FCN(Fully Convolutional Network)
Classification & localization (분류 & 위치추정)
물체를 분류하는것 외에도 물체의 위치를 추정하기위해서는 위치를 나타낼 수 있는 bounding box의 정보를 찾아야한다. 가장 일반적인 방법은 다음 숫자 4개를 예측하는 것이다 - 물체 중심의 수평, 수직(x,y) 좌표와 높이, 너비(height, width).
분류 및 위치 추정을 진행할때에 가장 어려운 점은 label된 data set이 확보되어야 한다는 것이다. 수천, 수만개의 이미지에 bounding box를 label하는 작업은 training data를 확보하기위해 필수적인 단계이지만, 많은 시간/비용이 소모되는 단계이다.
물체의 위치를 추정하는 것은 회귀 작업으로 나타낼 수 있다. 일반적인 전역 평균 풀링 층 (global average pooling layer)에 4개의 unit을 가진 두번째 dense layer를 추가하고 MSE 손실을 사용해서 훈련을 진행할 수 있다. 그러나 모델의 성능을 더 잘 표현하는 더 좋은 지표는 IoU라는 지표이다.
IoU
IoU(intersection over union) = bounding box에 널리 사용되는 지표. 예측한 bounding박스가 target box와 얼마나 겹쳐있는지를 ratio로 표현한다. (IoU ratio = “겹친 부분”/”전체” = 교집합/합집합)
Object detection (객체 탐지)
하나의 이미지에서 여러 물체를 분류하고 위치를 추정하는 작업을 object detection이라고 한다.
기존 사용되었던 CNN 방식:
이미지를 n by m grid로 나누고, 하나의 CNN이 모든 p by p (p<n,m) 영역을 지나가면서 이미지속의 객체를 감지한다. p by p 영역의 scan이 모두 끝나면 p+1 by p+1 영역으로 영역을 조금 더 키워서 똑같은 scanning을 진행한다. 이런 방식으로는 CNN이 작은 크기의 영역을 지정해서 조금씩 움직이며 전체 이미지를 scan하기 때문에, 동일한 물체를 여러번 감지하게 된다. 그래서 non-max suppression이라는 방법을 적용한다.
Non-max suppression:
- 객체의 존재여부 확인 - CNN의 영역에 또 다른 객체가 정말 존재하는지 확률을 추정하기위해서 존재여부 (objectness) 출력을 추가한다. sigmoid 활성화 함수와 binary cross entropy를 손실함수로 사용해서 훈련한다. 어떤 threshold를 지정해서 존재여부 점수가 threshold 이하인 bounding box는 모두 삭제한다. (객체가 들어있지 않다고 판단하기 때문에)
- 존재여부가 가장 높은 bounding box를 찾는다. 그리고 이 박스와 많이 중첩된 (e.g., IoU > 60% 인 bounding box)를 모두 제거한다. 그러면 동일한 객체위에 위치해서 최대값을 가진 bounding box와 상당히 겹쳐있는 박스들이 제거될 것이다.
- 더 이상 제거할 bounding box가 없을 때까지 위 두 단계를 반복한다.
위와 같은 객체 탐지 방식을 성능은 좋지만 CNN을 여러번 실행 시켜야해서 속도가 많이 느리다. 이를 보완하기위해 완전 합성곱 신경망 FCN(fully convolutional network)을 사용하면 CNN을 훨씬 더 빠르게 이미지에 sliding 시킬 수 있다.
FCN
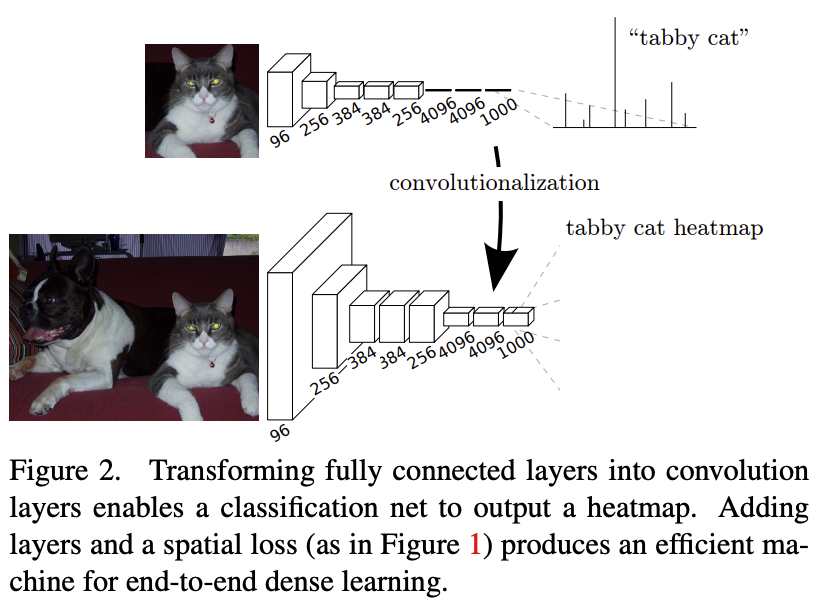
물체가 속한 클래스에 따라 이미지의 모든 pixel을 분류하는 작업을 semantic segmentation (시맨틱 분할)이라고 한다. CNN 맨위의 dense layer를 convolutional layer로 바꾸어서 모델 구조 전체가 conv layer로 구성되도록 설계한다.
2015년 FCN이 처음 소개된 논문: https://arxiv.org/pdf/1411.4038.pdf
예시)
7x7의 100개의 feature map을 출력하는 합성곱 층 위에 neuron이 200개가 있는 dense layer가 있다. 이 200개의 neuron은 각각 100x7x7 크기의 활성화 값 (+bias)에 대한 가중치 합을 계산한다. 이 dense layer를 7x7 filter 200개와 “valid” padding을 사용하는 convolutional layer로 바꾸면, 이 conv layer는 1x1 크기의 feature map 200개를 출력할것이다. (kernel이 정확하게 입력 feature map의 크기와 같고 valid padding이 적용되었기 때문에.) 이 경우 dense layer를 적용했을때와 마찬가지로 200개의 output 숫자가 출력 될것이다. 여기에서 conv layer가 수행하는 계산을 보면, dense layer에서 만드는 숫자와 완전하게 동일하다. 단 차이점은 dense layer의 경우 출력이 [batch size, 200] 크기의 tensor이고, conv layer의 경우에는 출력이 [batch size, 1, 1, 200] 크기의 tensor라는 것이다.
dense layer를 conv layer로 바꾸려면 conv layer의 filter개수와 dense layer의 unit 개수가 동일해야하고 filter의 크기가 입력되는 특성 map의 크기와 같아야한다. 그리고 padding은 valid로 지정되어야한다. (stride는 1이상의 값으로 지정할 수 있음.)
dense layer 대신 포함된 conv layer의 역할은? dense layer는 (입력 특성마다 하나의 가중치를 두므로) 특정 입력 크기로 정해져있지만, conv layer가 대체하게되면 어떤 크기의 이미지도 처리할 수 있게 된다. (대신 conv layer는 입력 채널마다 kernel 가중치가 달라서 특정 개수의 channel로 정해지게 된다.) FCN은 conv layer만으로 구성되어있기때문에 어떤 크기의 이미지에서도 훈련하고 실행할 수 있다.
예를 들어 꽃 분류와 위치 추정을 위해 CNN 모델을 하나 훈련했다고 가정한다면, 이 모델은 224x224 크기의 입력 이미지로 훈련을 진행해서 10개의 숫자를 출력한다. 10개의 출력 숫자는 다음과 같다:
0~4번까지의 출력은 softmax 활성화 함수로 전달되어 클래스마다 각각의 확률값을 보여준다.
5번 출력은 logistic 활성화 함수를 통화해서 존재여부(objectness) 점수를 보여준다.
6~9번까지의 출력은 활성화 함수를 통과하지않고, bounding box의 좌표와 높이, 너비를 나타낸다.
이 dense layer는 conv layer로 바꿀 수 있다. dense layer의 가중치를 conv layer로 복사할 수 있기때문에 다시 훈련할 필요가 없다. 또는 아얘 훈련하기전에 CNN을 FCN으로 바꾸어서 진행 할 수 있다.
