Algorithmic method for imbalanced TSC using CNN
The following contents are derived from a paper on imbalanced TSC “Towards effective classification of imbalanced data with convolutional neural networks” by Vidwath Raj, et al as cited in the bottom of this post.
Class imbalance problem을 tackle하는 일반적인 two approaches가 있다:
- changing the training data by resampling (oversampling the minority class or undersampling the majority class)
- adjusting the algorithm to favor the minority class
examples: Threshold Moving(supposedly outperforms resampling technique as shown in work of Zhou), Snowball Learning for neural networks, ensemble methods, other cost-sensitive learning methods for neural networks where different costs are associated with each class
Class imbalance 정도가 매우 큰 경우에 resampling 방식으로는 너무 큰 portion의 데이터가 drop되거나 가상으로 생성되기때문에 potentially overfitting의 위험이 크다. 이런 경우 cost-sensitive algorithmic approach가 활용될 수 있다. 이 논문에서는 Accuracy와 G-Mean metrics를 통해 classification performance를 측정했다.
formula for accuracy and G-Mean
accuracy = true positive + true negative / (all types)

TPR (True Positive Rate)은 recall(“실제 positive인것들 중에 맞게 예측한 경우”)과 같고 sensitivity로도 불린다.
TPR = true positive / (true positive + false negative)
FPR (False Positive Rate)은 “false alarm metric” or “실제 negative인것들 중에 맞게 예측한 경우”이고 (1-specificity)이며 다음과 같다:
FPR = false positive / (false positive + true negative)
아쉽게도 이 논문에서는 binary classification을 위한 CNN에 적용할 수 있는 algorithmic method가 논의 되었다. Multi-class문제에서는 여기서 확인된 바와 동일한 효과가 나오지 않을 수 있다. 그래도 multi-class classification을 binary로 convert하여 진행 할 수 있는 문제들에는 적용가능한 내용 같다. 실제 구현은 Python Theano를 활용하여 진행할 수 있다.
GMSE(Global Mean Square Error) Separation
Mean Square Error(MSE) cost function은 actual output과 predicted output사이의 error를 minimize한다. Global Mean Square Error(GMSE) Separation은 각 다른 class들의 error를 differentiate/분별하는 algorithmic method이다. Minimize하려는 cost function을 GMSE를 통해 weighted sum of the cost of individual classes로 구한다.
pth training example의 error는 다음과 같이 compute된다.
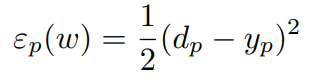
e_p는pth training example의 error이고, d_p는 actual desired output, y_p는 predicted output이다.
binary class classification의 경우에 다음과 같이 각 class별 weighted sum of errors를 구할 수 있다.
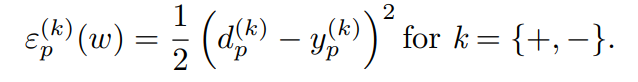
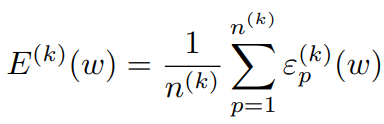
위와 같은 error를 최소화 하여 (for all k) optimization을 수행한다.
Backpropagation에서는 다음과 같이 weight w가 update되는데,
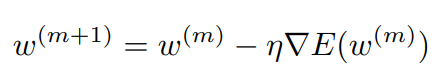
class별 GSME를 separate하기 위해서 다음과 같이 weighted sum을 계산한다.
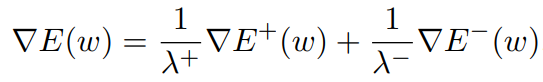
여기에서 lambda는 각 class의 misclassification을 penalize하기 위한 any positive constant가 될 수 있다. Standard backpropagation에서는 lambda가 1이고, 보통 각 class의 sample size를 lambda값으로 사용한다. Lambda는 classification의 결과로 원하는 specificity와 sensitivity를 얻기위해 조정될 수 있는 constant값이다.
보통 GPU programming에서 error gradient를 쉽게 access할 수 있게 되어있지 않지만, 다음과 같이 error function을 조정하여 각 class별 misclassification cost를 조정할 수 있다.
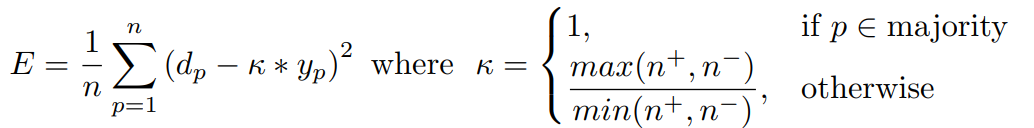
만약 pth sample이 majority class sample이라면, k=1이고, 만약 pth sample이 majority class가 아니라면 위와 같이 class size ratio를 k로 사용한다. (n+ = positive class sample size, n-=negative class sample size) 다음과 같은 순서로 class별 weight를 다르게 적용하는 방안이 구현될 수 있다. (Python GPU library Theano를 사용하면 더 쉽게 implement할 수있다.)

