codebook Representation for No-Reference Image Assessment) -
unsupervised feature learning 방식으로 human perceived image quality 를 예측하는 model. computationally efficient- how? used soft-assignment coding with max pooling to obtain effective image representations for quality estimation. 더 상세한 내용은 아래 논문 읽어봐야함.
VIIDEO(video intrinsic integrity and distortion evaluation oracle) - embodies models of intrinsic statistical regularities that are observed in natural vidoes, which are used to quantify disturbances introduced due to distortions. An algorithm derived from the VIIDEO model is thereby able to predict the quality of distorted videos without any external knowledge about the pristine source, anticipated distortions, or human judgments of video quality.
관련 논문: https://live.ece.utexas.edu/publications/2016/07332944.pdf
VBLIINDS(Video BLIINDS) - non-distortion specific 방식이다. This approach relies on a spatio-temporal model of video scenes in the discrete cosine transform (DCT) domain, and on a model that characterizes the type of motion occurring in the scenes, to predict video quality. The video quality assessment (VQA) algorithm does not require the presence of a pristine video to compare against in order to predict a quality score. The contributions of this work are three-fold.
BLIINDS (BLind Image Integrity Notator using DCT-Statistics) -
DIIVINE (Distortion Identification-based Image Verity and INtegrity Evalutation)
연구된 타 model: (2019) https://link.springer.com/content/pdf/10.1007/s11760-019-01510-8.pdf 그 외 매우 다양한 새로운 모델들이 개발되고 있다.
새로운 video quality assessment model을 제시함. human visual system (HVS)를 기반의 content-dependency와 temporal-memory effect 요소가 video quality assessment에 끼치는 영향을 고려하여 deep learning model을 설계함.
- content dependency - pre-trained image classification neural network (inherent content-aware property를 가진)
- temporal-memory effect - temporal hysteresis와 같은 요소가 포함된 long-term dependencies를 network에 GRU(gates recurrent unit) & subjectively-inspired temporal pooling layer와 함께 integrate했음.
저자의 model을 주요 video databses (: KoNViD-1k, CVD2014, and LIVE-Qualcomm)로 훈련시켜서 assessment 결과를 SROCC, KROCC, PLCC, RMSE 값으로 평가함.
다른 주요 video quality assessment model(BRISQUE, NIQE, CORNIA, VIIDEO, VBLIINDS)과 함께 평가 결과를 비교하여 저자의 model의 월등히 우수하다는 것을 확인함.
content effect
같은 compression ratio로 compress된 두개의 video이지만 다른 content를 가지고있다면 각자 다른 subjective quality 평가 결과를 얻은 결과를 보면, video 속의 scene/object categories가 사람이 평가하는 visual quality에 영향을 준다는 것을 확인할 수 있다.
In order to verify, 저자가 소규모로 side study를 진행함 - We ask 10 human subjects to do the cross-content pairwise comparison for 201 image pairs. More than 7 of 10 subjects prefer one image to the other image in 82 image pairs. For illustration, two pairs of in-the-wild images are shown in Figure 1. Each image pair is taken in the same shooting conditions (e.g., focus length, object distance). For the in-focus image pair in the first row, 9 of 10 subjects prefer the left one. For the out-of-focus image pair in the second row, 8 of 10 subjects prefer the left one to the right one. The only difference within a pair is the image content, so from our user study, we can infer that image content can affect human perception on quality assessment of in-the-wild images. We also conduct a user study for 43 video pairs, where every two videos in a pair are taken in similar settings. Similar results are found that video content could have impacts on judgments of visual quality for in-the-wild videos.
content-aware feature를 활용한 다른 참고 cases -
- handcrafted content-relevant features를 extract해서 현재 존재하는 quality measures를 tune했다. - Jaramillo et al[13]
- pre-trained image classification network의 top layer에서부터 semantic 정보를 활용해서 traditional quality features에 incorporate했다. -Siahaan et al[41] & Wu et al[49]
- multiple patch들의 deep semantic feature aggregation을 활용해서 image quality assessment를 수행했다. -Li et al[17]
–> image classification tasks에 pre-trained된 CNN으로 부터 content-aware feature extraction을 수행했다. CNN classification model들은 방대한 content 정보를 discriminate할 수 있다. Predicted image/video quality의 content-dependency에 대응하기 위해 content-aware feature들을 활용하고 결국 objective models의 성능을 향상시킬 수 있다.