이 network에 224x224 크기의 이미지가 입력되었을때 출력층 직전의 conv layer(aka “병목층”)가 7x7 크기의 특성map을 출력한다고 가정하면, 이 FCN에 448x448 크기의 이미지를 입력하면 병목층은 14x14 크기의 특성map을 출력할것이다. dense layer가 7x7 크기의 filter 10개와 valid padding, stride 1을 사용한 conv layer로 바뀌였기때문에 출력은 8x8 크기 (14-7+1=8)의 특성 map 10개로 이루어진다.
즉, FCN은 전체 이미지를 딱 한번만 처리해서 8x8 크기의 배열을 출력하는 것이다. 이 배열의 각 원소 (aka “cell”)은 10개의 숫자를 담고있다. (위에서 말한 5개의 클래스 확률, 존재여부, 4개의 bounding box 좌표 및 사이즈) 이것은 원래 CNN이 행방향으로 8 step, 열방향으로 8 step 슬라이딩하는 것과 같다. (원본 이미지를 14x14 격자로 줄이고 이 격자에 7x7 윈도우 영역이 슬라이딩 한다고 생각해볼 수 있다. 가능한 윈도우 위치는 8x8=64개 이므로 8x8개가 예측이 된다.) FCN으로 이미지를 감지하면 이보다 훨씬 더 효율적이게 학습 과정을 처리할 수 있다. 이렇게 한번 이미지를 보고 처리하는 모델로 YOLO(You Only Look Once)가 있다.
YOLO
YOLO(2015) –> YOLOv2(2016) –> YOLOv3(2018) –> YOLOv4(2020) –> YOLOv5(2020)
지속적으로 발전해 왔다.
YOLOv3의 구조는 위에서 설명한 FCN과 비슷하지만, 다음과 같음 차이점이 있다:
bounding box 개수 - 각 격자 cell마다 1개가 아닌 5개의 bounding box를 출력. bounding box마다 하나의 존재여부 점수가 부여된다. YOLO는 20개의 클래스가 있는 PASCAL VOC 데이터 셋에서 훈련되었기때문에 격자 cell마다 20개의 클래스 확률을 출력한다. 그래서 격자 cell마다 총 45(20+ 5x4 + 5)개의 숫자가 출력된다. (20개 클래스 확률 + 각 bounding box마자 4개의 좌표 + 5개의 존재여부 점수)
bounding box 좌표 - bounding box 중심의 절대 좌표 대신, 격자 cell에 대한 상대 좌표를 예측한다. (0,0)은 cell의 왼쪽 위를 의미하고 (1,1)은 cell의 오른쪽 아래를 의미한다. 각 격자 cell에 대해 YOLOv3 모델은 bounding box의 중심이 격자 cell안에 놓인것만을 예측하도록 훈련된다. (bounding box의 중심이 cell안에 놓여야 한다는것이지, bounding box자체는 격자 cell밖으로 넘어갈 수 도 있음.) YOLOv3는 logistics 활성화 함수를 적용해서 bounding box 좌표가 0과 1 사이가 되도록 한다.
anchor box - 신경망을 훈련하기전에 YOLOv3는 anchor box 앵커 박스 (또는 bounding box prior 사전 바운딩 박스)역할을 할 5개의 대표 bounding box를 확보한다. k-means algorithm을 훈련 세트 bounding box 높이와 너비에 적용해서 대표 box들을 찾는다.
예를 들어)
훈련 이미지에 많은 보행자가 있다면 anchor box 중 하나는 전형적인 보행자 크기가 될것이다. 그 다음 신경망이 격자 cell마다 5개의 bounding box를 예측할때 각 anchor box의 scale을 어떻게 조정할 것인지 예측한다. 한 anchor box의 길이가 100pixel이고 너비가 50pixel이라면 network가 (격자 cell하나에 대해) 수직방향 scale의 조정 비율을 1.5로, 수평 방향을 0.9로 예측한다. 결국 예측되는 bounding box의 크기는 150x45 pixel이 된다. (더 정확히는 각 격자 cell과 각 anchor box마다 network는 수직, 수평 방향 scale 조정 비율의 log값을 예측한다.)
이 anchor box를 통해서 network가 적절한 차원의 bounding box를 예측할 수 있도록 한다. 적합한 bounding box로 보이는 것을 빠르게 학습할 수 있기 때문에 훈련 속도를 높여준다.
scale - network가 다른 scale을 가진 이미지를 사용하여 훈련된다. 훈련하는 동안 몇번의 batch마다 random하게 새로운 이미지 차원을 선택한다. (330x330 ~ 608x608pixel까지) 그래서 network가 다른 scale의 객체를 감지하는 방법을 학습한다. YOLOv3 모델을 다른 scale에 사용할 수도 있다. 작은 scale은 정확도가 떨어지지만 큰 scale보다 속도가 빠르다. 문제에 따라 적절한 trade-off를 조정할 수 있다.
mAP
mAP = mean average precision를 통해 평가하는 평가지표이다.
classification의 지표인 정밀도와 재현율은 trade-off 관계를 가지고있다. 정밀도/재현율 curve를 그려보면 확인할 수 있고, 이 curve아래 면적을 AUC(area under curve) 값으로 계산해서 지표를 요약하는 숫자로 사용하기도 한다. 그러나 재현율이 증가할때 정밀도도 상승하는 영역이 포함될 수 도 있다. (특이 재현율 값이 낮을 때)
공정한 모델의 성능을 측정하는 한 가지 방법으로 mAP가 사용된다. 최소 0% 재현율에서 얻을 수 있는 최대 정밀도, 그 다음 10% 재현율에서, 그 다음 20%,…. 100% 까지 재현율에서의 최대 정밀도를 계산하고 이 최대 정밀도를 평균한 값을 구한다. 이 값을 평균 정밀도mAP라고 부른다.
두 개 이상의 클래스가 있을때에는 각 클래스에 대해 AP를 계산한다음 평균 AP를 계산해서 mAP를 구한다.
객체 탐지 시스템에서는 조금 더 복잡해진다. 특정 클래스 객체를 올바르게 탐지는 했지만, 위치가 잘못되었다면 (즉, bounding box가 객체를 완전 벗어났다면) 이런 경우는 올바른 예측으로 포함시키면 안된다. 이런 경우를 제외시키기위해 IoU threshold 값을 설정할 수 있다. 예를 들어 IoU가 0.5 이상인 경우에만 예측 클래스가 맞다면 올바른 예측으로 받아들이는 것이다. 이 경우 mAP@0.5 또는 mAP@50%로 표기한다. (PASCAL 대회의 경우에는 mAP@0.5값을 사용한다. COCO 대회의 경우에는 여러(@0.5, 0.55, 0.6, …, 0.95) IoU 임계값에서 mAP를 찾아서 평균한 값을 최종 지표로 사용한다. mAP@[0.5:0.05:0.95]로 표기한다.)
Semantic segmentation 시맨틱분할
기존 conv layer를 활용한 CNN 모델에서는 network에 더 깊숙히 들어갈 수록 input 이미지의 abstract representation을 생성해내기때문에 이미지 속의 객체를 분류할 수 는 있지만, 그 객체의 위치 정보를 학습하기 어려워진다.
이를 개선하기위해 FCN 구조를 활용할 수 있지만 (preserving the input dimension using ‘same’ padding), computation cost가 커지는 단점이 있다.
cost는 줄이고 객체 탐지보다 더 정밀하게 이미지를 감지할 수 있는 방법은 pixel 단위로 구분하는 시멘틱 분할 기법이다. semantic semgnetation에서는 각 pixel이 속한 객체의 클래스로 pixel을 분류한다. 클래스가 같은 물체는 따로 구분하지않는다. 그래서 이미지에 만약 자전거가 여러개 붙어있다면, 그들을 하나의 큰 pixel 덩어리로 인식한다.
