Forms of imbalanced distribution
Step imbalance
step imbalance는 majority class instances와 minority class instances로 갈리는 class distribution에서 모든 majority, minority class들이 각각 동일한 instance수를 가지고있는 것을 뜻한다. imbalance class distribution을 표현하기위해 다음 두가지 지표가 사용된다.
Fraction of minority class (mu)
fraction of minority class(mu)는 number of minority classes와 total number of classes의 ratio를 의미한다.
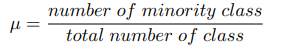
Imbalance ratio (rho)
imbalance ratio(rho)는 majority와 minority class instances수 사이의 ratio를 의미한다.
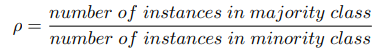
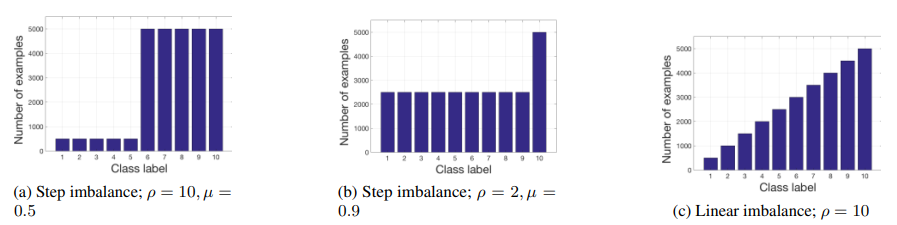
mu와 rho 두 지표를 사용해서 다음 그림의 (a),(b)와 같이 imbalance된 dataset(majority class들은 m개 instances, minority class들은 n개 instances, where m»n)을 histogram으로 표현할 수 있다. (a)의 경우 rho는 5000/500=10이고, (b)의 경우 rho는 5000/2500=2이다.
Linear imbalance
위 그림의 (c)의 경우는 linear imbalance를 의미한다. number of instances of any two classes is not equal and increases gradually over classes. Linear imbalance의 경우 parameter imbalance ratio rho는 모든 class들 중에서 maximum number of instances와 minimum number of instances의 ratio이다. (c)의 경우 rho는 5000/500=10이다.
Class separability
class separability는 data point들이 각각의 class cluster에 얼마나 잘 포함되는지를 알려준다. Binary classification 문제의 경우 positive instance i에 대한 separability score는 다음과 같이 정의한다:
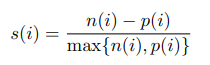
p(i)는 instance i의 average distance from all positive class instances를 의미하고, n(i)는 instance i의 average distance from all negative class instances를 의미한다. Multi-class classification 문제의 경우에는 binarization을 사용해서 적용할수있다. Dataset의 separability score는 모든 instances의 separability score를 average해서 구할 수 있다. Overall separability score는 -1에서 1의 range를 가지고, -1의 경우 완전히 서로 다른 class의 instance들이 같은 cluster에 섞여있는 상태이고, 1의 경우 각 class의 instance들이 동일 class cluster에만 포함되어있는 상태를 의미한다.
Methods
Data level approach
Data level approach는 dataset자체를 modify해서 balanced class distribution을 형성하는 방식이다. 다음과 같이 under/over sampling방식으로 진행된다.
Undersampling
majority class에서부터 sample을 제거하여 class balance를 맞추는 방법이다. 이 방식은 imbalance ratio(rho)가 높은 경우에는 정보를 잃어버리는 위험이 존재한다. 이 ratio가 큰 경우에는 minority class의 sample수가 매우 작아서 정보가 부족한 상태이거나, minority class와 balance를 맞추기위해 majority class에서 너무 큰 information loss가 발생할 수 있기때문이다.
Oversampling
minority class sample들에 artificial instances를 추가하여 minority class samples수를 늘려서 majority class와 balance를 맞추는 방법이다. Interpolation-based 방식으로 SMOTE(Synthetic Minority Over-sampling Technique)가 있고, cluster-based oversampling방식도있다. Dataset을 먼저 clustering한다음, 각각의 cluster내 sample들을 oversampling하는 방식이다. Dataset의 imbalance ratio가 큰 경우에는 많은 량의 artificial instances로 인해 데이터 학습의 결과가 overfit될 확률이 높은 위험이 있다. 또한, 대부분의 artificial instance 생성 방식은 매우 computationally costly하다.
Algorithmic approach
weighted loss in mini-batch
mini-batch에서 loss contribution을 고려할때에 각 클래스의 contribution이 동일하게 고려되도록 loss function을 조정하는 방식이다. mini-batch별 loss function은 다음과 같이 define된다.