–> 여기에서 참고한 다른 case들을 통해 deep semantic feature들은 content가 quality assessment task에 주는 영향을 완화 (“alleviates the impact”) 시켜준다는 것을 알게되었다. 그래서 pre-trained image classification network을 사용해서 content-aware feature extraction을 활용하기로 했다. 이 저자는 다른 참고 case들 과는 다르게 feature들을 extract했다. whole frame을 network에 feed하고, global average pooling 외에도 global standard deviation pooling을 함께 output semantic feature maps에 적용했다. VQA task이 최종적으로 구현하려는 목적이기때문에, we further put forward a new module for modeling temporal characteristics of human behavior when rating video quality.
temporal effect
temporal memory - human judgements of video quality are affected by their temporal memory. 현재 frame에 대한 judgements는 이전 frame으로부터 받은 information으로 영향을 받게된다. “temporal hystersis”라고도 불리는 영향은 이전 frame들의 quality가 poor했다면, 이 후 더 나은 quality로 개선되어도 나쁜 quality가 한동안 기억되어 user의 quality assessment에 영향을 끼친다. 현 model에서는 이런 temporal effect를 taking to account 하고 있음.
간단한 average pooling 전략으로는 video의 quality를 overestimate하는 경향이 있다. in-the-wild video는 synthetically distorted video보다 더 temporally heterogeneous한 distortions를 가지고있기때문에 사람이 평가하는 in-the-wild video들의 visual quality에 hysteresis effect가 더 강하게 reflect된다.
–> GRU(gated recurrent unit)를 통해 long-term dependencies를 modeling하고 frame quality를 예측했다. 그리고 마지막으로 temporal hysteresis effect를 가만하기 위해 differentiable subjectively-inspired temporal pooling model을 제안하고 이를 network에 하나의 층으로 embed해서 overall video quality를 output했다.
–> 저자가 구현한 VQA field에서의 temporal modeling은 다음 두 가지 aspect로 보열질 수 있다 - feature aggregation & quality pooling.
feature aggregation:
most methods aggregate frame-level features to video-level features by averaging them over the temporal axis. 1D convolutional netural network to aggregate the primary features for a time interval. 저자는 GRU network를 사용해서 feature integration을 위한 long-term dependencies를 model했다.
quality pooling:
simple average pooling strategies를 여러 방법을 통해 adopt했다. several pooling strategies considering the recency effect or worst quality section influence가 다른 연구 cases에서 논의되었다. 또 다른 연구 case에서는 CNAN(convoutional neural aggregation network) for learning frame weights가 adopt되었고 weighted average of frame quality scores를 통해 overall video quality를 계산했다. Temporal hyteresis effect에 대응하기위해 Seshadrinathan and Bovik[37]이 temporal hysteresis pooling strategy를 제안했다. 이 방법은 관련 다른 연구 cases를 통해 effective한것으로 확인되었지만, differentiable하지 않기때문에 저자는 새로운 방식을 제안했다 - new one with subjectively-inspired weights which can be embedded into the neural network and be trained with back propagation.
overall model architecture
저자가 제안하는 overall model architecture는 다음과 같이 크게 두 개의 module로 구성되어있다:
- pre-trained CNN with effective global pooling(GP) serving as a feature extractor for each video frame. extract된 content-aware feature들은 fully-connected(FC)층으로 전송되어서 dimensional reduction이 수행된다.
- modeling of temporal-memory effects
- GRU network for modeling long-term dependencies. GRU는 frame-wise quality scores를 output한다.