이 작업에서 가장 어려운점은 이미지가 일반적인 CNN을 통과 할때 점진적으로 위치 정보를 잃어버린다는 것이다. (stride>1로 설정된 layer들 때문에 spatial 정보가 압축되어버리기 때문에) 예를 들어 이미지의 오른쪽 아래 어딘가에 사람이 있다는것을 알수는 있지만 그보다 더 정확하게 알수는 없다. 이런 문제를 해결하기 위해 CNN을 FCN으로 변경할 수 있다. 이 CNN이 입력 이미지에 적용하는 전체 stride는 32이다. (1보다 큰 stride는 모두 더한것이다.) 이는 마지막층이 입력 이미지보다 32배나 작은 특성 map을 출력한다는 것이다. 이미지가 매우 듬성듬성하기 때문에 해상도는 늘리기위해 upsampling layer를 활용할 수 있다.
upsampling방법은 여러가지 방법으로 이미지 사이즈를 늘리는것이다.
주로 사용되는 upsampling 기법:
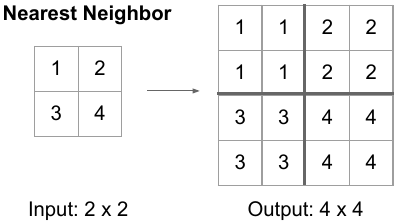
nearest neighbors - In Nearest Neighbors, as the name suggests we take an input pixel value and copy it to the K-Nearest Neighbors where K depends on the expected output.
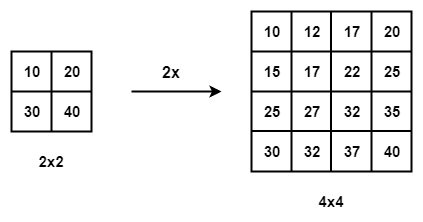
bi-linear interpolation - 4배나 8배로 늘리는데 적합하다. Take the 4 nearest pixel value of the input pixel and perform a weighted average based on the distance of the four nearest cells smoothing the output.
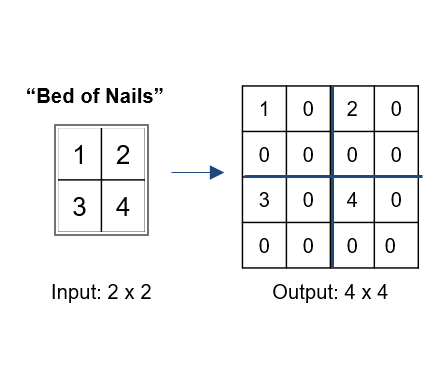
bed of nails - copy the value of the input pixel at the corresponding position in the output image and filling zeros in the remaining positions.
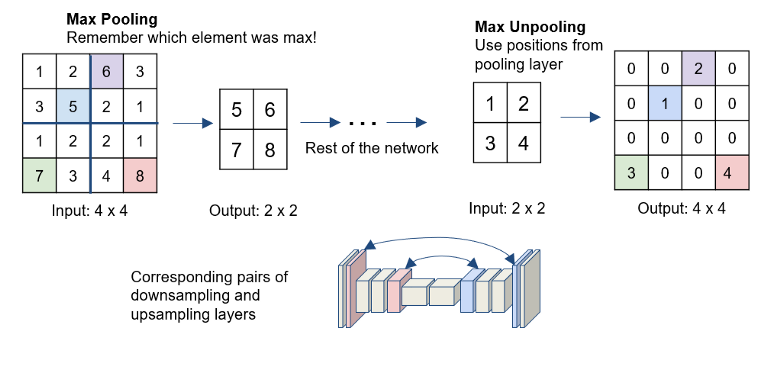
max-unpooling - The Max-Pooling layer in CNN takes the maximum among all the values in the kernel. To perform max-unpooling, first, the index of the maximum value is saved for every max-pooling layer during the encoding step. The saved index is then used during the Decoding step where the input pixel is mapped to the saved index, filling zeros everywhere else.
transposed convolutional layer
시간과 계산비용이 큰 FCN외에 다른 개선안으로 다음과 같이 network을 두 개의 part로 나누어서 진행할 수 있다 - downsampling network진행 후, upsampling network을 진행하는 것이다.
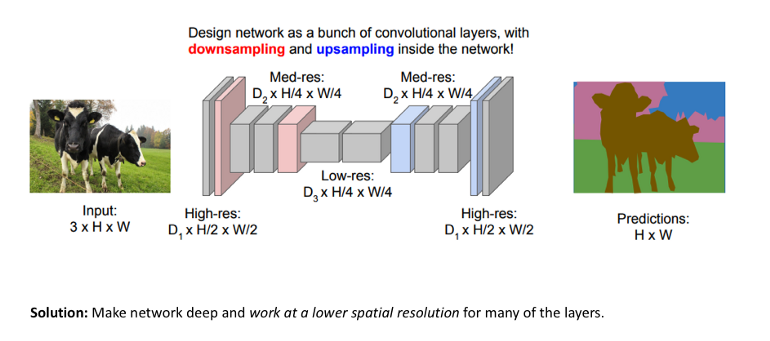
Downsampling network에선 기존 CNN architecture가 사용되어 input image의 abstract representation을 생성하는 것이다. 그 다음 단계인 upsmapling network에선 다양한 연산 기법을 활용해서 abstract representation의 spatial dimension을 input image와 동일하게 만든다. 이렇게 downsampling + upsampling으로 구성된 architecture는 “encoder-decoder network”이라고도 불린다. upsampling을 하는 단계에서 transposed conv layer를 활용할 수 있다.
transposed conv layer는 아래 그림과 같이 convolutional layer의 reverse인 deconvolutional layer와 비슷하다고 볼 수 있다. 단, deconvolution은 original input을 돌려 준다면, transposed conv layer는 original input과 동일한 dimension을 확보할 수있지만 동일한 values는 확보할 수 없다.
convolution vs. deconvolution vs. transposed convolution

transposed conv layer는 기존 conv layer가 하는 역할을 동일하게 수행하지만, modified input 특성 map을 만들어서 사용하는것이 다르다.
![]()
transposed convolutional layer(전치 합성곱 층)은 먼저 이미지에 (0으로 채워진) 빈 행과 열을 삽입해서 늘린 다음 일반적인 합성곱을 수행한다. 이를 부분 stride를 사용하는 일반 합성곱으로 생각하는 경우도 있다.
downsampling
기존 convolutional layer
기존 conv layer의 처리 방식으로 진행된다. 각각 주어진 stride, padding값에 따라서 출력되는 특성 map이 다르다.
stride가 1인 경우: padding=1인 경우에는 input 크기가 그대로 유지된다.