여기에서는 최적의 k값을 찾는것이 challenge이다. k의 값으로 static 값을 사용하기보다는, 주어진 특정 dataset에 맞추어서 classification performance의 metric인 G-Mean과 accuracy를 최대화 할 수 있도록 k를 optimize하는 방안이 연구되었다. Stochastic gradient learning으로 minibatch마다 weight parameter를 업데이트하고, k를 epoch마다 its own learning rate을 통해 update한다. weight parameters와 k의 learning이 jointly 수행되도록 한다.
k optimization
weight parameter와 k를 함께 optimize하기위해서는 - 둘중 하나를 constant로 유지하는 동안, 다른 하나를 기반으로 cost를 minimize하고 이를 alternative하게 진행해서 둘이 jointly 최적화 되도록 한다. F에 gradient descent algorithm을 적용해서 다음과 같이 k를 설정한다.
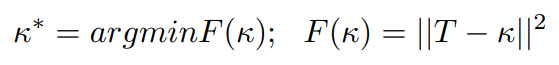
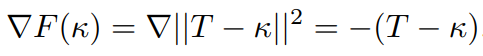
여기에서 F는 T를 기반으로 한 function이다. T는 다음과 같이 세 가지 방식으로 G-Mean, accuracy 또는 둘 다를 기반으로 설정된다. T는 [1,H] range내의 값으로 설정된다. H는 maximum cost applicable to the minority class이다. (ratio of imbalance와 같음)
G-Mean과 accuracy 둘 다 기반의 T:
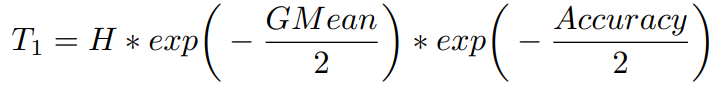
G-Mean 기반의 T:
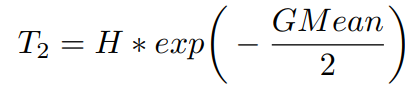
G-Mean과 validation error(1-accuracy) 기반의 T :
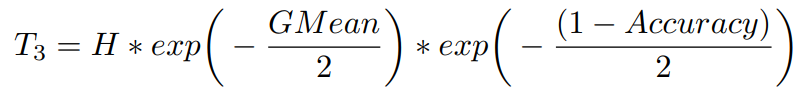
(각 방식으로 얻은 T를 기반으로 찾은 k를 “adaptable” k라고 명칭함. T1, T2, T3 순서대로 render하는 k를 k1, k2, k3로 명칭함.)
learned parameter w와 k를 얻기위해 다음과 같은 순서로 algorithm이 수행된다.

class separability (C2C)
dataset내의 각 class별 sample들이 얼마나 잘 separate되어있는지를 class separability(C2C)라고 하고, imbalanced classification performance는 class separability의 영향을 받는다.
C2C가 좋으면, classification이 쉬워야하고, misclassification에 따른 error는 더 크게 cost를 설정한다. 반대로, C2C가 나쁜경우에는 error가 덜 penalize되도록 cost를 적게 설정한다.
이를 구현하기위해서 sillouette score가 C2C separability measure로 사용된다.
silhouette score: ranges from -1 to +1. (quantifies how well each data point lies within its own cluster. +1 means the point lies perfectly within its own cluster, 0 means the point lies on the boundary between both clusters, -1 means the point lies perfectly within the opposite cluster)
The sum over all points gives a measure on how tightly formed and separated the clusters are. 클래스 A,B가 있다고 치면, 다음과 같이 score를 계산할 수 있다.
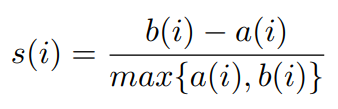
b(i) = minimum d(i,B), where d(i,B)=average dissimilarity of i from class A to all other objects of class B
average of s(i) over all data points = 각각의 class sample들이 얼마나 잘 구분되어 자신들만의 cluster를 형성하고 있는지 알려준다.
class separability(silhouette) score는 S, class imbalance ratio는 IR=max(n+,n-)/min(n+,n-)로 표기해서 H를 adjusted H로 다음과 같이 define할 수 있다.
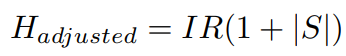
adjusted H를 통해서 minority class의 maximum reachable cost를 해당 class의 separability기반으로 define할 수 있다. binary classification에서 two classes가 well separable하다면, S=1이고 adjusted H=2*IR이 된다. maximum cost가 IR의 두배가 된는것이다.
Results
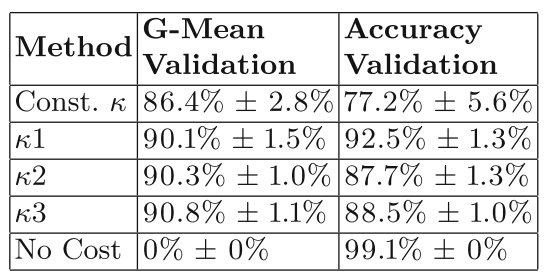
Low C2C separability를 가지고있는 XING imbalanced dataset에 cost sensitive learning을 적용 한 결과, 다음과 같이 different cost sensitive method에 따라 accuracy가 확인되었다. G-Mean의 최적화 방식을 기반으로 k3를 적용한 case에서 가장 높은 accuracy가 확인되었다.
그리고 동일한 XING dataset에 class separability score S를 사용해서 max applicable cost for minorities를 adjust한 결과 분류 performance는 다음과 같다.
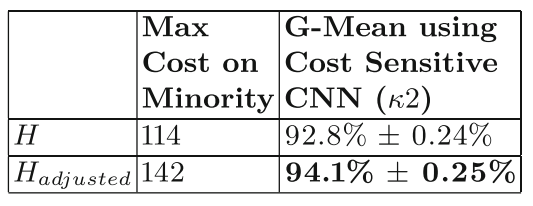
k2 방식에 adjusted H를 적용한 결과 더 높은 분류 G-Mean 값이 확인되었다.
References
- Raj, V.: Towards effective classification of imbalanced data with convolutional neural networks. (2016) Master’s thesis, Department of Informatics, University of Hamburg, Vogt-Koelln-Str. 22527 Hamburg, Germany, April 2016