- overall video quality is pooled from these frame quality scores by subjectively-inspired temporal pooling layer in order to account for temporal hysteresis effects
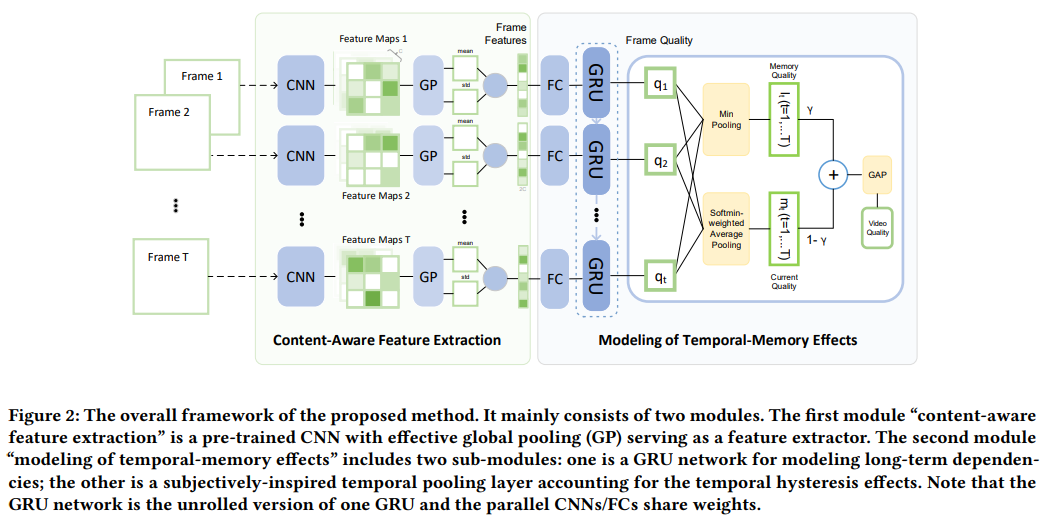
각 module 상세 내용:
1. content aware feature extraction
다른 video content/ scene마다 각각 다른 complexities of distortions, human tolerance thresholds for distortions, and human preferences가 존재한다. 그래서 distortion sensitive한 feature 뿐만이 아니라 content-ware한 feature들을 추출해서 model을 학습시켜야 한다.
ImageNet에서 pretrained된 CNN을 기반의 image classification model은 다른 content 정보를 분별할 수 있는 discriminatory power를 가지고있기때문에 ResNet과 같은 model들로 부터 extract한 deep feature들은 content-aware한것으로 판단된다. deep feature들은 또한 distortion-sensitive하기 때문에 it’s reasonable to extract content-aware preceptual features from pre-trained image classification models.
2. modeling temporal-memory effects
- long-term dependencies modeling:
먼저 feature integration aspect로, GRU network을 adopt해서 long-term dependencies를 modeling한다. GRU의 장점은 feature을 integrate하는 동시에 long-term dependencies를 학습할 수 있다는것이다. GRU를 활용해서 content-aware perceptual feature들을 integrate하고 frame-wise quality scores를 예측한다.
먼저 content-aware feature들은 high dimension이기때문에 GRU training에 바로 사용되기 어렵다. 그래서 dimension reduction을 먼저 수행 한 뒤에 GRU로 전송한다. FC layer를 통해 dimension reduction을 진행한다.
- subjectively-inspired temporal pooling:
참고한 연구 case에서는 hysteresis effect를 가만하기 위해 다음과 같이 define했다. [Kalpana Seshadrinathan and Alan C Bovik. 2011. Temporal hysteresis model of time varying subjective video quality. In ICASSP. IEEE, 1153–1156]
Seshadrinathan의 temporal pooling은 NR-VQA model에는 그대로 적용될 수 없다 - 해당 model은 reliable frame quality score가 input으로 필요하다. 그리고 해당 model은 current quality element의 definition대로 sort-order-based이기때문에 differentiable하지 않다.
NR-VQA와 같은 문제에서는 overall subjective video quality만 access하기때문에 frame-level supervision없이 neural network학습이 진행되어야한다. 그래서 sort-order-based weight function을 differentiable weight function으로 대신한다.
memory quality element = minimum of the quality scores over the previous frames (몇개의 previos frames를 상대로 minimum quality score를 찾을지는 hyperparameter tau로 지정가능한다.)
current quality element = sort-order-based weighted average of the quality scores over the next frames. current quality element를 계산할때에 더 큰 weights를 worse quality frames에 배정한다. (drop in quality는 빠르게 인지하고 improvement in quality에는 느리게 반응하는 “temporal hysteresis”를 반영하기위해) 몇개의 next frame을 고려할지는 hyperparameter tau로 지정가능하다. 여기에서 설정되는 weight는 differentiable softmin function이다(a composition of the negative linear function and the softmax function)
overall quality score = weighted average of the memory and current element. 먼저 subjective frame quality score q_t는 memory quality and current quality elements를 linearly combine해서 계산한다. 그리고 overall video quality Q는 temporal global average pooling(GAP)을 통해서 계산한다.