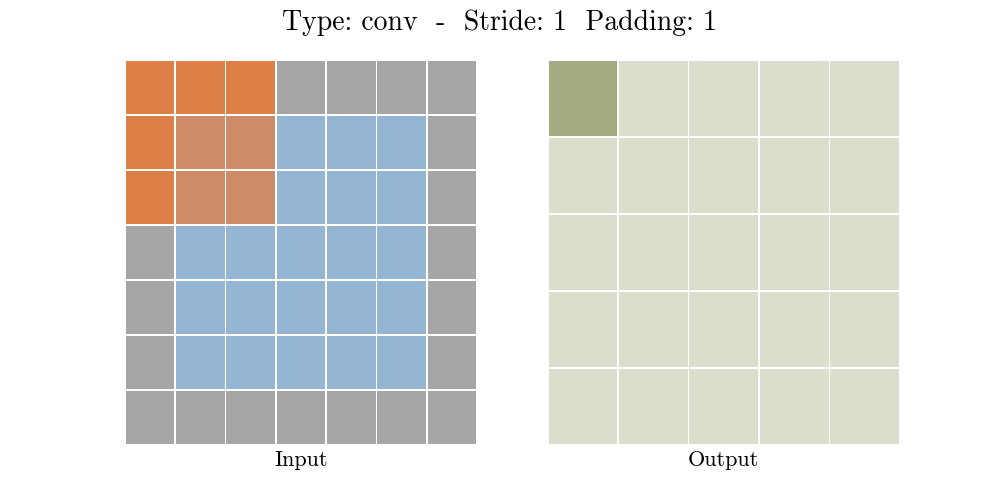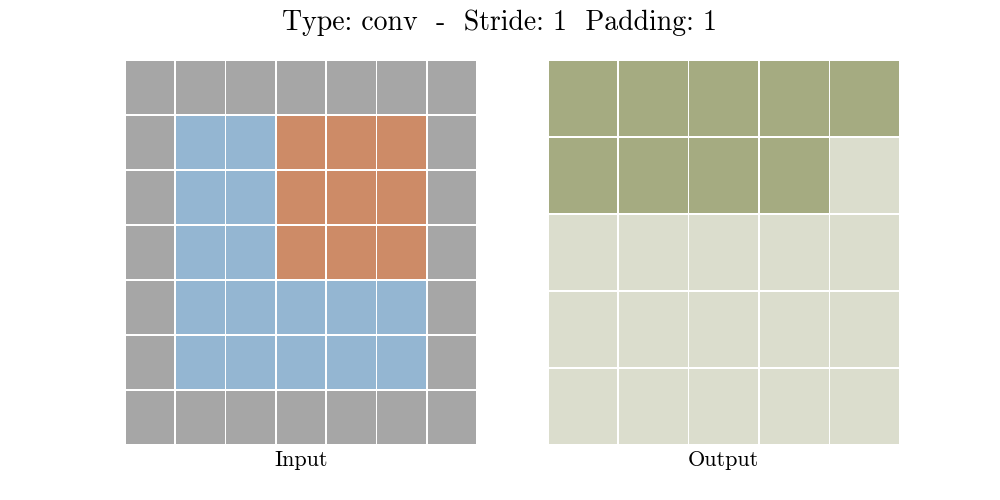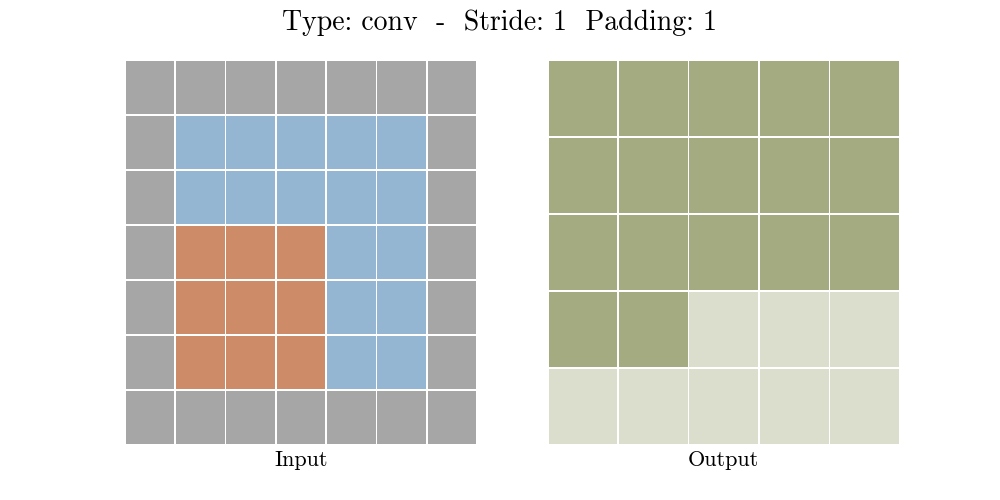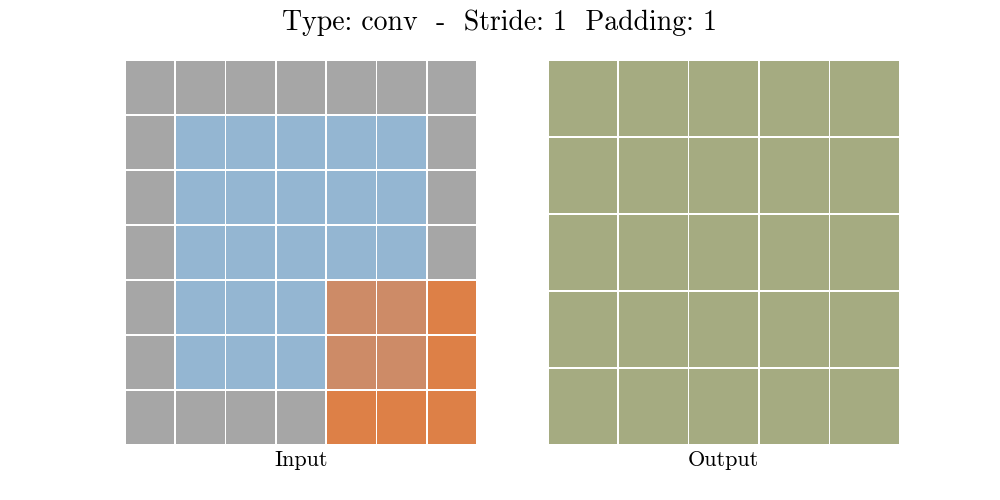
stride가 2인 경우: padding에 따라서 output 특성 map크기가 달라진다.


출력되는 특성map의 사이즈는 다음과 같이 공식화 할 수 있다.
upsampling
transposed convolutional layer (전치 합성곱 층)
transposed convolutional layer는 input 특성 map보다 더 큰 sptial dimension을 가진 특성 map을 출력한다. transposed conv layer도 padding과 stride로 설정할 수 있다. 이 padding과 stride 값은 output에 hypothetically 적용되어서 input을 생성한다. (if you take the output and carry out a standard convolution with stride and padding defined, it will generate the spatial dimension same as that of the input)
Transposed conv layer를 구현 예시:
input size 2x2 가 다음과 같이 주어진다면,
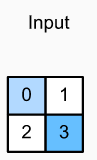
parameter z와 p’를 계산한다. (z=s-1, p’=k-p-1). kernel은 다음과 같이 2x2 크기를 갖는다.

input image의 각 행과 열 사이에 z개의 0을 insert한다. (z=2-1=1) 이 단계를 거치면 input의 size가 (2*i-1)x(2*i-1)로 커지게 된다.
이 예시의 경우 원하는 output map 크기인 3x3 으로 input 특성 map 크기가 커진다.