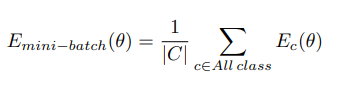
E_c는 class c의 average loss를 의미하고, theta는 이 loss값을 결정짓는 network의 parameter,즉 weights를 의미한다. 각각의 E_c는 다음과 같이 정의된다.
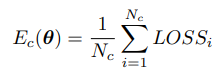
N_c는 class c의 number of instances를 의미하고, LOSS_i는 i번째 instance의 LOSS를 의미한다.
각 instance의 loss를 Keras에서 미리 확보한 inbuilt loss function외에 내가 직접 customize 하려면, loss function을 새로 정의해서 model compile시 호출할 수 있다.
def custom_loss(y_true, y_pred):
#define a customized loss function using y_pred nad y_true
return loss
model.compile(loss=custom_loss, optimizer='adam')
여기서 기억할 점은 3가지가있다
Custom loss function은 y_true, y_pred를 argument로 가져간다. loss를 계산하기위해 필요한 정답 값(y_true)과 예측 값(y_pred)을 model에서부터 pass받아서 fitting과정동안 loss를 계산하는 것이다.
Custom loss function은 y_pred 값을 반드시 활용하여 loss를 계산해야한다. 그렇게하지않으면, gradient expression이 정의될 수 없고 error가 발생한다.
BE CAREFUL with DATA DIMENSIONS. custom loss function에 pass되는 y_true와 y_pred의 first dimension은 batch size와 동일하다. (y_pred.shape(0)==batch_size) 예를 들어서 model을 fitting하려는 data의 batch size가 32이고, model의 output nodes가 5라면 (e.g., classification among 5 different classes), y_pred.shape = (32,5)
그리고, loss function은 언제나 결론적으로 batch_size와 동일한 length를 가진 vector를 return해야한다. 각각의 data point의 loss 값을 return해야 하기 때문이다. 예를 들어서 batch size=32라면, custom loss function의 return값은 a vector of length 32이여야 한다.
Given a neural network as regression model with output vector of length 2, e.g., [x1, x2], 만약 x2를 잘못 예측하는 결과에 더 큰 penalty를 부여하고 싶다면, 다음과 같이 x2의 prediction error에는 0.7을, x1의 prediction error에는 0.3의 weights를 부여하는 custom_mse 함수를 다음과 같이 정의할 수 있다.
model = keras.models.Sequential()
model.add(Dense(50, input_shape=(5,), activation='relu'))
model.add(Dense(20, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(2, activation='linear'))
# define custom loss function
import keras.backend as K
def custom_mse(y_true, y_pred):
# calculating squared difference between target and predicted values
loss = K.square(y_pred - y_true) # (batch_size, 2)
# multiplying the values with weights along batch dimension
loss = loss * [0.3, 0.7] # (batch_size, 2)
# summing both loss values along batch dimension
loss = K.sum(loss, axis=1) # (batch_size,)
return loss
model.compile(loss=custom_mse, optimizer='adam')
Bootstrapping approach
훈련동안 mini-batch를 구성할때에 majority와 minority 클래스의 balance를 맞추는 방법이다. dataset에서 n,m이 majority와 minority 클래스 사이즈를 표현한다면 (n»m), 모든 클래스를 적절하게 표현할 수 있는 batch size s를 선택해야한다. Majority class에서 추출되는 batch size는 s_n, minority class에서 추출되는 batch size는 s_p를 의미한다면, total number of batch per epoch N은 n/s_n이다. (s_n으로 n이 나누어 떨어지지 않아도 n»m의 imbalance 상태에서는 negative 클래스 샘플이 몇개 lost되어도 이는 충분히 감수할 수 있는 정도라고 판단함.) s_n과 s_p를 동등한 수준으로 설정해서 mini-batch내에서 클래스간의 balance를 맞춘다.
각각의 batch를 구성할때에, majority 클래스에서는 하나의 sample은 최대 한번만 선택될 수 있고, minority 클래스에서는 하나의 sample random하게 여러번 선택될 수 있다. (All the samples in the minority class have an equal probability of being chosen in each mini-batch.) 이런 randomness를 기반으로 majority 클래스의 각각의 샘플이 동등한 확률로 다른 minority 클래스의 샘플과 훈련을 진행해서 overfitting을 방지한다.
이 방식은 다음과 같은 flow로 진행된다:

References
- Jamil, S. R. : Time Series Classification using Convolutional Neural Network on Imbalanced Datasets (2021)
How to Create a Custom Loss Function Keras by Shiva Verma https://towardsdatascience.com/how-to-create-a-custom-loss-function-keras-3a89156ec69b