q_t를 계산할때에 hyperparameter gamma를 설정해서 memory와 current elements가 각각 contribute하는 정도를 제어할 수 있다.
model 구현
ResNet-50를 사용했고, dimension of feature vector은 4096이며, long-term dependencies FC layer가 4096을 128로 feature dimension을 축소시킨후, single layer GRU network와 연결된다. (hidden size=32) 그후 연결되는 subjective temporal pooling layer에서 hyperparameter tau는 12, gamma는 0.5로 설정되었다. 나머지 hyperparameter로는 L1 loss, Adam optimizer(learning rate=0.00001)와 훈련 시 batch size=16이 사용되었다.
experiment
database -
총 4개의 database가 사용됨 -
LIVE Video Quality Challenge Database (LIVE-VQC) [42]
Konstanz Natural Video Database (KoNViD-1k) [12]
1,200 videos of resolution 960 x 540
videos ar 8 sec long with 24/25/30fps
MOS range: 1.22 ~ 4.64
LIVE-Qualcomm Mobile In-Capture Video Quality Database (LIVE-Qualcomm) [10]
208 videos of resolution 1920x1080 captured by 8 diff smart-phones and models 6 in-capture distortions (artifacts, color, exposure, focus, sharpness and stabilization)
videos are 15 sec long with 30fps
MOS range: 16.56 ~ 73.64
Camera Video Database (CVD2014) [31]
234 videos of resolution 640x480 / 1280x720 recorded by 78 diff cameras
videos are 10~25 sec long with 11~31fps (이정도면 wide range of time span and fps임.)
MOS range: -6.50 ~ 93.38
평가지표 (evaluation criteria)
다음 4 가지 performance criteria를 사용 함.
Spearman’s rank-order correlation coefficien (SROCC)
Kendall’s rank-order correlation coefficient (KROCC)
Pearson’s linear correlation coefficient (PLCC)
Root mean square error (RMSE)
SROCC와 KROCC는 prediction monotonicity를 가르키고, PLCC와 RMSE는 prediction accuracy(정확도)를 표현한다. 더 좋은 VQA method일수록 더 높은 SROCC/KROCC/PLCC 값과 더 낮은 RMSE값을 가져야 함.
video의 objective score(VAQ method로 예측한 quality score)가 다른 scale이 subjective score들과 다른 scale이라면, VQEG(Video Quality Experts Group)이 제안한 방식으로 PLCC와 RSME 값을 계산한다. four-parameter logistics function을 adopt해서 objective score o를 subjective score s로 mapping한다.
A Dataset for No-Reference Video Quality Assessment of Videos in-the-Wild
왜 Konstanz Natural Video Quality Database?
Konstanz Natural Video Quality Database (KoNViD-1k) is the only publicly available database that contains sequences with authentic distortions.
논문의 저자는 KonVid-150k라는 새로운 dataset을 만들었다. this dataset consists of coarsely annotated set of 153,841 videos (각 five quality ratings가진) and 1,596 videos (각 최소 89 ratings가진)
저자는 새로운 VQA 방식을 제안한다 - MLSP-VQA relying on multi-level spatially pooled deep features(MLSP) 이 방식은 기존 deep transfer learning 방식보다 큰 scale에서 훈련을 진행하는데에 더 특화되어있다. 저자가 제안하는 방식 중에 MLSP-VQA-FF가 KoNViD-1k dataset으로 평가했을때에 0.82수준의 가장 좋은 SRCC(Spearman rank-order correlation coefficient)를 보여주었다.
MLSP-VQA models trained on KonVid-150k sets the new state-of-the-art for cross-test performance on KoNViD-1k, LIVE-VQC, and LIVE-Qualcomm with a 0.83, 0.75, and 0.64 SRCC, respectively.
Benchmarking Blind Video Quality Assessment for User Generated Content
UGC(User-Generated-Content)가 폭발적으로 많아지고있다. 정확한 video quality assessment(VQA) model를 통해서 UGC/consumer video를 monitor, control, optimize해야 한다. Blind quality prediction of in-the-wild videos is quite challenging, since the quality degradations of UGC videos are unpredictable, complicated, and often commingled.
저자는 이런 challenege에 대응할 수 있는 blind video quality asssessment model을 만들었다. 먼저 주요 no-reference/ blind video quality assessmnet (BVQA) features와 model를 fixed evaluation architecture를 기반으로 평가해서 전반적인 VQA의 발전 현황을 분석했다. 그리고 subjective video quality studies와 objective VQA model design에 대해 새로운 empirical insights를 찾아냈다.