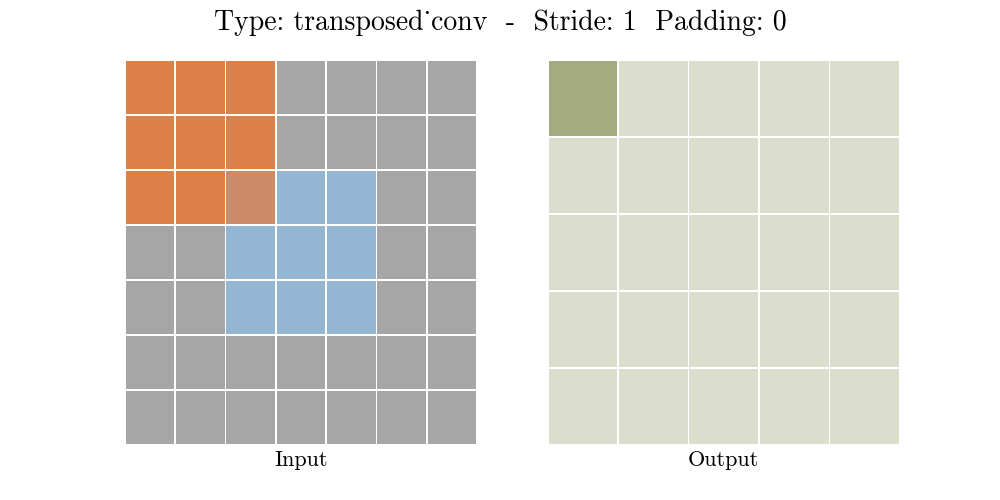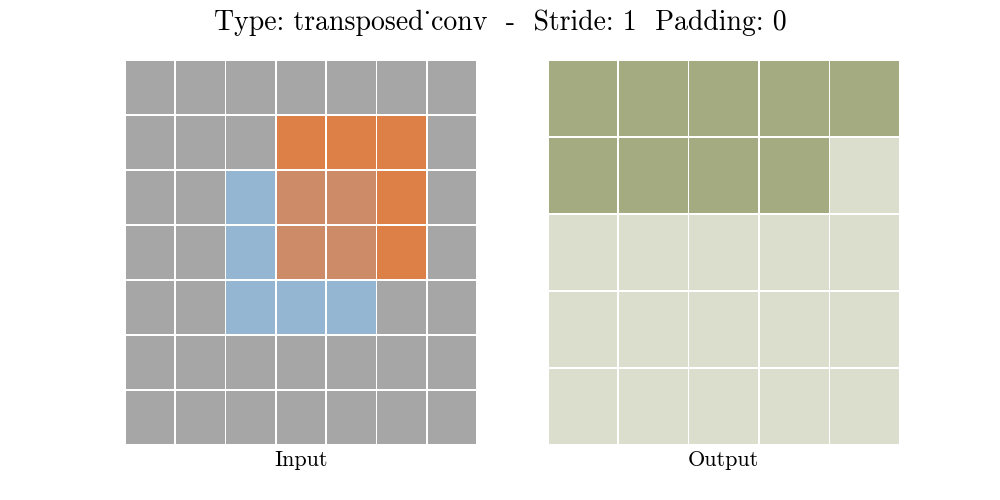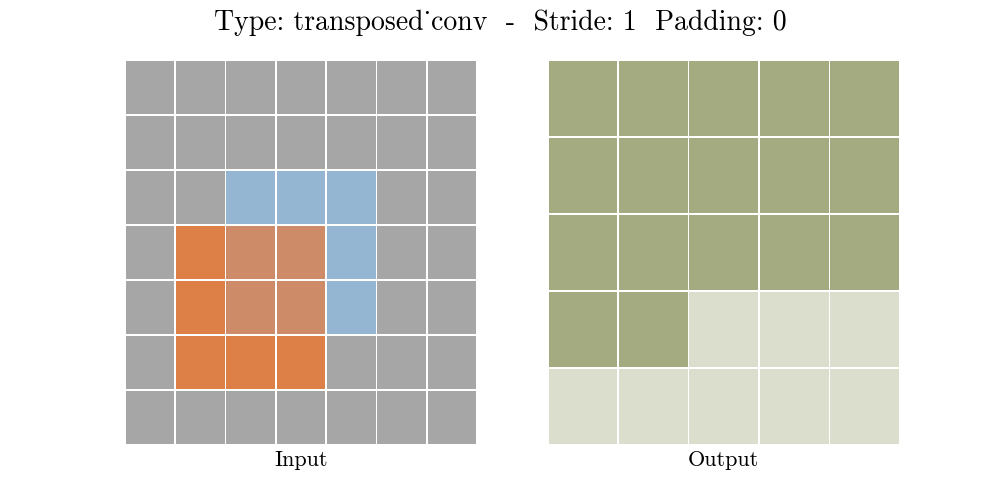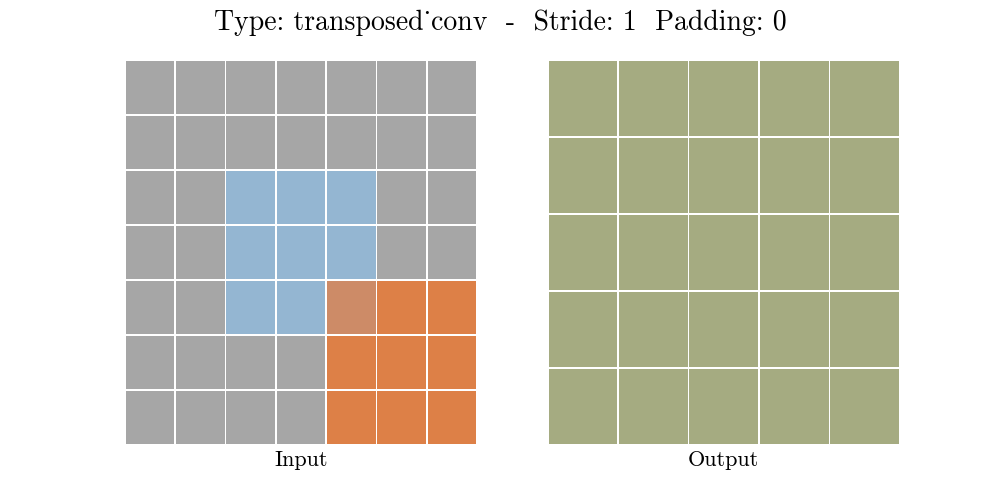
변경된 input image를 p’개수의 0으로 padding한다. stride = 1으로 기존 convolution을 적용한다. 아래 그림과 같이 input cell에 각각 kernel 적용 후, overlap되는 cell의 value들을 더해준다. (e.g., 3x3 grid의 center cell의 경우 0+2+2+0 = 4이여서, output feature map을 보면 center가 4이다.)

출력되는 특성map의 사이즈를 구하는 공식은 다음과 같다. \(o = (i-1)*s +k-2p\)
Transposed conv layer는 해당 stride와 padding에 따라 다음과 같은 output 특성 map을 보여준다.
