Resampling technique for imbalanced TSC
The following contents are derived from a paper on imbalanced TSC “Integrated Oversampling for Imbalanced Time Series Classification” by Cao, Hong, et al as cited in the bottom of this post.
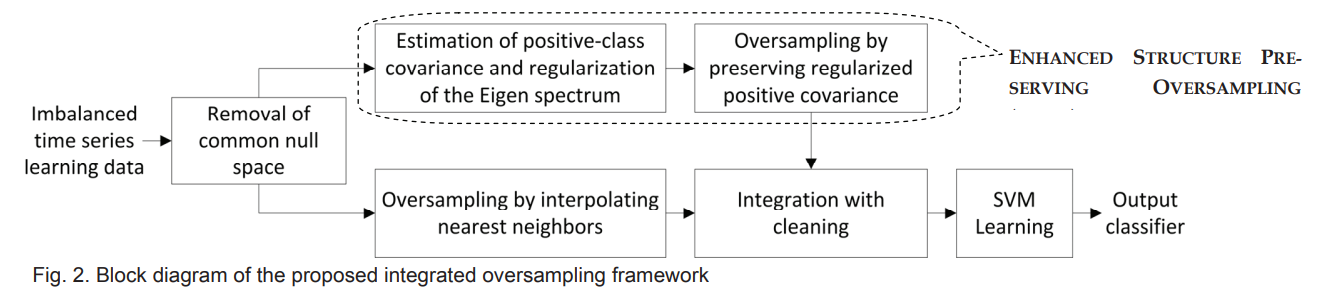
새로운 INOS (Integrated Oversampling)방법으로서 이 논문에서는 interpolation-based oversampling기법과 통합되어 사용되었음. multivariate Gaussian distribution을 기반으로 minority class sample들의 covariance structure를 예상하고 unreliable eigen spectrum을 regularize하는 방식으로 매우 많은 량의 synthetic minority class sample들을 생성할 수 있음. 그리고 minority class에서 핵심 original sample들을 “protect”하기위해 interpolation-based technique를 사용해서 synthetically 생성된 population의 small percentage를 oversample함. 이 ESPO method는 trivial eigen dimensions에서 protective variance를 형성하고 minority sample들의 covariance structure를 보존하는 방식을 통해서 data space내의 void 영역에서 minority sample들을 original sample들에 너무 tight하게 모여있지않고 적절하게 퍼져있도록 배치시킬 수 있음.
이를 통해서 imbalanced time series data classification에 oversampling을 적용한는데에 주로 encounter하는 challenge중 하나인 - maintaining the correlation between consecutive values through preserving the main covariance structure -를 address함.
7개의 public TS datasets와 SVM classifier를 통해서 demonstration을 수행함.
general oversampling methods
data level
algorithm level (enforce emphasis on minority classes by manipulating & incorporating learning parameters)
two approaches
first approach: interpolation 기반의 방식이다. interpolates between selected minority class samples and their random minority nearest neighbors for generating the synthetic samples (e.g, SMOTE, Borderline-SMOTE, ADASYN)
SMOTE: selects all minority samples and evenly generate synthetic samples from each selected seed sample
Borderline-SMOTE: identifies a set of hard and non-outlier minority samples at the class border and evenly generates the synthetic samples from this border set
ADASYN: adaptive approach where number of synthetic samples to be generated for each minority sample is determined by the percentage of majority samples in its neighborhood.
second approach: generates the features of the synthetic samples individually (e.g., DataBoost)
DataBoost: generates each feature value based on Gaussian distribution within an empirical range [min,max]
ESPO (Enhanced Structure Preserving Oversampling)
일반적인 interpolation기반의 approach는 generic imbalanced learning task에는 적절할 수 있지만, highly imbalanced time series datasets에는 적절하지 못하다.
보통 adjacent variables in the time series는 independent하지 않고 매우 높게 correlated되어있음.
일반적인 oversampling approach로는 random data invariance가 형성되어서 original time series data의 inherent correlation structure를 약화시킨다. 이는 분류 학습을 방해하는 generation of non-representative synthetic training samples with excessive noise를 발생시킨다.
이런 이슈를 방지하기위해서 두 가지 objective를 중촉시킨다:
preserve the regularized eign covariance structure which can be estimated using the limited minority time series samples
ESPO(Enhanced Structure Preserving Oversampling)로 transformed signal space에서 oversampling을 수행한다. 다음 과정을 수행함:
generate the synthetic samples by estimating and maintaining the main covariance structure in the reliable eigen subspace
infer and fix the unreliable eigen spectrum (which is insufficiently estimated due to the limited number of minority samples) using a regularization procedure
이 방식을 통해서 trivial eigen subspace에서 synthetic data 의 buffer variances가 생성되어서 data 학습을 통한 generalization(일반화)에 도움이 된다.
be able to provide adequate emphasis on the key minority samples with the remaining oversampling capacity
interpolation-based method를 사용하고 border set of existing samples에 집중하여서 small percentage of synthetic samples를 생성한다. (border set of existing samples에 집중하는것은 critical for building accurate classifiers in the subsequent steps)
Learning framework (binary class time series data)
- remove the common null space by transforming the learning data into the signal space
- perform a large portion of oversampling using ESPO(enhanced structure preserving oversampling)
- estimate the minority class covariance and perform eigen decomposition and spectrum regularization
- conduct oversampling by conforming to regularized covariance structure
그리고 동시에, remaining synthetic samples의 작은 portion은 nearest-neighbor interpolation method를 활용해서 oversampling한다.
Resulting collective synthetic minority class samples는 learning dataset에 통합되어서 class간의 balance를 형성한다. (balanced in terms of number of each class’ samples in the learning dataset)
References
- Cao, Hong, et al: Integrated Oversampling for Imbalanced Time Series Classification (2012)