새로운 BVQA model을 만들어냈다. BVQA models에 feature selection 전략을 적용해서 기존 methods에 존재하는 763개의 statistical features 중 60개를 선별해서 새로운 fusion-based model을 만들고 이것을 VIDeo quality EVALuator (VIDEVAL)이라는 이름을 붙였다. 이 model은 VQA performance와 efficiency사이의 trade off를 balance한다. 실험을 통해서 다른 주요 model 대비 computational cost는 적지만 높은 수준의 performance를 확보할 수 있다는 것을 확인했다.
Our study protocol also defines a reliable benchmark for the UGC-VQA problem, which we believe will facilitate further research on deep learning-based VQA modeling, as well as perceptually-optimized efficient UGC video processing, transcoding, and streaming.
source code: https://github.com/vztu/VIDEVAL
논문이 주요 구성:
- 가장 최신 large-scale UGC-VQA databases의 review 및 analysis
- Blind VQA model의 발전 과정 review
- 저자가 새롭게 제안하는 VIDEVAL model
- VIDEVAL의 성능과 결론
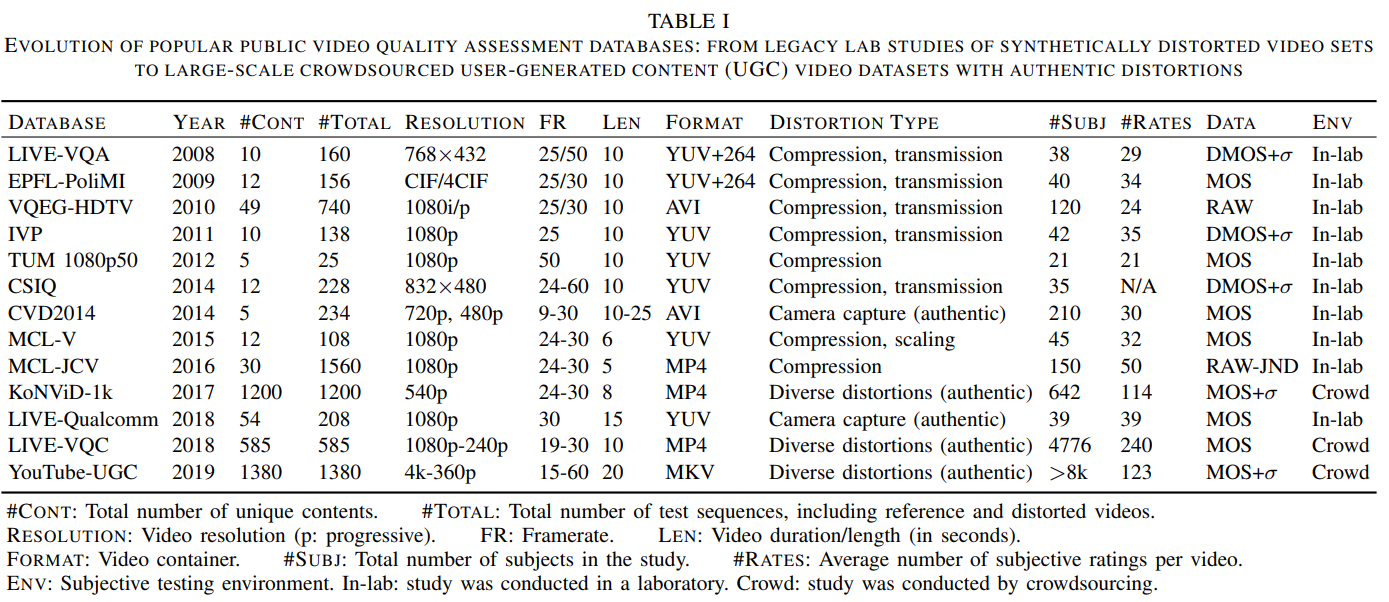
주요 public VQA databases (인위적으로 단순 distortion만 구현한 “legacy” database에서 부터 authentic한 distortion이 구현된 crowdsourced user-generated content(UGC) video dataset 까지)
content diversity & MOS distribution
content diversity를 characterize하기 위해, spatial activity, temporal activity, colorfulness에 관련된 low-level attribute을 사용했다 - brightness, contrast, colorfulness, sharpness, spatial information(SI), temporal information(TI) 이런 attribute들을 통해서 a larger visual space in which to plot and analyze content diversities of the three UGC-VQA databases 제공한다.