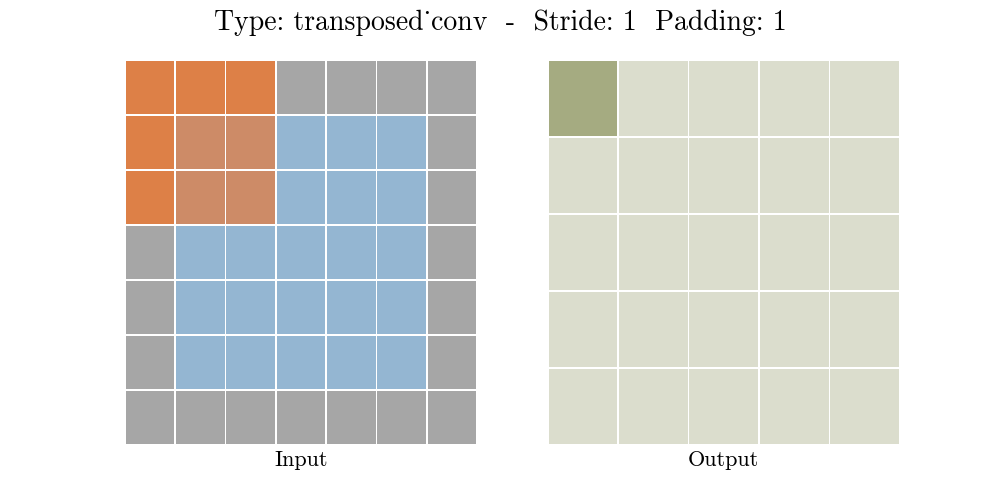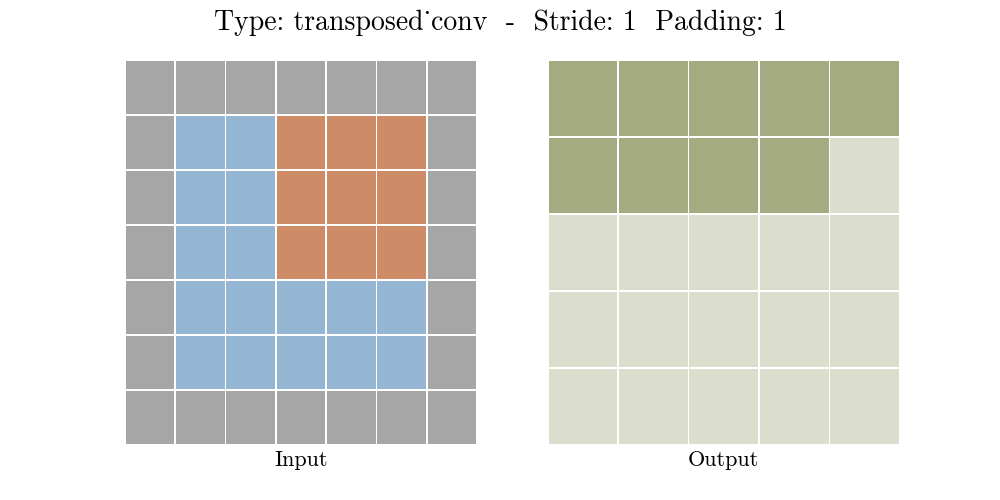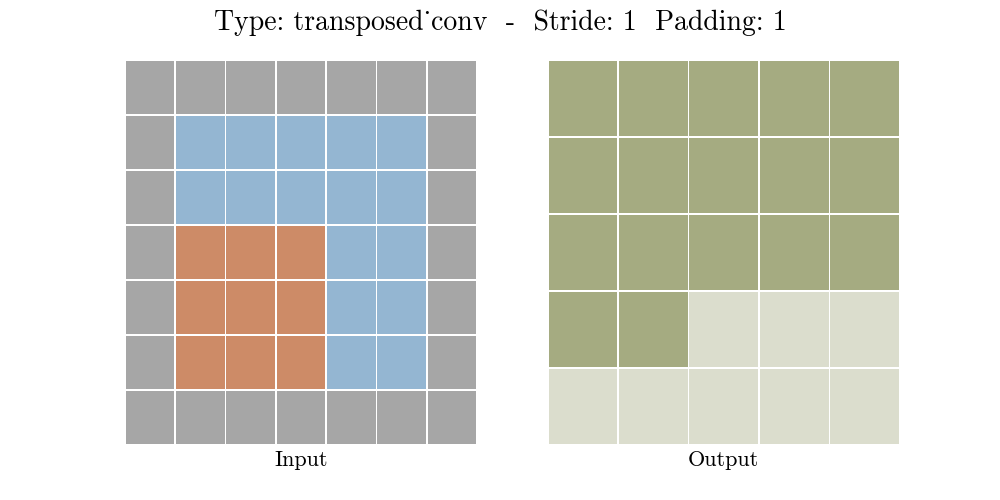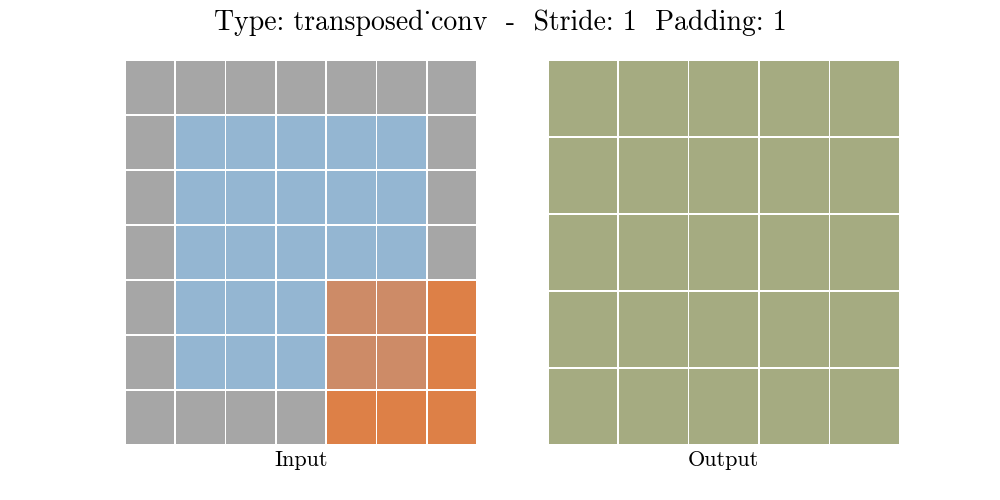
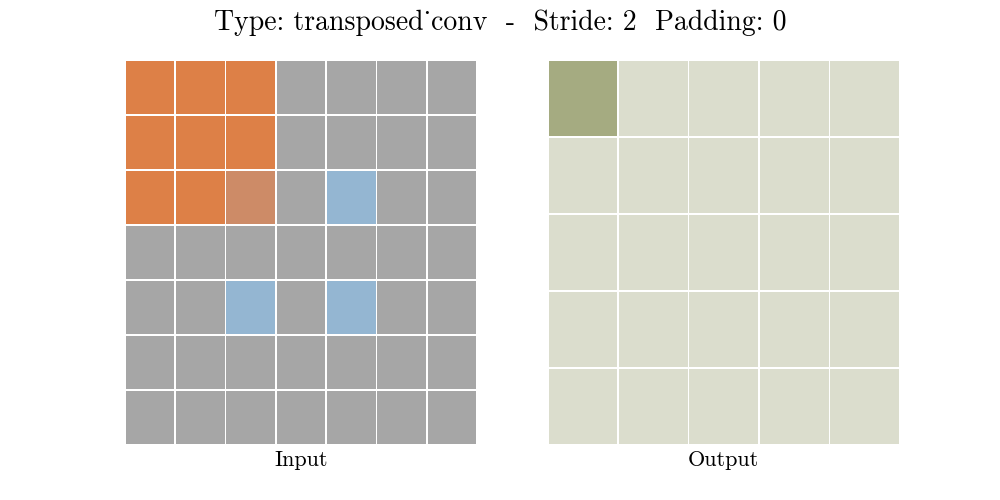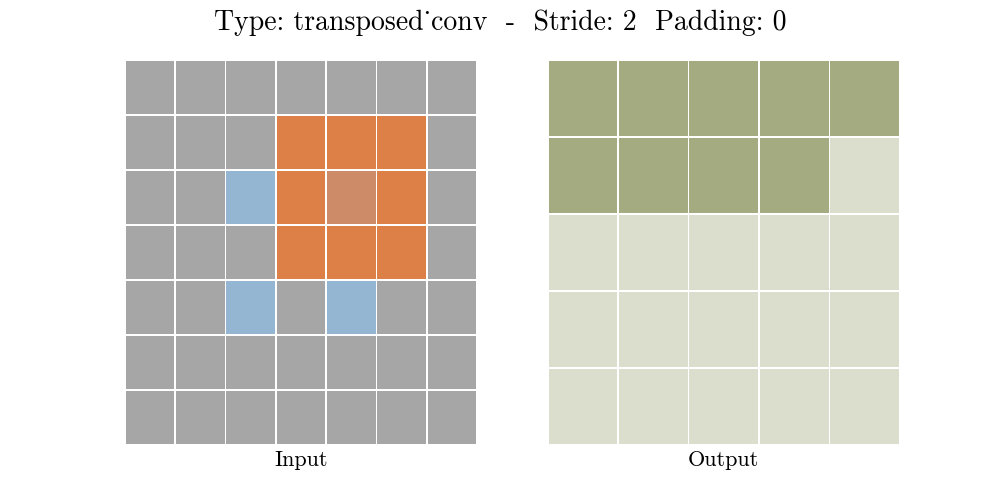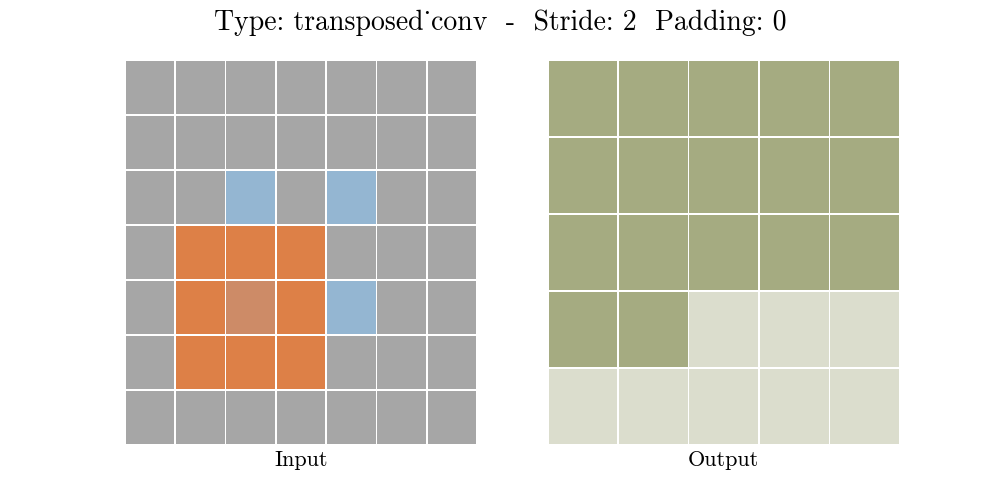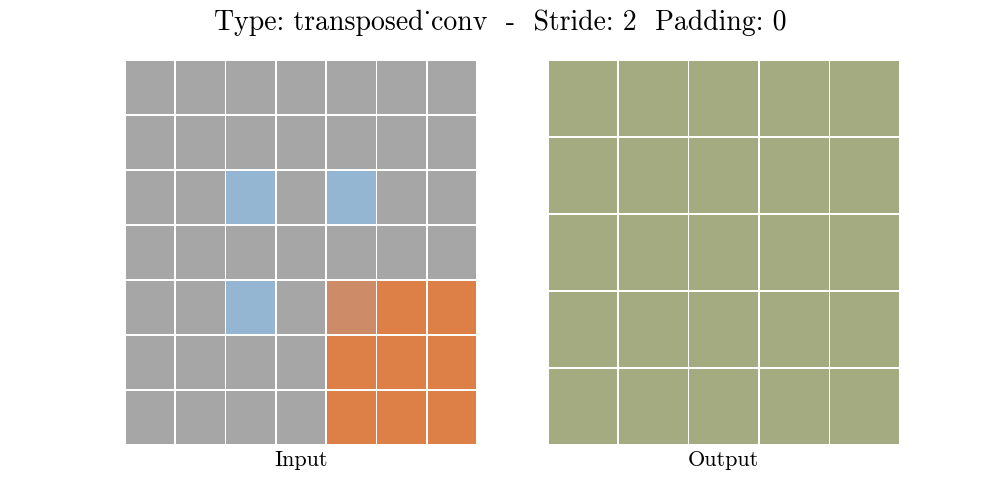
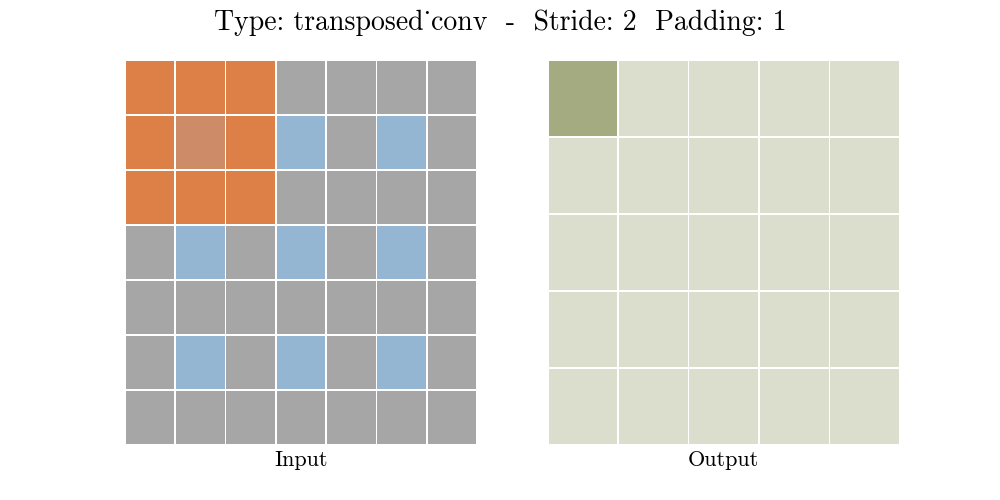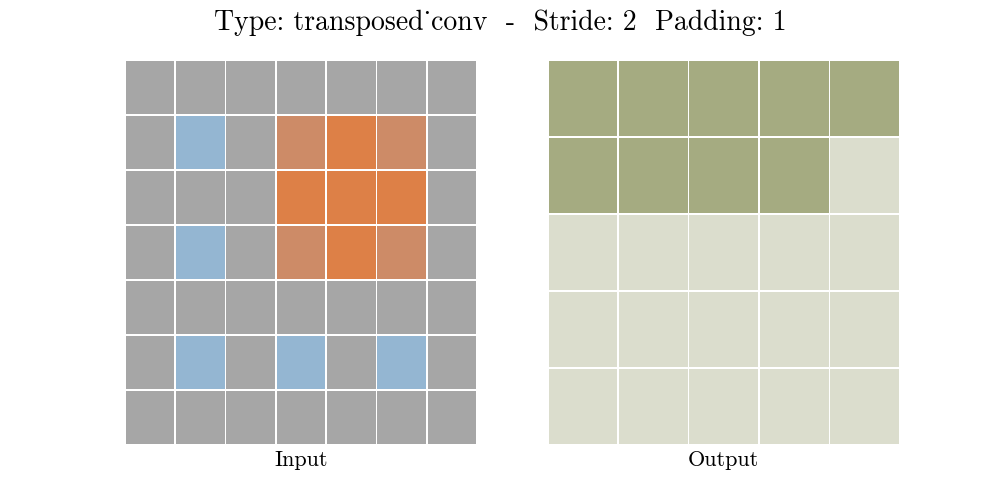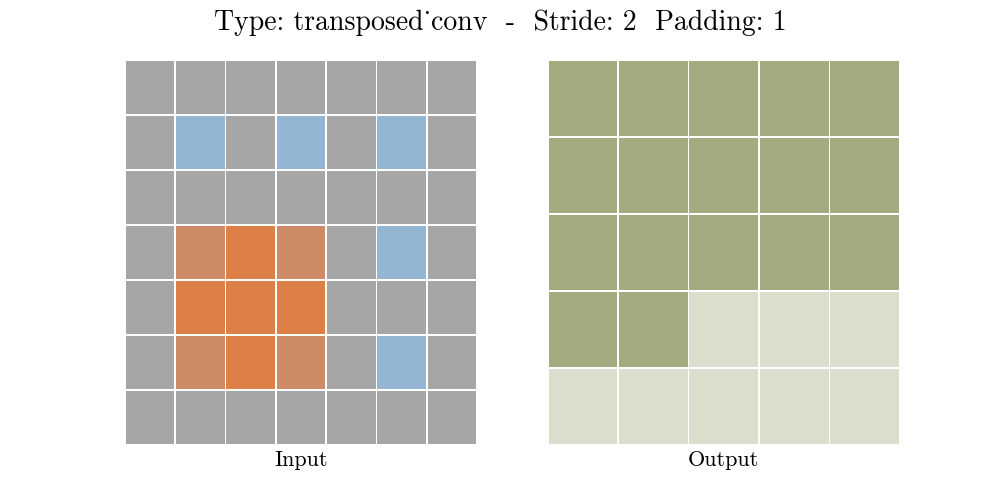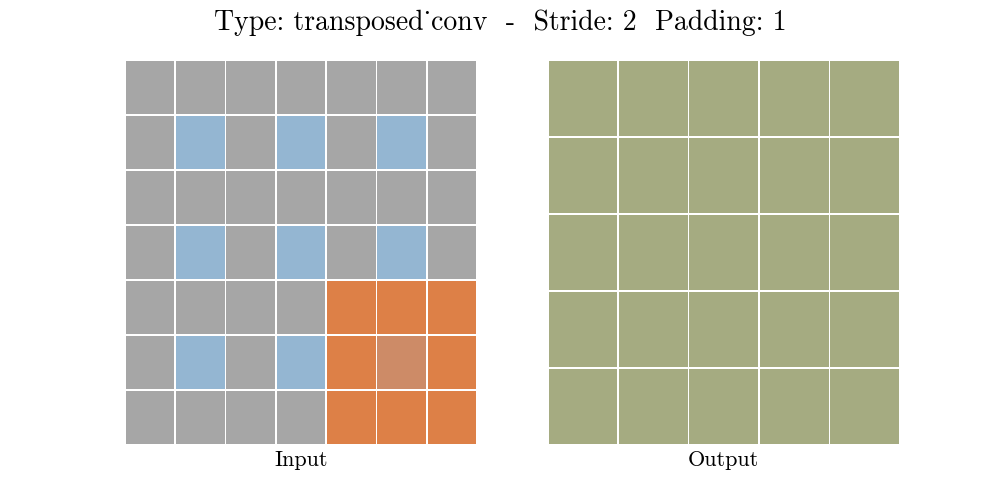
정리해보자면, transposed conv layer를 사용하면 image segmentation, super-resolution과 같은 application의 localization과 segmentation을 구현할때 이미지 속 객체의 spatial dimension 정보를 모델이 학습할 수 있다. Transposed conv layer도 standard convolution과 동일하지만, modified input 특성map을 바탕으로 convolution 연산을 구현하여서 원하는 크기의 output 특성map을 확보하는 upsampling을 수행한다. transposed convolution layer는 checkerboard effect 단점을 가지고있기도 하다. 이미지의 특정 부분에서 uneven overlap으로 인해 발생하는데, stride 값의 배수를 kernel-size로 지정하여 진행하면 이 문제가 완화 된다. (e.g., kernel size of 2x2 or 4x4 when having a stride of 2.)