또한, 각 database의 content diversity는 이 attribute들을 기반으로 계산된 range와 uniformity로도 표현된다.
위 3개의 database의 주요 특성을 뽑아보면:
brightness vs. contrast
KoNViD-1K와 YouTube-UGC는 비슷한 coverage를 가지고있다. LIVE-VQC는 이 둘 사이의 중간정도이다.
colorfulness
KoNViD-1K가 더 높은 점수를 보여준다.
sharpness & SI
KoNViD-1K는 낮은 점수쪽에 집중되어있고, YouTube-UGC가 가장 넓게 퍼져있다
TI & deep feature graphed using tSNE
위 3개의 database로 부터 4,096 dimensional VGG19 deep feature들을 추출해서 t-SNE를 통해 2D subspace에 embed한 결과를 보면, KoNViD-1K와 YouTube-UGC가 LIVE-VQC대비 feature space에서 더 넓게 퍼져있어서 더 큰 content diversity difference를 가지고 있다.
Blind VQA model의 발전 과정 review
conventional feature-based BVQA models –> deep CNN-based BVQA models
conventional feature-based BVQA models
기존에는 blur, blockiness, ringing등과 같이 특정 distortion type을 assess하는 BVQA model들이 처음 등장했지만, learning-based model들로 발전했다. Learning-based model들은 feature selection과정과 machine learning regression을 통해 더 “versatile”하고 generalizable하게 되도록 개선되엇다.
NSS(natural scene statistics)를 기반으로 개발된 모델들이 있는데, these models are based on algorithms that deploy perceptually relevant, low-level features based on simple, yet highly regular parametric bandpass models of good quality scene statistics.
주요 learning-based BQVA models:
BRISQUE [38, ““No-reference image quality assessment in the spatial domain” by A. Mittal (2012)]
GM-LOG [57, “Blind image quality assessment using joint statistics of gradient magnitude and laplacian features” by Bovik (2014)]
HIGRADE [40, “No-reference quality assessment of tone-mapped HDR pictures” by D. Kundu (2017)]
FRIQUEE [“Perceptual quality prediction on authentically distorted images using a bag of features approach” by Bovik at UT Austin(2017)]
CORNIA [“Unsupervised feature learning framework for no-reference image quality assessment” by P. Ye (2012)]
TLVQM-Two level video quality model[“Two-level approach for no-reference consumer video quality assessment” by J. Korhonen (2019)] <– two-level feature extraction mechanism을 통해서 carefully-defined impairment와 distortion관련 feature들을 추출해낸다.
deep CNN-based BVQA models
주요 구현 방식:
- patch-wise training using global scores
- pretraining deep nets on ImageNet, then fine-tuning
주요 models:
DeepVQA - learn spatio-temporal visual sensitivity maps using deep CNN and convolutional aggregation network [Deep Video quality assessor: from spatio temporal visual sensitivity to a convolutional neural aggregation network by Kim (2018)]
V-MEON - uses multi-task CNN framework which jointly optimizes a 3D-CNN for feature extraction and a codec classifier using a fully-connected layers to predict video quality [“End-to-End Blind Quality Assessment of Compressed Videos Using Deep Neural Networks” by W. Liu (2018)]
leveraging transfer learning to develop general-purpose BVQA framework based on weakly supervised learning and a resampling strategy [“Blind video quality assessment with weakly supervised learning and resampling strategy” by Y. Zhang]
VSFA - apply pre-trained image classification CNN as a deep feature extractor and integrate the frame-wise deep features using a GRU and subjectively inspired temporal pooling layer [Quality Assessment of In-the-Wild Videos by Dingquan Li (2019)]
VIDEVAL model
feature selection과 machine learning algorithm을 통해 blind VQA를 구현하는 여러 주요 모델들의 feature들을 활용해서 하나의 통합적인 모델은 만든것이 이 저자가 만든 VIDEVAL 모델의 형태이다. 저자는 각 모델에서 추출한 feature들이 statistics of the signal in different perceptual domains를 표현한다고 생각하고, BVQA 모델들의 fusion이 subjective assessment에 대한 더 좋은 consistency와 다른 여러 database에도 더 reliable한 performance를 만들어 줄 것이라고 판단했다.
feature extraction
top performing BVQA model들의 feature들을 모두 모으면 다음과 같이 763개의 feature들이 확보된다.

feature selection
model based feature selector - machine learning algorithm을 통해 중요한 feature을 선별한다.
먼저 random forest model을 통해 regression model을 fit해서 permutation importance 순서로 significance가 가장 낮은 feature들을 제거했다. 그 다음 linear kernel로 SVM을 훈련해서 feature들의 순위를 매겼다.
greedy search approach를 통해서 good feature subset을 구할 수도 있다. employed Sequential Forward Floating Selection (SFFS), and used SVM as the target regressor with its corresponding mean squared error between the predictions and MOS as the cost function. The mean squared error is calculated by cross-validation measures of predictive accuracy to avoid overfitting.
RAPIQUE: Rapid and Accurate Video Quality Prediction of User Generated Content
by Zhengzhong Tu (Nov 2021)
implemented in MATLAB (source code available in .mat extension) source code: https://github.com/vztu/RAPIQUE
새롭게 개발한 efficient BVQA 모델을 제안한다. (written in MATLAB)
다음 그림과 같이 two branch framework 형태의 구조로 quality-aware low-level NSS features와 high-level semantic-aware CNN features를 통합했다.
NSS features operate on higher-resolution spatial and temporal bandpass feature maps, while the CNN feature extractor is applied on a resized low-resolution frames for practical considerations. Then sparse frame sampling strategy를 사용해서 runtime을 더 가속화할 수 있도록 features를 extract했다.
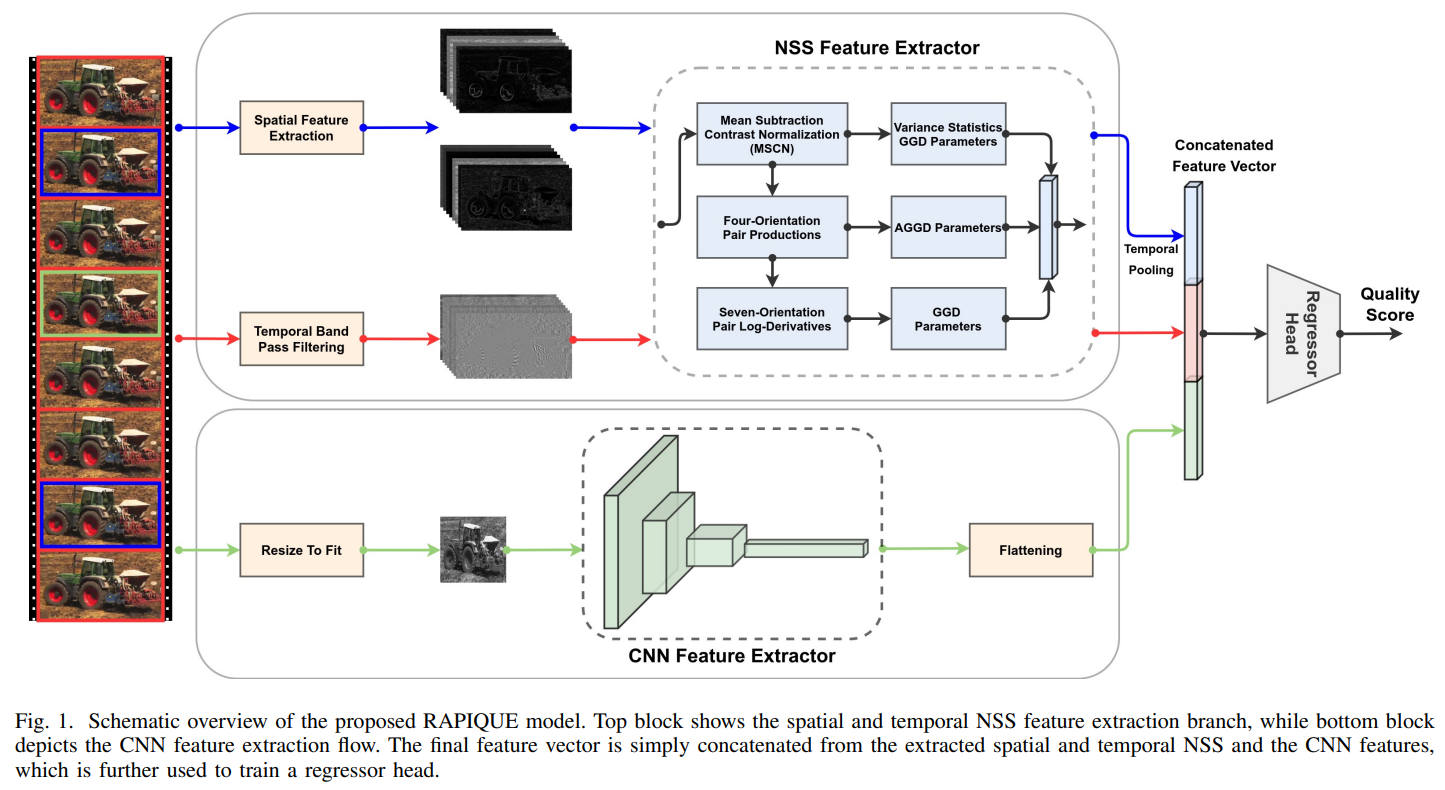
Study on the Assessment of the Quality of Experience of Streaming Video
Zhengfang Duanmu group의 연구 결과에 더해서 experiment를 진행 함.