추가적으로 정확도를 개선하기위해 skip connection을 사용할 수 있다. 아래층에서 skip connection을 통해 입력 이미지에 더 가까운 정보를 위층에 전달해준다. 위층으로 갈수록 세세한 특성이 추상화되어 버리기때문에, 아래층의 정보를 바로 주입해주어서 세세한 특성이 그대로 전달되는 효과를 얻는다.
예를 들어,
2배로 출력 이미지를 upsampling하고, 아래쪽 층의 출력을 더해서 해상도를 두배로 키울 수 있다. 그 다음 이 결과를 16배로 늘려서 upsampling하여 최종적으로 32배의 upsampling을 달성한다.
이런 방식을 통해서 pooling층에서 읽은 일부 공간 정보를 복원시킨다. upsampling을 통해 이미지의 해상도를 증가시키는데 사용할 수 있다. 이를 super-resolution (초해상도)라고 부른다.
다음 그림과 같이 image super-resolution technology을 통해 infrared detector 이미지와 같이 해상도가 낮은 이미지의 해상도를 높일 수 있다. concatenation을 통해 아래층쪽의 출력이 윗층에 두 번 더해지는 것을 볼 수 있다.
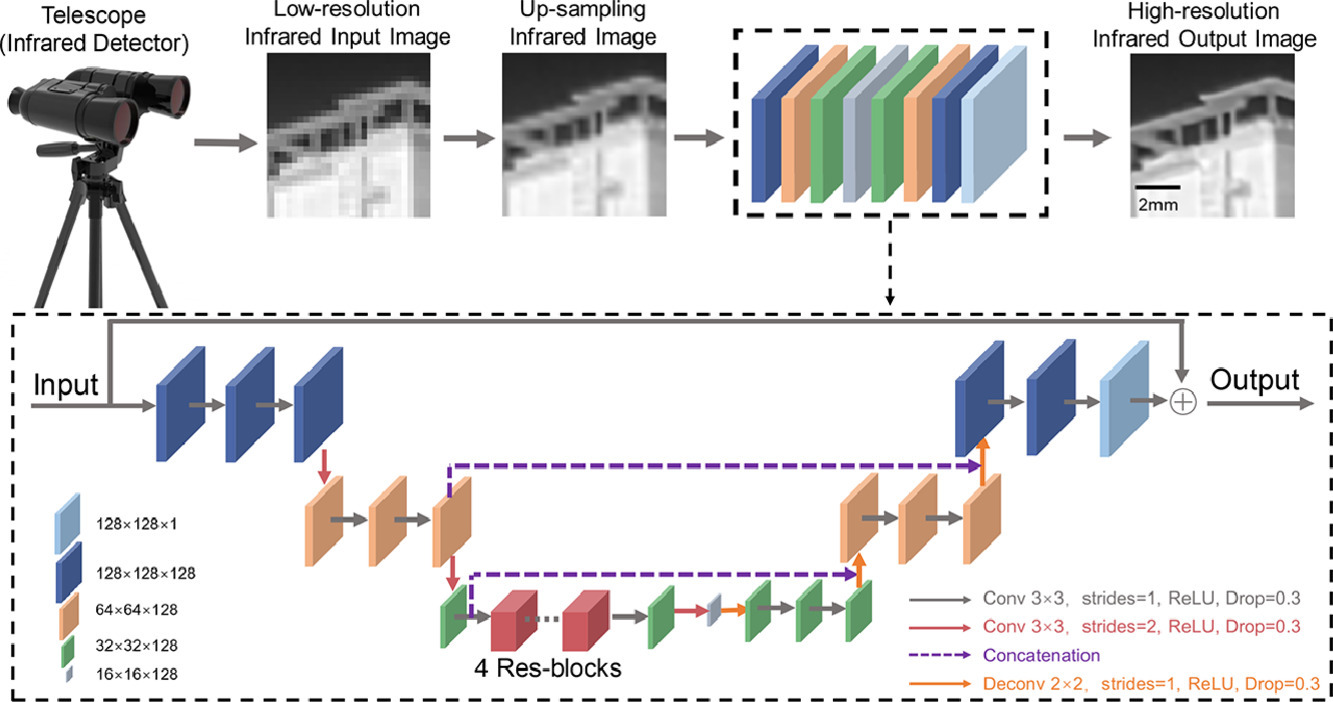
https://www.sciencedirect.com/science/article/abs/pii/S0143816621001871
tenorflow convolution operation(합성곱 연산)
tensorflow는 몇 가지 다른 종류의 합성곱 층도 제공한다.
keras.layers.Conv1D - 1D 입력에 대한 conv layer를 만든다. (시계열이나 텍스트를 다룰때에 사용)
keras.layers.Conv3D - 3D PET(positron emission tomography) scan같은 3D 입력을 위한 conv layer를 만든다.
dilation_rate - tf.keras의 conv layer에 있는 dilation_rate 매개변수를 2 이상으로 지정하면 atrous convolutional layer가 된다. (‘a trous’는 프랑스어로 ‘구멍난’을 의미함.) 0(‘구멍’)으로 된 행과 열을 추가해서 늘린 필터로 보통의 conv layer를 사용하는 것과 동일하다.
예를 들어)
[[1,2,3]]과 같은 1x3 filter를 팽창 비율(dilation rate) 4로 늘리면 팽창된 필터(dilated filter)는 [[1,0,0,0,2,0,0,0,3]]이 된다. 이렇게하면 추가적인 계산 비용이나 parameter를 새로 만들지 않고 더 큰 수용장을 갖는 합성곱 층을 만들 수 있다.
tf.nn.depthwise_conv2d() - 이 함수는 깊이 방향 합성곱 층 (depthwise convolutional layer)를 만든다. (but 변수를 직접 만들 필요는 없음) 모든 필터를 각각의 입력 channel에 독립적으로 적용한다. f_n개의 필터와 f_n’개의 채널이 있다면, f_n*f_n’개의 특성map을 출력한다.
Instance segmentation 인스턴스 분할
instance segmentation은 클래스 물체를 하나의 덩어리로 합쳐 구분하는것이 아니라 각 물체를 하나하나 구분하여 표시한다. 다은 그림과 같이 instance segmentation에서는 사람을 하나의 덩어리로 구분하지 않고 5명의 각각의 사람을 따로 구분한다.
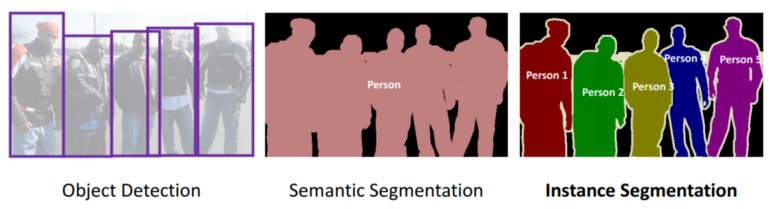
현재 tensorflow model project에 포함된 instance segmentation model중 하나는 Mask R-CNN (2017)이다. 이 모델은 Faster R-CNN 모델을 확장해서 각 bounding box에 대해 pixel mask를 추가로 생성했다. 그래서 물체마다 클래스 추정 확률과 bounding box를 얻는것 외에도 bounding box안에 들어있는 물체의 pixel을 구분하는 pixel mask도 얻을 수 있다.
Reference
- Geron, Aurelien. Hands on Machine Learning. O’Reilly, 2019
- transposed convolutional layer : https://towardsdatascience.com/what-is-transposed-convolutional-layer-40e5e6e31c11, https://towardsdatascience.com/transposed-convolution-demystified-84ca81b4baba