the main problem of previous studies was insufficient data sets & not consistent with the actual behavior of the network & the distortion introduced was too artificial. SqoE-III database가 사용되었었는데, 이 database에도 문제가 많음.
이 논문의 저자는 이번 연구에서:
- analyzed the influence of classic and handcrafted metrics on QoE
- investigated the dependence of MOS curve on the integral indicator of objective quality
- propose several variants of objective assessment models for VQA
current state of art of VQA:
PSNR(peak signal to noise ratio) is commonly used to quantify reconstruction quality for images and video subject to lossy compression.
Signal-based models use only decoded signal to estimate quality. they are based on an estimate of distortion of signal passing through an unknown system and has 3 types: FR(full reference), RR(reduced reference), NR(no reference)
-FR: input signal(reference video)에 대한 모든 정보가 필요하다. frame by frame comparison을 계산한다. (this class includes MSE, PSNR, HVS-PSNR SSIM, MS-SSIM, and ITU-T recommendations)
-RR: - input system infortmaion의 부분만 필요하다. (this class includes ITU-T J.246 recommendation)
-NR: - 이 mode는 system의 input information에 의존하지 않고 received signal에만 기반한다. (this class includes DIIVINE, BRISQUE, BLINDS, NIQE)
Parametric models - bases on network layer, and is called QoS-metrics. video playback에 대해서는 정보는 없고, packet headers의 정보(delay, jitter, packet loss and others)가 필요하다.
Bitstream models- takes into account the encoded bit streamed packet layer 정보. features such as bitrate, framerate, quantization parameter (QP), PLR, motion vector, macroblock size(MBS), DCT coefficients 등이 extract되어서 model의 input으로 사용된다.
Hybrid models - 위 3 가지 모델을 혼합함. 그래서 가장 effective하다.
overview of the database(SqoE-III)
저자는 SqoE-III database의 content, description of metrics(attributes), MOS에 주는 영향을 분석하고, reference video의 name, FPS, SI, TI, description을 확보했다.
SI=spatial information - 동일 프레임 내에서 pixel들의 변화 정도로 수치가 높을 수록 frame내에서의 변화가 큼을 의미함.
TI=temporal information - 영상 안에서의 시간벅 변화로 이전프레임과 현재 프레임에서의 픽셀값의 차이. 수치가 낮을 수록 시간별 프레임 값의 변화가 적음을 의미함.
standard quality metrics: 각 항목의 p-value & SRCC(Spearman’s rank correlation coefficient) 사용
- initial buffer time (seconds): time from the start of playback initialization to the start of video rendering on the user side.
- rebuffer percentage: ratio of the total duration of stalling events to the total playback time
- rebuffer count: the number of rebuffering events
- average rendered bitrate (kbps)
- bitrate switch count
- average bitrate switch magnitude (kbps)
- ratio on highest video quality level
- 그 외 평가 metrics로 13개 더 추가 (advantage numerical quality metrics)
feature engineering - standard client-side QoE media metrics와 이들의 p-value of significance를 사용했다. use a coefficient suitable for a lower level (rank) scale - Spearman’s correlation coeffcient- in order to calculate the correlation of absolute and rank scales.